Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Architetture di riferimento per Apache Iceberg su AWS
Questa sezione fornisce esempi di come applicare le migliori pratiche in diversi casi d'uso, come l'ingestione in batch e un data lake che combina l'ingestione di dati in batch e in streaming.
Inserimento notturno in batch
In questo caso d'uso ipotetico, supponiamo che la tabella Iceberg inserisca le transazioni con carta di credito su base notturna. Ogni batch contiene solo aggiornamenti incrementali, che devono essere uniti nella tabella di destinazione. Più volte all'anno, vengono ricevuti dati storici completi. Per questo scenario, consigliamo l'architettura e le configurazioni seguenti.
Nota: questo è solo un esempio. La configurazione ottimale dipende dai dati e dai requisiti.
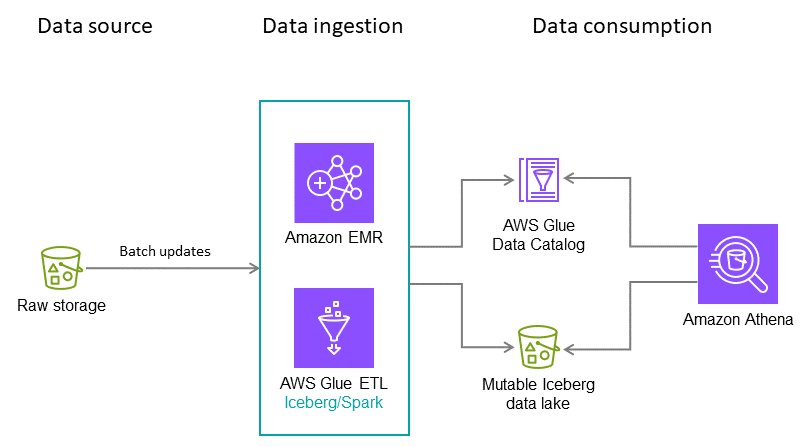
Raccomandazioni:
-
Dimensione del file: 128 MB, poiché le attività di Apache Spark elaborano i dati in blocchi da 128 MB.
-
Tipo di scrittura:. copy-on-write Come dettagliato in precedenza in questa guida, questo approccio aiuta a garantire che i dati vengano scritti in modo ottimizzato per la lettura.
-
Variabili di partizione: anno/mese/giorno. Nel nostro caso d'uso ipotetico, interroghiamo i dati recenti più frequentemente, anche se occasionalmente eseguiamo scansioni complete delle tabelle per gli ultimi due anni di dati. L'obiettivo del partizionamento è quello di velocizzare le operazioni di lettura in base ai requisiti del caso d'uso.
-
Ordinamento: timestamp
-
Catalogo dati: AWS Glue Data Catalog
Data lake che combina ingestione in batch e quasi in tempo reale
Puoi fornire un data lake su Amazon S3 che condivide dati in batch e in streaming tra account e regioni. Per un diagramma di architettura e dettagli, consulta il post del AWS blog Crea un data lake transazionale usando Apache Iceberg e le condivisioni di dati tra account utilizzando
