Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Motivo a fico Strangler
Intento
Lo strangler fig pattern aiuta a migrare un'applicazione monolitica verso un'architettura di microservizi in modo incrementale, con minori rischi di trasformazione e interruzioni aziendali.
Motivazione
Le applicazioni monolitiche sono sviluppate per fornire la maggior parte delle loro funzionalità all'interno di un singolo processo o contenitore. Il codice è strettamente collegato. Di conseguenza, le modifiche alle applicazioni richiedono un nuovo test approfondito per evitare problemi di regressione. Le modifiche non possono essere testate isolatamente, il che influisce sulla durata del ciclo. Poiché l'applicazione è arricchita da più funzionalità, un'elevata complessità può comportare un aumento del tempo dedicato alla manutenzione, un aumento del time-to-market e, di conseguenza, una lenta innovazione del prodotto.
Quando le dimensioni dell'applicazione sono scalabili, aumenta il carico cognitivo del team e può causare confini poco chiari sulla proprietà del team. Non è possibile scalare le singole funzionalità in base al carico: l'intera applicazione deve essere ridimensionata per supportare i picchi di carico. Con l'invecchiamento dei sistemi, la tecnologia può diventare obsoleta, il che fa aumentare i costi di supporto. Le applicazioni monolitiche e preesistenti seguono le best practice disponibili al momento dello sviluppo e non progettate per essere distribuite.
Quando un'applicazione monolitica viene migrata in un'architettura di microservizi, può essere suddivisa in componenti più piccoli. Questi componenti possono essere scalati in modo indipendente, possono essere rilasciati indipendentemente e possono essere di proprietà di singoli team. Ciò si traduce in una maggiore velocità di cambiamento, poiché le modifiche sono localizzate e possono essere testate e rilasciate rapidamente. Le modifiche hanno un ambito di impatto minore perché i componenti sono accoppiati in modo flessibile e possono essere implementati singolarmente.
Sostituire completamente un monolite con un'applicazione di microservizi riscrivendo o rifattorizzando il codice è un'impresa enorme e un grosso rischio. Una migrazione di grande portata, in cui il monolite viene migrato in un'unica operazione, comporta rischi di trasformazione e interruzione delle attività aziendali. Durante il refactoring dell'applicazione, è estremamente difficile o addirittura impossibile aggiungere nuove funzionalità.
Un modo per risolvere questo problema è utilizzare lo Strangler Fig Pattern, introdotto da Martin Fowler. Questo modello prevede il passaggio ai microservizi mediante l'estrazione graduale delle funzionalità e la creazione di una nuova applicazione attorno al sistema esistente. Le funzionalità del monolite vengono gradualmente sostituite dai microservizi e gli utenti delle applicazioni sono in grado di utilizzare progressivamente le nuove funzionalità migrate. Quando tutte le funzionalità vengono trasferite nel nuovo sistema, l'applicazione monolitica può essere disattivata in sicurezza.
Applicabilità
Usa lo schema Strangler Fig quando:
-
Desiderate migrare gradualmente la vostra applicazione monolitica verso un'architettura di microservizi.
-
Un approccio di migrazione basato sul big bang è rischioso a causa delle dimensioni e della complessità del monolite.
-
L'azienda desidera aggiungere nuove funzionalità e non vede l'ora che la trasformazione sia completa.
-
Gli utenti finali devono subire un impatto minimo durante la trasformazione.
Problemi e considerazioni
-
Accesso alla base di codice: per implementare il pattern strangler fig, è necessario avere accesso alla base di codice dell'applicazione monolith. Man mano che le funzionalità vengono migrate fuori dal monolite, sarà necessario apportare piccole modifiche al codice e implementare un livello anticorruzione all'interno del monolite per indirizzare le chiamate verso nuovi microservizi. Non è possibile intercettare le chiamate senza l'accesso al codice base. L'accesso alla base di codice è fondamentale anche per reindirizzare le richieste in entrata: potrebbe essere necessario rifattorizzare il codice in modo che il livello proxy possa intercettare le chiamate alle funzionalità migrate e indirizzarle verso i microservizi.
-
Dominio poco chiaro: la scomposizione prematura dei sistemi può essere costosa, soprattutto quando il dominio non è chiaro ed è possibile che i limiti del servizio siano errati. La progettazione basata sul dominio (DDD) è un meccanismo per comprendere il dominio e l'event storming è una tecnica per determinare i confini del dominio.
-
Identificazione dei microservizi: è possibile utilizzare DDD come strumento chiave per identificare i microservizi. Per identificare i microservizi, cerca le divisioni naturali tra le classi di servizio. Molti servizi avranno il proprio oggetto di accesso ai dati e si disaccoppieranno facilmente. I servizi che hanno una logica aziendale correlata e classi che non hanno alcuna dipendenza o hanno poche dipendenze sono buoni candidati per i microservizi. È possibile rifattorizzare il codice prima di scomporre il monolite per evitare un accoppiamento stretto. Dovresti inoltre considerare i requisiti di conformità, la cadenza di rilascio, la posizione geografica dei team, le esigenze di scalabilità, le esigenze tecnologiche basate sui casi d'uso e il carico cognitivo dei team.
-
Livello anticorruzione: durante il processo di migrazione, quando le funzionalità all'interno del monolite devono richiamare le funzionalità che sono state migrate come microservizi, è necessario implementare un livello anticorruzione (ACL) che indirizzi ogni chiamata al microservizio appropriato. Per disaccoppiare e impedire la modifica dei chiamanti esistenti all'interno del monolite, l'ACL funge da adattatore o da facciata che converte le chiamate nella nuova interfaccia. Questo è discusso in dettaglio nella sezione Implementazione del modello ACL riportata in precedenza in questa guida.
-
Errore a livello proxy: durante la migrazione, un livello proxy intercetta le richieste che arrivano all'applicazione monolitica e le indirizza al sistema legacy o al nuovo sistema. Tuttavia, questo livello proxy può diventare un singolo punto di errore o un ostacolo alle prestazioni.
-
Complessità dell'applicazione: i monoliti di grandi dimensioni traggono il massimo vantaggio dal pattern Strangler Fig. Per le applicazioni di piccole dimensioni, in cui la complessità del refactoring completo è bassa, potrebbe essere più efficiente riscrivere l'applicazione in un'architettura di microservizi anziché migrarla.
-
Interazioni di servizio: i microservizi possono comunicare in modo sincrono o asincrono. Quando è richiesta una comunicazione sincrona, valuta se i timeout possono causare il consumo della connessione o del pool di thread, con conseguenti problemi di prestazioni delle applicazioni. In questi casi, utilizzate lo schema degli interruttori automatici per restituire un guasto immediato in caso di operazioni che rischiano di fallire per lunghi periodi di tempo. La comunicazione asincrona può essere ottenuta utilizzando eventi e code di messaggistica.
-
Aggregazione dei dati: in un'architettura di microservizi, i dati vengono distribuiti tra database. Quando è richiesta l'aggregazione dei dati, è possibile utilizzare AWS AppSync
nel front-end o il pattern CQRS (Command Query Responsibility Segregation) nel backend. -
Coerenza dei dati: i microservizi possiedono il proprio archivio dati e anche l'applicazione monolitica può potenzialmente utilizzare questi dati. Per abilitare la condivisione, è possibile sincronizzare l'archivio dati dei nuovi microservizi con il database dell'applicazione monolitica utilizzando una coda e un agente. Tuttavia, ciò può causare la ridondanza dei dati e l'eventuale coerenza tra due archivi di dati, quindi consigliamo di considerarla una soluzione tattica fino a quando non sarà possibile stabilire una soluzione a lungo termine come un data lake.
Implementazione
Nel modello Strangler Fig, si sostituiscono funzionalità specifiche con un nuovo servizio o applicazione, un componente alla volta. Un livello proxy intercetta le richieste che arrivano all'applicazione monolitica e le indirizza al sistema precedente o al nuovo sistema. Poiché il livello proxy indirizza gli utenti all'applicazione corretta, è possibile aggiungere funzionalità al nuovo sistema assicurando al contempo che il monolite continui a funzionare. Il nuovo sistema alla fine sostituisce tutte le funzionalità del vecchio sistema ed è possibile disattivarlo.
Architettura di alto livello
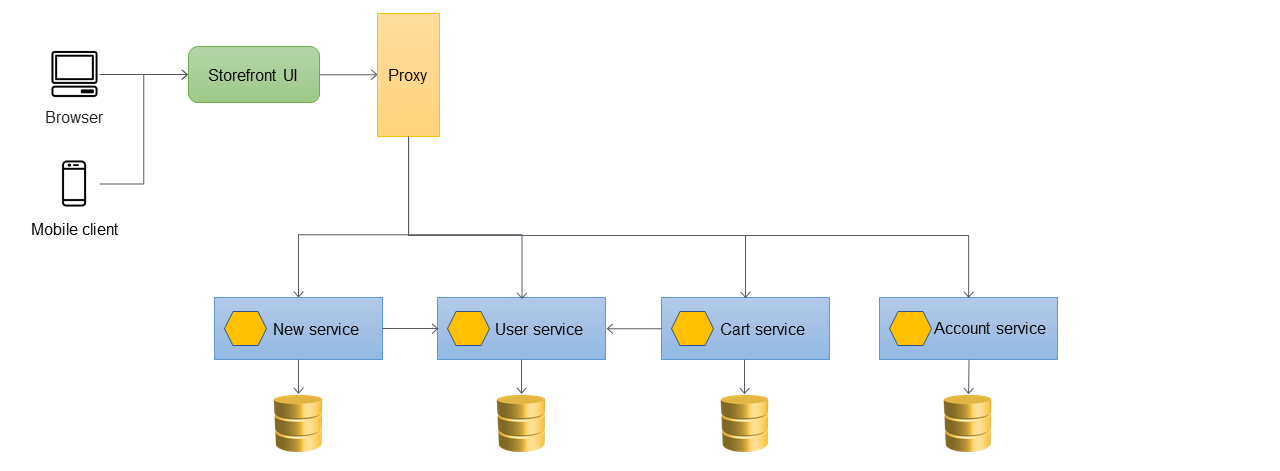
Nel diagramma seguente, un'applicazione monolitica dispone di tre servizi: servizio utente, servizio carrello e servizio account. Il servizio cart dipende dal servizio utente e l'applicazione utilizza un database relazionale monolitico.
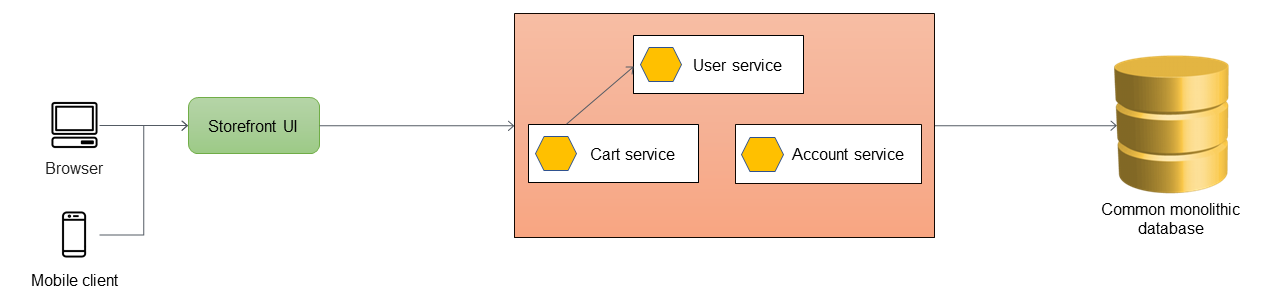
Il primo passaggio consiste nell'aggiungere un livello proxy tra l'interfaccia utente dello storefront e l'applicazione monolitica. All'inizio, il proxy indirizza tutto il traffico verso l'applicazione monolitica.

Quando desideri aggiungere nuove funzionalità alla tua applicazione, le implementi come nuovi microservizi invece di aggiungere funzionalità al monolite esistente. Tuttavia, continuate a correggere i bug nel monolite per garantire la stabilità dell'applicazione. Nel diagramma seguente, il livello proxy indirizza le chiamate al monolite o al nuovo microservizio in base all'URL dell'API.

Aggiungere un livello anticorruzione
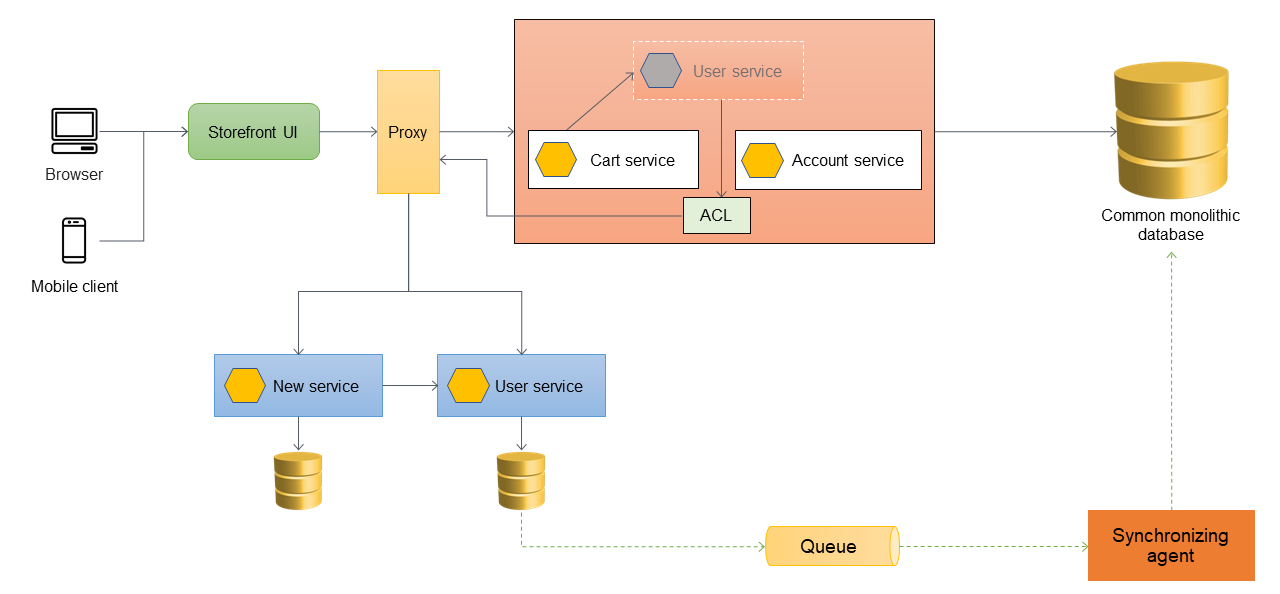
Nella seguente architettura, il servizio utente è stato migrato a un microservizio. Il servizio cart richiama il servizio utente, ma l'implementazione non è più disponibile all'interno del monolite. Inoltre, l'interfaccia del servizio appena migrato potrebbe non corrispondere all'interfaccia precedente all'interno dell'applicazione monolitica. Per risolvere queste modifiche, è necessario implementare un ACL. Durante il processo di migrazione, quando le funzionalità all'interno del monolite devono richiamare le funzionalità che sono state migrate come microservizi, l'ACL converte le chiamate nella nuova interfaccia e le indirizza al microservizio appropriato.

È possibile implementare l'ACL all'interno dell'applicazione monolitica come classe specifica per il servizio che è stato migrato; ad esempio, o. UserServiceFacade UserServiceAdapter L'ACL deve essere disattivato dopo che tutti i servizi dipendenti sono stati migrati nell'architettura dei microservizi.
Quando si utilizza l'ACL, il servizio cart chiama ancora il servizio utente all'interno del monolite e il servizio utente reindirizza la chiamata al microservizio tramite l'ACL. Il servizio cart dovrebbe comunque chiamare il servizio utente senza essere a conoscenza della migrazione dei microservizi. Questo accoppiamento libero è necessario per ridurre la regressione e le interruzioni dell'attività.
Gestione della sincronizzazione dei dati
Come best practice, il microservizio dovrebbe essere proprietario dei propri dati. Il servizio utente archivia i propri dati nel proprio archivio dati. Potrebbe essere necessario sincronizzare i dati con il database monolitico per gestire dipendenze come la reportistica e supportare applicazioni downstream che non sono ancora pronte per accedere direttamente ai microservizi. L'applicazione monolitica potrebbe inoltre richiedere i dati per altre funzioni e componenti che non sono ancora stati migrati ai microservizi. È quindi necessaria la sincronizzazione dei dati tra il nuovo microservizio e il monolite. Per sincronizzare i dati, è possibile introdurre un agente di sincronizzazione tra il microservizio utente e il database monolitico, come illustrato nel diagramma seguente. Il microservizio utente invia un evento alla coda ogni volta che il relativo database viene aggiornato. L'agente di sincronizzazione ascolta la coda e aggiorna continuamente il database monolitico. I dati nel database monolitico alla fine sono coerenti con i dati che vengono sincronizzati.
Migrazione di servizi aggiuntivi
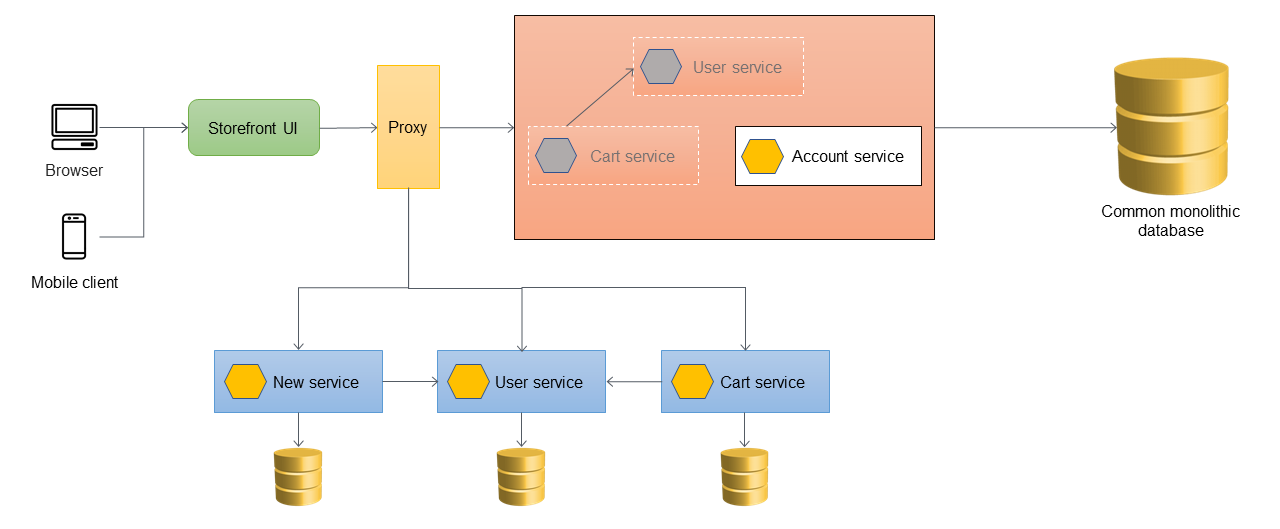
Quando il servizio cart viene migrato dall'applicazione monolitica, il relativo codice viene modificato per richiamare direttamente il nuovo servizio, in modo che l'ACL non instrada più tali chiamate. Il diagramma seguente illustra tale architettura.
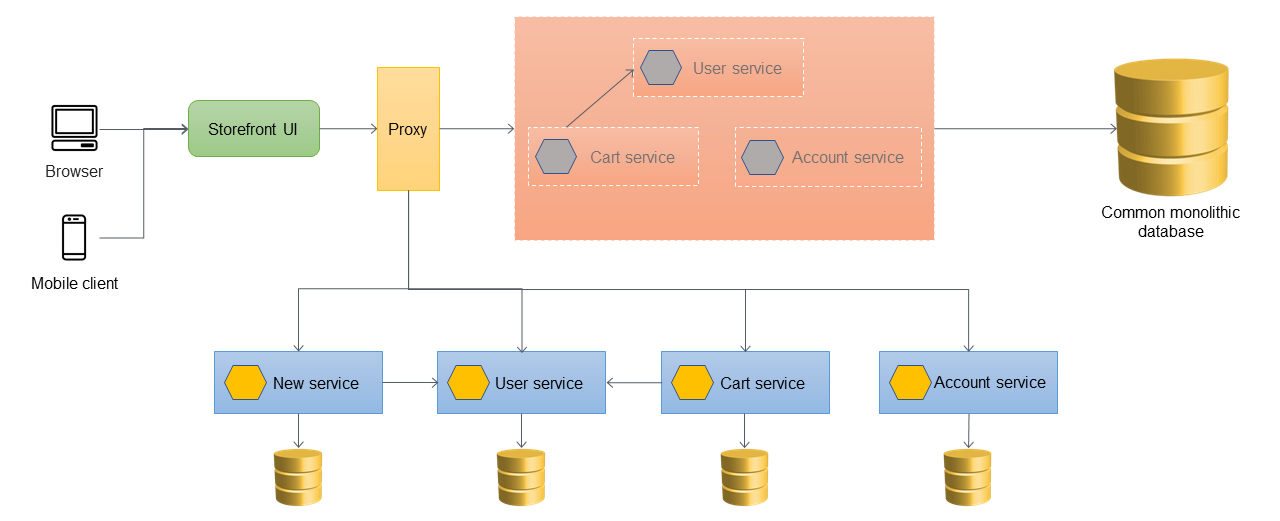
Il diagramma seguente mostra lo stato di strangolamento finale in cui tutti i servizi sono stati migrati dal monolite e rimane solo lo scheletro del monolite. I dati storici possono essere migrati in archivi dati di proprietà di singoli servizi. L'ACL può essere rimosso e il monolite è pronto per essere smantellato in questa fase.
Il diagramma seguente mostra l'architettura finale dopo la disattivazione dell'applicazione monolitica. È possibile ospitare i singoli microservizi tramite un URL basato sulle risorse (ad esempiohttp://www.storefront.com/user) o tramite il proprio dominio (ad esempio) in base ai requisiti dell'applicazione. http://user.storefront.com Per ulteriori informazioni sui principali metodi per esporre HTTP APIs ai consumatori upstream utilizzando nomi host e percorsi, consulta la sezione sui modelli di routing delle API.
Implementazione tramite servizi AWS
Utilizzo di API Gateway come proxy dell'applicazione
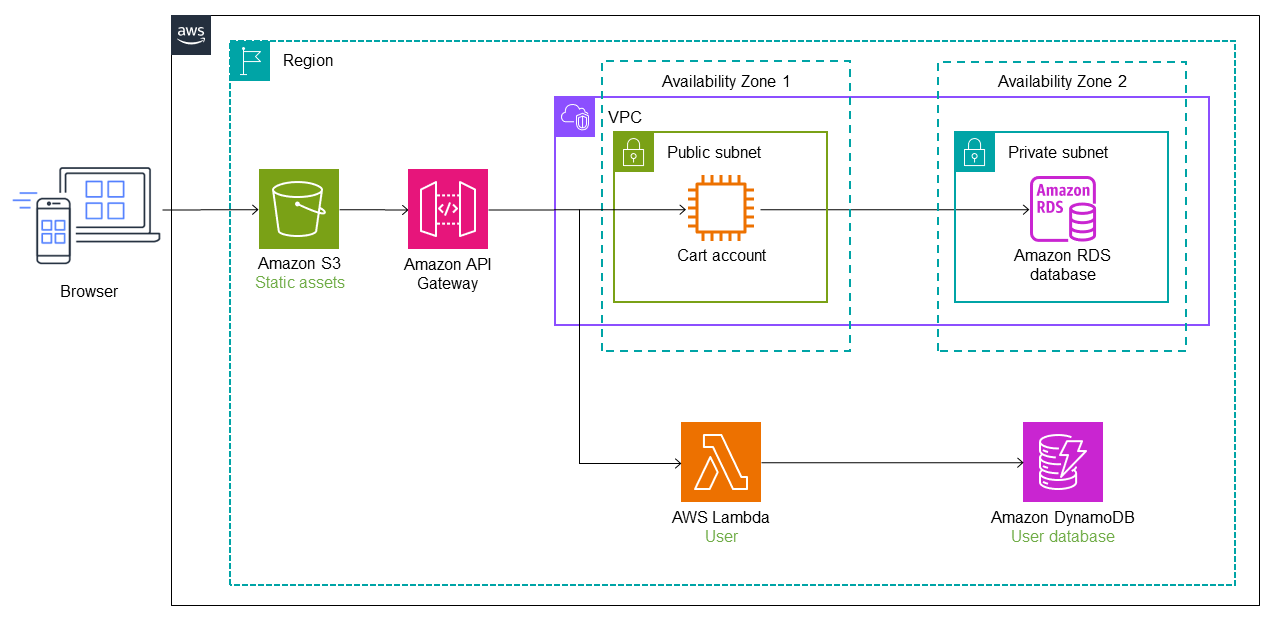
Il diagramma seguente mostra lo stato iniziale dell'applicazione monolitica. Supponiamo che sia stata effettuata la migrazione AWS utilizzando una lift-and-shift strategia, quindi è in esecuzione su un'istanza Amazon Elastic Compute Cloud (Amazon EC2)

Nella seguente architettura, AWS Migration Hub Refactor Spacesdistribuisce Amazon API Gateway

Il servizio utente viene migrato in una funzione Lambda e un database Amazon DynamoDB
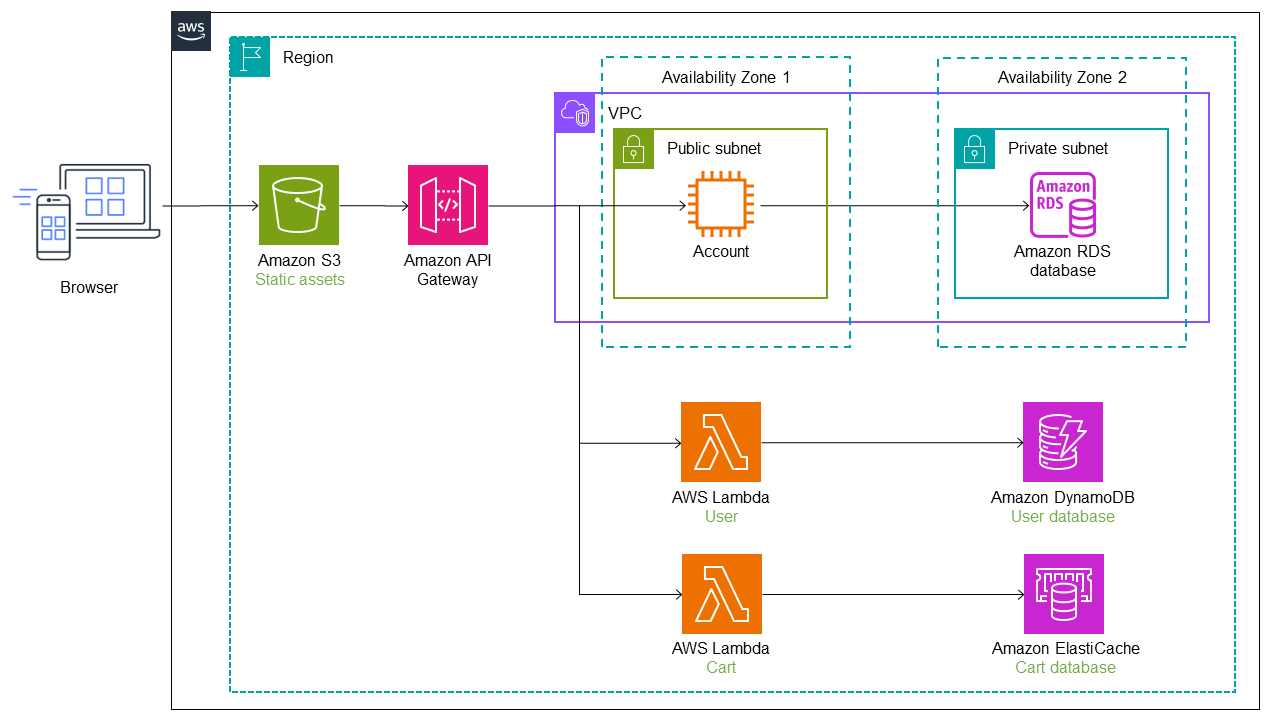
Nel diagramma seguente, anche il servizio cart è stato migrato dal monolite a una funzione Lambda. Un ulteriore endpoint di percorso e servizio viene aggiunto a Refactor Spaces e il traffico passa automaticamente alla funzione LambdaCart. L'archivio dati per la funzione Lambda è gestito da Amazon. ElastiCache
Nel diagramma seguente, l'ultimo servizio (account) viene migrato dal monolite a una funzione Lambda. Continua a utilizzare il database Amazon RDS originale. La nuova architettura ora dispone di tre microservizi con database separati. Ogni servizio utilizza un tipo diverso di database. Questo concetto di utilizzo di database creati appositamente per soddisfare le esigenze specifiche dei microservizi si chiama persistenza poliglotta. Le funzioni Lambda possono essere implementate anche in diversi linguaggi di programmazione, a seconda del caso d'uso. Durante il refactoring, Refactor Spaces automatizza il cutover e l'instradamento del traffico verso Lambda. Ciò consente ai costruttori di risparmiare il tempo necessario per progettare, implementare e configurare l'infrastruttura di routing.

Utilizzo di più account
Nell'implementazione precedente, utilizzavamo un singolo VPC con una sottorete privata e una pubblica per l'applicazione monolitica e implementavamo i microservizi all'interno della stessa per motivi di semplicità. Account AWS Tuttavia, ciò si verifica raramente negli scenari del mondo reale, in cui i microservizi vengono spesso distribuiti in più formati per garantire l'indipendenza dall'implementazione. Account AWS In una struttura con più account, è necessario configurare il routing del traffico dal monolite ai nuovi servizi in diversi account.
Refactor Spaces ti aiuta a creare e configurare l' AWS infrastruttura per il routing delle chiamate API lontano dall'applicazione monolitica. Refactor Spaces orchestra API Gateway
Supponiamo che i servizi user e cart siano distribuiti su due account diversi, come illustrato nel diagramma seguente. Quando utilizzi Refactor Spaces, devi solo configurare l'endpoint del servizio e il percorso. Refactor Spaces automatizza l'integrazione API Gateway-Lambda e la creazione di policy sulle risorse Lambda, in modo che tu possa concentrarti sul refactoring sicuro dei servizi fuori dal monolite.

Per un video tutorial sull'utilizzo di Refactor Spaces, vedi Refactor Apps
Workshop
Riferimenti del blog
Contenuti correlati
