Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creazione di pipeline ML pronte per la produzione su AWS
Josiah Davis, Verdi March, Yin Song, Baichuan Sun, Chen Wu e Wei Yih Yap, Amazon Web Services ()AWS
Gennaio 2021 (cronologia dei documenti)
I progetti di machine learning (ML) richiedono un impegno significativo in più fasi che include la modellazione, l'implementazione e la produzione per fornire valore aziendale e risolvere problemi del mondo reale. In ogni fase sono disponibili numerose alternative e opzioni di personalizzazione, che rendono sempre più difficile preparare un modello di machine learning per la produzione entro i limiti delle risorse e del budget. Negli ultimi anni, in Amazon Web Services (AWS), il nostro team di Data Science ha lavorato con diversi settori industriali su iniziative di machine learning. Abbiamo identificato i punti deboli condivisi da molti AWS clienti, che derivano sia da problemi organizzativi che da sfide tecniche, e abbiamo sviluppato un approccio ottimale per fornire soluzioni ML pronte per la produzione.
Questa guida è destinata ai data scientist e agli ingegneri ML coinvolti nelle implementazioni di pipeline ML. Descrive il nostro approccio per fornire pipeline ML pronte per la produzione. La guida illustra come passare dall'esecuzione interattiva dei modelli ML (durante lo sviluppo) alla loro implementazione come parte di una pipeline (durante la produzione) per i casi d'uso del machine learning. A tal fine, abbiamo anche sviluppato una serie di modelli di esempio (vedi il progetto del progetto ML Max
Panoramica
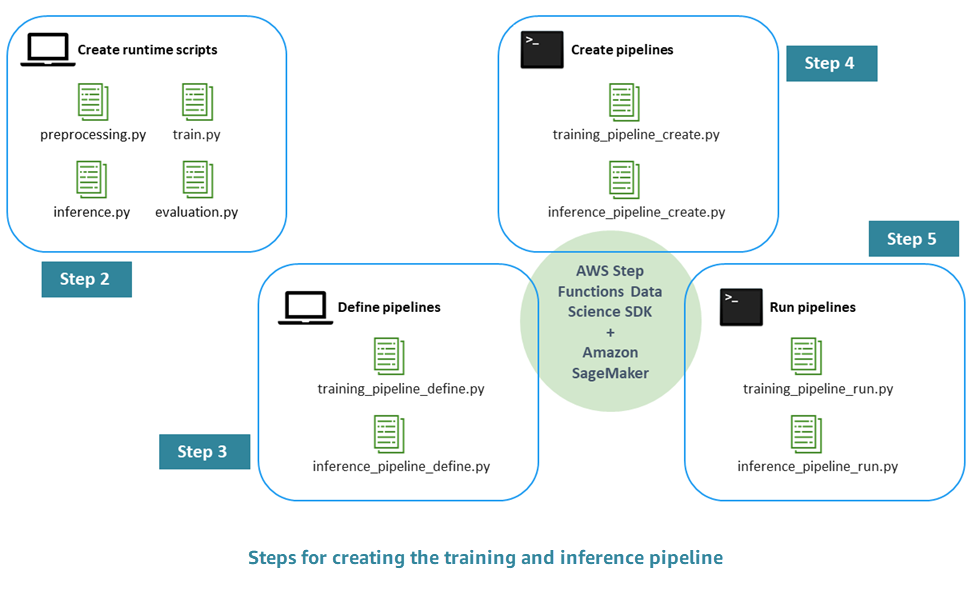
Il processo per creare una pipeline ML pronta per la produzione prevede i seguenti passaggi:
-
Fase 1. Esegui EDA e sviluppa il modello iniziale: i data scientist rendono disponibili i dati grezzi in Amazon Simple Storage Service (Amazon S3), eseguono analisi esplorative dei dati (EDA), sviluppano il modello ML iniziale e ne valutano le prestazioni di inferenza. Puoi condurre queste attività in modo interattivo tramite i notebook Jupyter.
-
Fase 2. Crea gli script di runtime: integri il modello con gli script Python di runtime in modo che possa essere gestito e fornito da un framework ML (nel nostro caso, Amazon AI). SageMaker Questo è il primo passo per passare dallo sviluppo interattivo di un modello autonomo alla produzione. In particolare, si definisce separatamente la logica per la preelaborazione, la valutazione, l'addestramento e l'inferenza.
-
Fase 3. Definizione della tubazione: definisci i segnaposto di input e output per ogni fase della pipeline. I relativi valori concreti verranno forniti in seguito, durante l'esecuzione (fase 5). Ti concentri sulle pipeline per la formazione, l'inferenza, la convalida incrociata e il backtest.
-
Fase 4. Creazione della pipeline: crei l'infrastruttura sottostante, inclusa l'istanza della macchina a AWS Step Functions stati, in modo automatizzato (quasi con un clic), utilizzando. AWS CloudFormation
-
Fase 5. Esegui la pipeline: esegui la pipeline definita nel passaggio 4. Preparate anche i metadati e i dati o le posizioni dei dati per inserire valori concreti per i segnaposto di input/output definiti nel passaggio 3. Ciò include gli script di runtime definiti nel passaggio 2 e gli iperparametri del modello.
-
Fase 6. Espandi la pipeline: implementerai processi di integrazione continua e distribuzione continua (CI/CD), riqualificazione automatizzata, inferenza programmata ed estensioni simili della pipeline.
Il diagramma seguente illustra le fasi principali di questo processo.