Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Best practice
Ti consigliamo di seguire le migliori pratiche tecniche e di archiviazione. Queste best practice possono aiutarti a ottenere il massimo dalla tua architettura incentrata sui dati.
Le migliori pratiche di archiviazione per i big data
La tabella seguente descrive una best practice comune per archiviare file per un carico di elaborazione di big data su Amazon S3. L'ultima colonna è un esempio di politica del ciclo di vita che puoi impostare. Se Amazon S3 Intelligent-Tiering
Nome del livello di dati | Descrizione | Esempio di strategia politica del ciclo di vita |
Raw | Contiene dati grezzi e non elaborati Nota: per un'origine dati esterna, il livello di dati grezzi è in genere una copia 1:1 dei dati, ma su AWS i dati possono essere partizionati per chiavi in base alla regione o alla data AWS durante il processo di ingestione. | Dopo un anno, sposta i file nella classe di storage S3 Standard-IA. Dopo due anni in S3 Standard-IA, archivia i file in Amazon Simple Storage Service Glacier (Amazon S3 Glacier). |
Stage | Contiene dati elaborati intermedi ottimizzati per il consumo Esempio: file raw convertiti o trasformazioni di dati da CSV ad Apache Parquet | È possibile eliminare i dati dopo un periodo di tempo definito o in base ai requisiti dell'organizzazione. È possibile rimuovere alcuni dati derivati (ad esempio, una trasformazione Apache Avro di un formato JSON originale) dal data lake dopo un periodo di tempo più breve (ad esempio, dopo 90 giorni). |
Analisi | Contiene i dati aggregati per i casi d'uso specifici in un formato pronto per il consumo Esempio: Apache Parquet | Puoi spostare i dati in S3 Standard-IA e quindi eliminarli dopo un periodo di tempo definito o in base ai requisiti dell'organizzazione. |
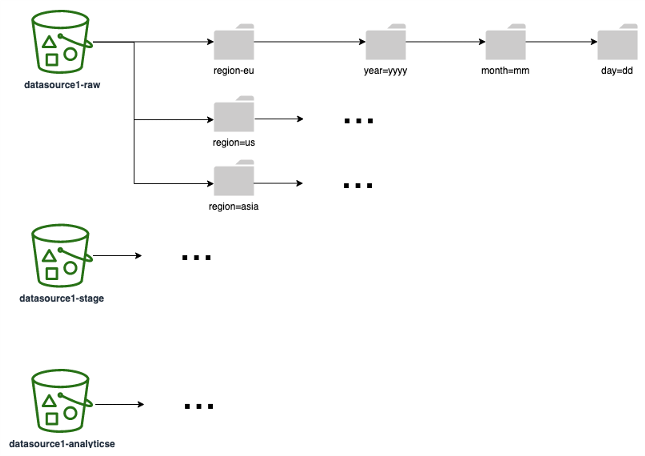
Il diagramma seguente mostra un esempio di strategia di partizionamento (corrispondente a una cartella/prefisso S3) che puoi utilizzare su tutti i livelli di dati. Ti consigliamo di scegliere una strategia di partizionamento basata su come i dati vengono utilizzati a valle. Ad esempio, se i report sono basati sui dati (in cui le query più comuni sul rapporto filtrano i risultati in base all'area e alle date), assicurati di includere le aree e le date come partizioni per migliorare le prestazioni e il tempo di esecuzione delle query.
Migliori pratiche tecniche
Le best practice tecniche dipendono dai servizi AWS e dalle tecnologie di elaborazione specifici utilizzati per progettare un'architettura incentrata sui dati. Tuttavia, ti consigliamo di tenere a mente le seguenti best practice. Queste best practice si applicano ai casi d'uso tipici dell'elaborazione dei dati.
Area | Best practice |
SQL | Riduci la quantità di dati che devono essere interrogati proiettando gli attributi sui dati. Invece di analizzare l'intera tabella, è possibile utilizzare la proiezione dei dati per scansionare e restituire solo alcune colonne obbligatorie della tabella. Se possibile, evita i join di grandi dimensioni, poiché i join tra più tabelle possono influire in modo significativo sulle prestazioni a causa delle loro esigenze che richiedono molte risorse. |
Apache Spark | Ottimizza le applicazioni Spark Ottimizza la gestione della memoria |
Progettazione di database | Segui le best practice di architettura per i database |
Potatura dei dati | Utilizza l'eliminazione delle partizioni lato server con. |
Dimensionamento |
