Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Crea un'architettura serverless multi-tenant in Amazon Service OpenSearch
Creato da Tabby Ward () e Nisha Gambhir () AWS AWS
Riepilogo
Amazon OpenSearch Service è un servizio gestito che semplifica l'implementazione, il funzionamento e la scalabilità di Elasticsearch, un popolare motore di ricerca e analisi open source. Amazon OpenSearch Service offre la ricerca a testo libero, nonché l'inserimento e la creazione di dashboard quasi in tempo reale per lo streaming di dati come log e metriche.
I fornitori di software as a service (SaaS) utilizzano spesso Amazon OpenSearch Service per affrontare un'ampia gamma di casi d'uso, ad esempio per ottenere informazioni sui clienti in modo scalabile e sicuro, riducendo al contempo la complessità e i tempi di inattività.
L'utilizzo di Amazon OpenSearch Service in un ambiente multi-tenant introduce una serie di considerazioni che influiscono sul partizionamento, l'isolamento, l'implementazione e la gestione della soluzione SaaS. I provider SaaS devono considerare come scalare efficacemente i propri cluster Elasticsearch con carichi di lavoro in continuo cambiamento. Devono inoltre considerare in che modo la suddivisione in più livelli e le condizioni rumorose dei vicini potrebbero influire sul loro modello di partizionamento.
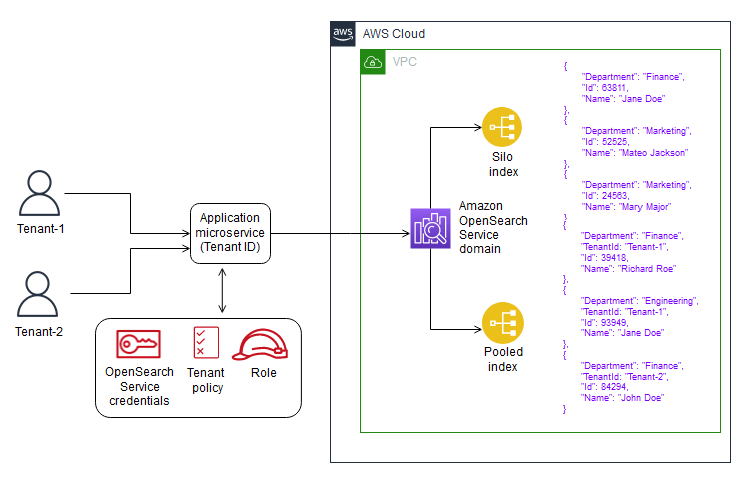
Questo modello esamina i modelli utilizzati per rappresentare e isolare i dati dei tenant con costrutti Elasticsearch. Inoltre, il modello si concentra su una semplice architettura di riferimento serverless come esempio per dimostrare l'indicizzazione e la ricerca utilizzando Amazon OpenSearch Service in un ambiente multi-tenant. Implementa il modello di partizionamento dei dati del pool, che condivide lo stesso indice tra tutti i tenant mantenendo l'isolamento dei dati del tenant. Questo modello utilizza i seguenti servizi Amazon Web Services (AWS): Amazon API Gateway, AWS Lambda, Amazon Simple Storage Service (Amazon S3) e Amazon Service. OpenSearch
Prerequisiti e limitazioni
Prerequisiti
Un account attivo AWS
AWSCommand Line Interface (AWSCLI) versione 2.x, installata e configurata su macOS, Linux o Windows
pip3
— Il codice sorgente di Python viene fornito come file.zip da distribuire in una funzione Lambda. Se desideri utilizzare il codice localmente o personalizzarlo, segui questi passaggi per sviluppare e ricompilare il codice sorgente: Genera il
requirements.txtfile eseguendo il seguente comando nella stessa directory degli script Python:pip3 freeze > requirements.txtInstalla le dipendenze:
pip3 install -r requirements.txt
Limitazioni
Questo codice viene eseguito in Python e attualmente non supporta altri linguaggi di programmazione.
L'applicazione di esempio non include il supporto AWS interregionale o di disaster recovery (DR).
Questo modello è destinato esclusivamente a scopo dimostrativo. Non è destinato all'uso in un ambiente di produzione.
Architettura
Il diagramma seguente illustra l'architettura di alto livello di questo pattern. L'architettura include quanto segue:
AWSLambda per indicizzare e interrogare il contenuto
OpenSearch Servizio Amazon per eseguire ricerche
Amazon API Gateway per fornire un'APIinterazione con l'utente
Amazon S3 per archiviare dati grezzi (non indicizzati)
Amazon CloudWatch per monitorare i log
AWSIdentity and Access Management (IAM) per creare ruoli e politiche degli inquilini

Automazione e scalabilità
Per semplicità, il pattern utilizza AWS CLI il provisioning dell'infrastruttura e la distribuzione del codice di esempio. Puoi creare un AWS CloudFormation modello o degli script AWS Cloud Development Kit (AWSCDK) per automatizzare il pattern.
Strumenti
Servizi AWS
AWSCLI— AWS Command Line Interface (AWSCLI) è uno strumento unificato per la gestione di AWS servizi e risorse utilizzando i comandi nella shell della riga di comando.
AWSLambda
: AWS Lambda è un servizio di elaborazione che consente di eseguire codice senza effettuare il provisioning o la gestione di server. Lambda esegue il codice solo quando è necessario e si dimensiona automaticamente, da poche richieste al giorno a migliaia al secondo. Amazon API Gateway
— Amazon API Gateway è un AWS servizio per la creazione, la pubblicazione, la manutenzione, il monitoraggio e la protezione RESTHTTP, WebSocket APIs su qualsiasi scala. Amazon S3 — Amazon Simple Storage Service (Amazon S3) è un servizio di storage di oggetti che consente di archiviare e recuperare qualsiasi quantità di informazioni in qualsiasi momento, da qualsiasi punto del Web.
Amazon OpenSearch Service
: Amazon OpenSearch Service è un servizio completamente gestito che semplifica l'implementazione, la protezione e l'esecuzione di Elasticsearch su larga scala in modo conveniente.
Codice
L'allegato fornisce file di esempio per questo modello. Ciò include:
index_lambda_package.zip— La funzione Lambda per l'indicizzazione dei dati in Amazon OpenSearch Service utilizzando il modello pool.search_lambda_package.zip— La funzione Lambda per la ricerca di dati in Amazon OpenSearch Service.Tenant-1-data— Esempio di dati grezzi (non indicizzati) per Tenant-1.Tenant-2-data— Esempio di dati grezzi (non indicizzati) per Tenant-2.
Importante
Le storie di questo modello includono esempi di CLI comandi formattati per Unix, Linux e macOS. Per Windows, sostituisci il carattere di continuazione UNIX barra rovesciata (\) al termine di ogni riga con un accento circonflesso (^).
Epiche
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Crea un bucket S3. | Crea un bucket S3 nella tua regione. AWS Questo bucket conterrà i dati del tenant non indicizzati per l'applicazione di esempio. Assicurati che il nome del bucket S3 sia univoco a livello globale, poiché lo spazio dei nomi è condiviso da tutti gli account. AWS Per creare un bucket S3, puoi usare il comando create-bucket come segue: AWS CLI
dov'è il nome del bucket | Architetto del cloud, amministratore del cloud |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Crea un dominio Amazon OpenSearch Service. | Esegui il AWS CLI create-elasticsearch-domain
Il numero di istanze è impostato su 1 perché il dominio è a scopo di test. È necessario abilitare il controllo granulare degli accessi utilizzando il Questo comando crea un nome utente principale ( Poiché il dominio fa parte di un cloud privato virtuale (VPC), devi assicurarti di poter raggiungere l'istanza Elasticsearch specificando la politica di accesso da utilizzare. Per ulteriori informazioni, consulta Launching your Amazon OpenSearch Service domain using a VPC nella AWS documentazione. | Architetto del cloud, amministratore del cloud |
Configura un bastion host. | Configura un'istanza Windows di Amazon Elastic Compute Cloud (AmazonEC2) come host bastion per accedere alla console Kibana. Il gruppo di sicurezza Elasticsearch deve consentire il traffico proveniente dal gruppo di EC2 sicurezza Amazon. Per istruzioni, consulta il post sul blog Controllare l'accesso alla rete alle EC2 istanze utilizzando un Quando il bastion host è stato configurato e hai a disposizione il gruppo di sicurezza associato all'istanza, usa il AWS CLI authorize-security-group-ingress
| Architetto del cloud, amministratore del cloud |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Crea il ruolo di esecuzione Lambda. | Esegui il comando AWS CLI create-role
dove
| Architetto del cloud, amministratore del cloud |
Associa policy gestite al ruolo Lambda. | Esegui il AWS CLI attach-role-policy
| Architetto del cloud, amministratore del cloud |
Crea una politica per concedere alla funzione di indice Lambda il permesso di leggere gli oggetti S3. | Esegui il comando AWS CLI create-policy
Il file
| Architetto del cloud, amministratore del cloud |
Allega la politica di autorizzazione di Amazon S3 al ruolo di esecuzione Lambda. | Esegui il AWS CLI attach-role-policy
| Architetto cloud, amministratore cloud |
Crea la funzione di indice Lambda. | Esegui il comando AWS CLI create-function
| Architetto del cloud, amministratore del cloud |
Consenti ad Amazon S3 di chiamare la funzione di indice Lambda. | Esegui il comando AWS CLI add-permission
| Architetto del cloud, amministratore del cloud |
Aggiungi un trigger Lambda per l'evento Amazon S3. | Esegui il AWS CLI put-bucket-notification-configuration
Il file | Architetto del cloud, amministratore del cloud |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Crea il ruolo di esecuzione Lambda. | Esegui il comando AWS CLI create-role
dove
| Architetto del cloud, amministratore del cloud |
Associa policy gestite al ruolo Lambda. | Esegui il AWS CLI attach-role-policy
| Architetto del cloud, amministratore del cloud |
Crea la funzione di ricerca Lambda. | Esegui il comando AWS CLI create-function
| Architetto del cloud, amministratore del cloud |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Crea IAM ruoli di inquilino. | Esegui il comando AWS CLI create-role
Il file
| Architetto del cloud, amministratore del cloud |
Crea una IAM politica per gli inquilini. | Esegui il comando AWS CLI create-policy
Il file
| Architetto del cloud, amministratore del cloud |
Allega la IAM politica del tenant ai ruoli degli inquilini. | Esegui il AWS CLI attach-role-policy
La policy ARN è tratta dall'output del passaggio precedente. | Architetto del cloud, amministratore del cloud |
Crea una IAM politica per concedere a Lambda le autorizzazioni per assumere il ruolo. | Esegui il comando AWS CLI create-policy
Il file
Infatti | Architetto del cloud, amministratore del cloud |
Crea una IAM policy per concedere al ruolo dell'indice Lambda l'autorizzazione ad accedere ad Amazon S3. | Esegui il comando AWS CLI create-policy
Il file
| Architetto del cloud, amministratore del cloud |
Associa la policy al ruolo di esecuzione Lambda. | Esegui il AWS CLI attach-role-policy
La policy ARN è tratta dall'output del passaggio precedente. | Architetto del cloud, amministratore del cloud |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Crea un REST API in API Gateway. | Esegui il CLI create-rest-api
Per il tipo di configurazione dell'endpoint, è possibile specificare Annotate il valore del | Architetto del cloud, amministratore del cloud |
Crea una risorsa per la ricercaAPI. | La API risorsa di ricerca avvia la funzione di ricerca Lambda con il nome della risorsa.
| Architetto del cloud, amministratore del cloud |
Crea un GET metodo per la ricercaAPI. | Esegui il comando AWS CLI put-method
Per | Architetto cloud, amministratore cloud |
Crea un metodo di risposta per la ricercaAPI. | Esegui il AWS CLI put-method-response
Per | Architetto del cloud, amministratore del cloud |
Configura un'integrazione proxy Lambda per la ricerca. API | Esegui il AWS CLI comando put-integration
Per | Architetto del cloud, amministratore del cloud |
Concedi a API Gateway l'autorizzazione a chiamare la funzione di ricerca Lambda. | Esegui il comando AWS CLI add-permission
Modifica il | Architetto del cloud, amministratore del cloud |
Implementa la ricercaAPI. | Esegui il comando AWS CLI create-deployment
Se si aggiorna ilAPI, è possibile utilizzare lo stesso CLI comando per ridistribuirlo nella stessa fase. | Architetto del cloud, amministratore del cloud |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Accedi alla console Kibana. |
| Architetto del cloud, amministratore del cloud |
Crea e configura i ruoli di Kibana. | Per garantire l'isolamento dei dati e assicurarsi che un tenant non possa recuperare i dati di un altro tenant, è necessario utilizzare la sicurezza dei documenti, che consente agli inquilini di accedere solo ai documenti che contengono il loro ID tenant.
| Architetto del cloud, amministratore del cloud |
Associa gli utenti ai ruoli. |
Ti consigliamo di automatizzare la creazione dei ruoli tenant e Kibana al momento dell'onboarding del tenant. | Architetto del cloud, amministratore del cloud |
Crea l'indice dei dati dei tenant. | Nel riquadro di navigazione, in Gestione, scegli Dev Tools, quindi esegui il comando seguente. Questo comando crea l'
| Architetto del cloud, amministratore del cloud |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Crea un VPC endpoint per Amazon S3. | Esegui il AWS CLI create-vpc-endpoint
Per | Architetto del cloud, amministratore del cloud |
Crea un VPC endpoint per AWSSTS. | Esegui il AWS CLI create-vpc-endpoint
Per | Architetto del cloud, amministratore del cloud |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Aggiorna i file Python per le funzioni di indice e ricerca. |
Puoi ottenere l'endpoint Elasticsearch dalla scheda Panoramica della console di Amazon OpenSearch Service. Ha il formato. | Architetto del cloud, sviluppatore di app |
Aggiorna il codice Lambda. | Usa il AWS CLI update-function-code
| Architetto del cloud, sviluppatore di app |
Carica i dati grezzi nel bucket S3. | Usa il comando AWS CLI cp
Il bucket S3 è configurato per eseguire la funzione di indice Lambda ogni volta che i dati vengono caricati in modo che il documento venga indicizzato in Elasticsearch. | Architetto del cloud, amministratore del cloud |
Cerca dati dalla console Kibana. | Sulla console Kibana, esegui la seguente query:
Questa query mostra tutti i documenti indicizzati in Elasticsearch. In questo caso, dovresti vedere due documenti separati per Tenant-1 e Tenant-2. | Architetto del cloud, amministratore del cloud |
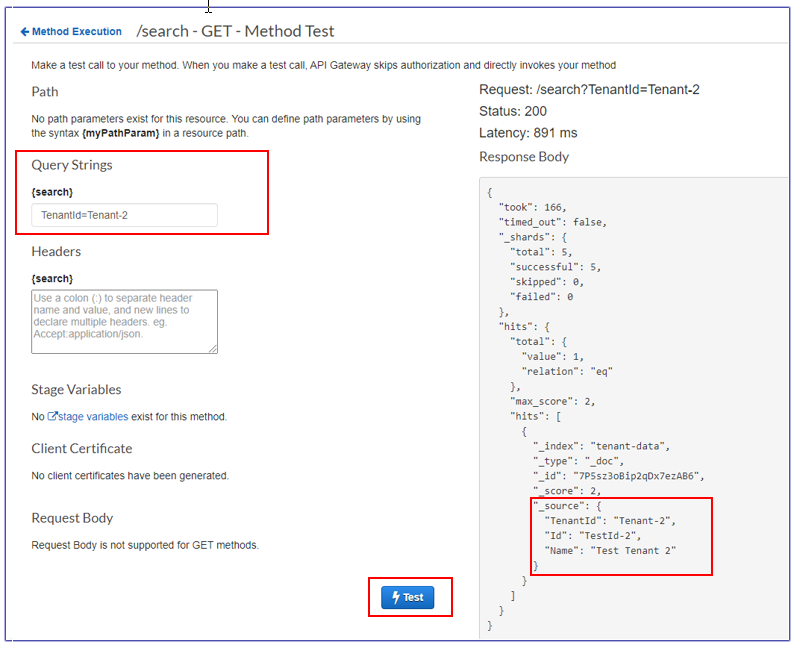
Prova la ricerca API da API Gateway. |
Per le illustrazioni delle schermate, vedere la sezione Informazioni aggiuntive. | Architetto del cloud, sviluppatore di app |
Risorse correlate
Informazioni aggiuntive
Modelli di partizionamento dei dati
Esistono tre modelli di partizionamento dei dati comuni utilizzati nei sistemi multi-tenant: silo, pool e hybrid. Il modello scelto dipende dalla conformità, dalla rumorosità dei sistemi vicini, dalle operazioni e dalle esigenze di isolamento dell'ambiente.
Modello Silo
Nel modello a silo, i dati di ciascun inquilino vengono archiviati in un'area di archiviazione distinta in cui non vi è alcuna combinazione dei dati del tenant. Puoi utilizzare due approcci per implementare il modello a silo con Amazon OpenSearch Service: dominio per tenant e indice per tenant.
Dominio per tenant: puoi utilizzare un dominio Amazon OpenSearch Service separato (sinonimo di cluster Elasticsearch) per tenant. L'inserimento di ogni tenant nel proprio dominio offre tutti i vantaggi associati alla presenza di dati in una struttura autonoma. Tuttavia, questo approccio introduce sfide di gestione e agilità. La sua natura distribuita rende più difficile l'aggregazione e la valutazione dello stato operativo e dell'attività degli inquilini. Si tratta di un'opzione costosa che richiede che ogni dominio Amazon OpenSearch Service disponga di almeno tre nodi master e due nodi di dati per i carichi di lavoro di produzione.

Indice per tenant: puoi inserire i dati dei tenant in indici separati all'interno di un cluster Amazon Service. OpenSearch Con questo approccio, utilizzi un identificatore del tenant quando crei e dai un nome all'indice, anteponendo l'identificatore del tenant al nome dell'indice. L'approccio dell'indice per tenant consente di raggiungere gli obiettivi dei silo senza introdurre un cluster completamente separato per ogni tenant. Tuttavia, se il numero di indici aumenta, si potrebbe verificare una pressione sulla memoria, poiché questo approccio richiede più shard e il nodo master deve gestire una maggiore allocazione e ribilanciamento.

Isolamento nel modello a silo: nel modello a silo, si utilizzano le IAM policy per isolare i domini o gli indici che contengono i dati di ciascun tenant. Queste politiche impediscono a un tenant di accedere ai dati di un altro tenant. Per implementare il modello di isolamento dei silo, è possibile creare una politica basata sulle risorse che controlli l'accesso alla risorsa del tenant. Si tratta spesso di una politica di accesso al dominio che specifica quali azioni un principale può eseguire sulle risorse secondarie del dominio, inclusi gli indici Elasticsearch e. APIs Con IAM le policy basate sull'identità, puoi specificare azioni consentite o negate sul dominio, sugli indici o all'interno di Amazon Service. APIs OpenSearch L'Action elemento di una IAM policy descrive l'azione o le azioni specifiche consentite o negate dalla policy e specifica gli account, gli Principal utenti o i ruoli interessati.
La seguente politica di esempio concede al Tenant-1 l'accesso completo (come specificato daes:*) solo alle risorse secondarie del dominio. tenant-1 La fine /* dell'Resource elemento indica che questa politica si applica alle risorse secondarie del dominio, non al dominio stesso. Quando questa politica è in vigore, i tenant non sono autorizzati a creare un nuovo dominio o modificare le impostazioni su un dominio esistente.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::aws-account-id:user/Tenant-1" }, "Action": "es:*", "Resource": "arn:aws:es:Region:account-id:domain/tenant-1/*" } ] }
Per implementare il modello di silo tenant per Index, è necessario modificare questa politica di esempio per limitare ulteriormente Tenant-1 all'indice o agli indici specificati, specificando il nome dell'indice. La seguente politica di esempio limita Tenant-1 all'indice. tenant-index-1
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789012:user/Tenant-1" }, "Action": "es:*", "Resource": "arn:aws:es:Region:account-id:domain/test-domain/tenant-index-1/*" } ] }
Modello di piscina
Nel modello di pool, tutti i dati dei tenant vengono archiviati in un indice all'interno dello stesso dominio. L'identificatore del tenant è incluso nei dati (documento) e utilizzato come chiave di partizione, in modo da poter determinare quali dati appartengono a quale tenant. Questo modello riduce il sovraccarico di gestione. Il funzionamento e la gestione dell'indice raggruppato sono più semplici ed efficienti rispetto alla gestione di più indici. Tuttavia, poiché i dati dei tenant vengono combinati all'interno dello stesso indice, si perde il naturale isolamento dei tenant fornito dal modello a silo. Questo approccio potrebbe inoltre ridurre le prestazioni a causa dell'effetto Noisy Neighbor.

Isolamento dei tenant nel modello pool: in generale, l'isolamento dei tenant è difficile da implementare nel modello pool. Il IAM meccanismo utilizzato con il modello a silo non consente di descrivere l'isolamento in base all'ID del tenant memorizzato nel documento.
Un approccio alternativo consiste nell'utilizzare il supporto granulare di controllo degli accessi (FGAC) fornito da Open Distro for Elasticsearch. FGACconsente di controllare le autorizzazioni a livello di indice, documento o campo. Con ogni richiesta, FGAC valuta le credenziali dell'utente e autentica l'utente o nega l'accesso. Se FGAC autentica l'utente, recupera tutti i ruoli mappati a quell'utente e utilizza il set completo di autorizzazioni per determinare come gestire la richiesta.
Per ottenere l'isolamento richiesto nel modello in pool, è possibile utilizzare la sicurezza a livello di documento
{ "bool": { "must": { "match": { "tenantId": "Tenant-1" } } } }
Modello ibrido
Il modello ibrido utilizza una combinazione dei modelli a silo e pool nello stesso ambiente per offrire esperienze uniche a ciascun livello di tenant (ad esempio i livelli gratuito, standard e premium). Ogni livello segue lo stesso profilo di sicurezza utilizzato nel modello pool.
Isolamento dei tenant nel modello ibrido: nel modello ibrido, si segue lo stesso profilo di sicurezza del modello pool, dove l'utilizzo del modello di FGAC sicurezza a livello di documento forniva l'isolamento dei tenant. Sebbene questa strategia semplifichi la gestione dei cluster e offra agilità, complica altri aspetti dell'architettura. Ad esempio, il codice richiede una complessità aggiuntiva per determinare quale modello è associato a ciascun tenant. È inoltre necessario assicurarsi che le query relative a un solo tenant non saturino l'intero dominio e compromettano l'esperienza degli altri tenant.
Test in Gateway API
Finestra di test per la query Tenant-1

Finestra di test per la query Tenant-2
Allegati
