Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Esegui la migrazione della funzionalità Oracle ROWID a PostgreSQL su AWS
Rakesh Raghav e Ramesh Pathuri, Amazon Web Services
Riepilogo
Questo modello descrive le opzioni per la migrazione della funzionalità delle ROWID pseudocolonne in Oracle Database a un database PostgreSQL in Amazon Relational Database Service (Amazon RDS) per PostgreSQL, Amazon Aurora PostgreSQL Compatible Edition o Amazon Elastic Compute Cloud (Amazon). EC2
In un database Oracle, la pseudocolonna è l'indirizzo fisico di una riga in una tabella. ROWID Questa pseudocolonna viene utilizzata per identificare in modo univoco una riga anche se la chiave primaria non è presente in una tabella. PostgreSQL ha una pseudocolonna simile ctid chiamata, ma non può essere usata come. ROWID Come spiegato nella documentazione di PostgreSQLctid, potrebbe cambiare se viene aggiornato o dopo ogni processo. VACUUM
Esistono tre modi per creare la funzionalità ROWID pseudocolonna in PostgreSQL:
Usa una colonna chiave primaria invece di identificare una riga
ROWIDin una tabella.Utilizzate una primary/unique chiave logica (che potrebbe essere una chiave composita) nella tabella.
Aggiungi una colonna con valori generati automaticamente e rendila una primary/unique chiave da
ROWIDimitare.
Questo modello illustra tutte e tre le implementazioni e descrive i vantaggi e gli svantaggi di ciascuna opzione.
Prerequisiti e limitazioni
Prerequisiti
Un account AWS attivo
Esperienza di codifica procedurale Language/PostgreSQL (PL/pgSQL)
Fonte Oracle Database
Un cluster compatibile con Amazon RDS per PostgreSQL o Aurora PostgreSQL o un'istanza per ospitare il database PostgreSQL EC2
Limitazioni
Questo modello fornisce
ROWIDsoluzioni alternative per la funzionalità. PostgreSQL non fornisce un equivalente a in Oracle Database.ROWID
Versioni del prodotto
PostgreSQL 11.9 o versione successiva
Architettura
Stack tecnologico di origine
Oracle Database
Stack tecnologico di destinazione
Compatibile con Aurora PostgreSQL, Amazon RDS per PostgreSQL o un'istanza con un database PostgreSQL EC2
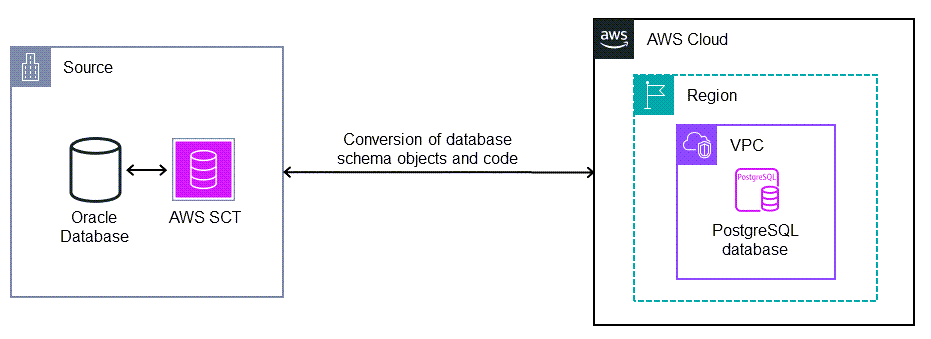
Opzioni di implementazione
Esistono tre opzioni per ovviare alla mancanza di ROWID supporto in PostgreSQL, a seconda che la tabella abbia una chiave primaria o un indice univoco, una chiave primaria logica o un attributo di identità. La scelta dipende dalle tempistiche del progetto, dalla fase di migrazione corrente e dalle dipendenze dall'applicazione e dal codice del database.
Opzione | Descrizione | Vantaggi | Svantaggi |
|---|---|---|---|
Chiave primaria o indice univoco | Se la tabella Oracle ha una chiave primaria, puoi utilizzare gli attributi di questa chiave per identificare in modo univoco una riga. |
|
|
Chiave logica primary/unique | Se la tabella Oracle ha una chiave primaria logica, è possibile utilizzare gli attributi di questa chiave per identificare in modo univoco una riga. Una chiave primaria logica è costituita da un attributo o da un insieme di attributi che possono identificare in modo univoco una riga, ma non viene applicata al database tramite un vincolo. |
|
|
Attributo di identità | se la tua tabella Oracle non ha una chiave primaria, puoi creare un campo aggiuntivo come |
|
|
Strumenti
Amazon Relational Database Service (Amazon RDS) per PostgreSQL ti aiuta a configurare, gestire e scalare un database relazionale PostgreSQL nel cloud AWS.
Amazon Aurora PostgreSQL Compatible Edition è un motore di database relazionale completamente gestito e conforme ad ACID che ti aiuta a configurare, gestire e scalare le distribuzioni PostgreSQL.
AWS Command Line Interface (AWS CLI) è uno strumento open source che ti aiuta a interagire con i servizi AWS tramite comandi nella tua shell a riga di comando. In questo modello, puoi utilizzare l'AWS CLI per eseguire comandi SQL tramite pgAdmin.
pgAdmin
è uno strumento di gestione open source per PostgreSQL. Fornisce un'interfaccia grafica che consente di creare, gestire e utilizzare oggetti di database. AWS Schema Conversion Tool (AWS SCT) supporta migrazioni di database eterogenei convertendo automaticamente lo schema del database di origine e la maggior parte del codice personalizzato in un formato compatibile con il database di destinazione.
Epiche
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Identifica le tabelle Oracle che utilizzano l' | Utilizza AWS Schema Conversion Tool (AWS SCT) per identificare le tabelle Oracle dotate di oppure In Oracle, usa la | DBA o sviluppatore |
Identifica il codice che fa riferimento a queste tabelle. | Usa AWS SCT per generare un rapporto di valutazione della migrazione per identificare le procedure interessate da oppure Nel database Oracle di origine, utilizza il campo di testo della | DBA o sviluppatore |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Identifica le tabelle che non dispongono di chiavi primarie. | Nel database Oracle di origine, utilizzare
| DBA o sviluppatore |
| Attività | Descrizione | Competenze richieste |
|---|---|---|
Applica le modifiche alle tabelle che hanno una chiave primaria definita o logica. | Apportate le modifiche al codice dell'applicazione e del database mostrate nella sezione Informazioni aggiuntive per utilizzare una chiave primaria univoca o una chiave primaria logica per identificare una riga nella tabella. | DBA o sviluppatore |
Aggiungi un campo aggiuntivo alle tabelle che non hanno una chiave primaria definita o logica. | Aggiungi un attributo di tipo | DBA o sviluppatore |
Aggiungi un indice se necessario. | Aggiungi un indice al campo aggiuntivo o alla chiave logica primaria per migliorare le prestazioni SQL. | DBA o sviluppatore |
Risorse correlate
Colonne generate
(documentazione PostgreSQL) Pseudocolonna ROWID
(documentazione Oracle)
Informazioni aggiuntive
Le sezioni seguenti forniscono esempi di codice Oracle e PostgreSQL per illustrare i tre approcci.
Scenario 1: utilizzo di una chiave unica primaria
Negli esempi seguenti, si crea la tabella testrowid_s1 con emp_id come chiave primaria.
Codice Oracle:
create table testrowid_s1 (emp_id integer, name varchar2(10), CONSTRAINT testrowid_pk PRIMARY KEY (emp_id)); INSERT INTO testrowid_s1(emp_id,name) values (1,'empname1'); INSERT INTO testrowid_s1(emp_id,name) values (2,'empname2'); INSERT INTO testrowid_s1(emp_id,name) values (3,'empname3'); INSERT INTO testrowid_s1(emp_id,name) values (4,'empname4'); commit; SELECT rowid,emp_id,name FROM testrowid_s1; ROWID EMP_ID NAME ------------------ ---------- ---------- AAAF3pAAAAAAAMOAAA 1 empname1 AAAF3pAAAAAAAMOAAB 2 empname2 AAAF3pAAAAAAAMOAAC 3 empname3 AAAF3pAAAAAAAMOAAD 4 empname4 UPDATE testrowid_s1 SET name = 'Ramesh' WHERE rowid = 'AAAF3pAAAAAAAMOAAB' ; commit; SELECT rowid,emp_id,name FROM testrowid_s1; ROWID EMP_ID NAME ------------------ ---------- ---------- AAAF3pAAAAAAAMOAAA 1 empname1 AAAF3pAAAAAAAMOAAB 2 Ramesh AAAF3pAAAAAAAMOAAC 3 empname3 AAAF3pAAAAAAAMOAAD 4 empname4
Codice PostgreSQL:
CREATE TABLE public.testrowid_s1 ( emp_id integer, name character varying, primary key (emp_id) ); insert into public.testrowid_s1 (emp_id,name) values (1,'empname1'),(2,'empname2'),(3,'empname3'),(4,'empname4'); select emp_id,name from testrowid_s1; emp_id | name --------+---------- 1 | empname1 2 | empname2 3 | empname3 4 | empname4 update testrowid_s1 set name = 'Ramesh' where emp_id = 2 ; select emp_id,name from testrowid_s1; emp_id | name --------+---------- 1 | empname1 3 | empname3 4 | empname4 2 | Ramesh
Scenario 2: utilizzo di una chiave logica primaria
Negli esempi seguenti, si crea la tabella testrowid_s2 con emp_id come chiave primaria logica.
Codice Oracle:
create table testrowid_s2 (emp_id integer, name varchar2(10) ); INSERT INTO testrowid_s2(emp_id,name) values (1,'empname1'); INSERT INTO testrowid_s2(emp_id,name) values (2,'empname2'); INSERT INTO testrowid_s2(emp_id,name) values (3,'empname3'); INSERT INTO testrowid_s2(emp_id,name) values (4,'empname4'); commit; SELECT rowid,emp_id,name FROM testrowid_s2; ROWID EMP_ID NAME ------------------ ---------- ---------- AAAF3rAAAAAAAMeAAA 1 empname1 AAAF3rAAAAAAAMeAAB 2 empname2 AAAF3rAAAAAAAMeAAC 3 empname3 AAAF3rAAAAAAAMeAAD 4 empname4 UPDATE testrowid_s2 SET name = 'Ramesh' WHERE rowid = 'AAAF3rAAAAAAAMeAAB' ; commit; SELECT rowid,emp_id,name FROM testrowid_s2; ROWID EMP_ID NAME ------------------ ---------- ---------- AAAF3rAAAAAAAMeAAA 1 empname1 AAAF3rAAAAAAAMeAAB 2 Ramesh AAAF3rAAAAAAAMeAAC 3 empname3 AAAF3rAAAAAAAMeAAD 4 empname4
Codice PostgreSQL:
CREATE TABLE public.testrowid_s2 ( emp_id integer, name character varying ); insert into public.testrowid_s2 (emp_id,name) values (1,'empname1'),(2,'empname2'),(3,'empname3'),(4,'empname4'); select emp_id,name from testrowid_s2; emp_id | name --------+---------- 1 | empname1 2 | empname2 3 | empname3 4 | empname4 update testrowid_s2 set name = 'Ramesh' where emp_id = 2 ; select emp_id,name from testrowid_s2; emp_id | name --------+---------- 1 | empname1 3 | empname3 4 | empname4 2 | Ramesh
Scenario 3: utilizzo di un attributo di identità
Negli esempi seguenti, si crea la tabella testrowid_s3 senza chiave primaria e utilizzando un attributo di identità.
Codice Oracle:
create table testrowid_s3 (name varchar2(10)); INSERT INTO testrowid_s3(name) values ('empname1'); INSERT INTO testrowid_s3(name) values ('empname2'); INSERT INTO testrowid_s3(name) values ('empname3'); INSERT INTO testrowid_s3(name) values ('empname4'); commit; SELECT rowid,name FROM testrowid_s3; ROWID NAME ------------------ ---------- AAAF3sAAAAAAAMmAAA empname1 AAAF3sAAAAAAAMmAAB empname2 AAAF3sAAAAAAAMmAAC empname3 AAAF3sAAAAAAAMmAAD empname4 UPDATE testrowid_s3 SET name = 'Ramesh' WHERE rowid = 'AAAF3sAAAAAAAMmAAB' ; commit; SELECT rowid,name FROM testrowid_s3; ROWID NAME ------------------ ---------- AAAF3sAAAAAAAMmAAA empname1 AAAF3sAAAAAAAMmAAB Ramesh AAAF3sAAAAAAAMmAAC empname3 AAAF3sAAAAAAAMmAAD empname4
Codice PostgreSQL:
CREATE TABLE public.testrowid_s3 ( rowid_seq bigint generated always as identity, name character varying ); insert into public.testrowid_s3 (name) values ('empname1'),('empname2'),('empname3'),('empname4'); select rowid_seq,name from testrowid_s3; rowid_seq | name -----------+---------- 1 | empname1 2 | empname2 3 | empname3 4 | empname4 update testrowid_s3 set name = 'Ramesh' where rowid_seq = 2 ; select rowid_seq,name from testrowid_s3; rowid_seq | name -----------+---------- 1 | empname1 3 | empname3 4 | empname4 2 | Ramesh
