Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Componenti dell'architettura di un data warehouse Amazon Redshift
Ti consigliamo di avere una conoscenza di base dei componenti principali dell'architettura in un data warehouse Amazon Redshift. Queste conoscenze possono aiutarti a comprendere meglio come progettare query e tabelle per prestazioni ottimali.
Un data warehouse in Amazon Redshift è costituito dai seguenti componenti dell'architettura di base:
-
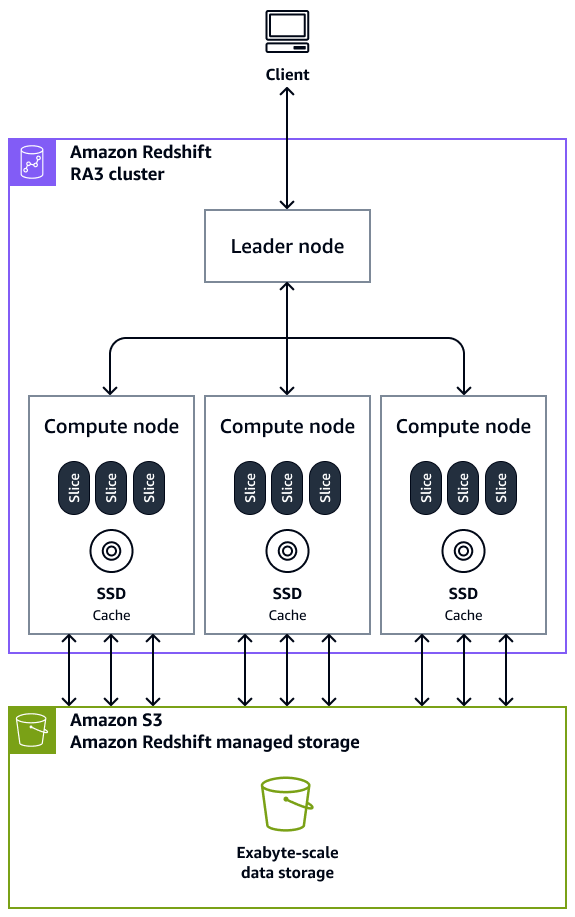
Cluster: un cluster, composto da uno o più nodi di elaborazione, è il componente principale dell'infrastruttura di un data warehouse Amazon Redshift. I nodi di calcolo sono trasparenti per le applicazioni esterne, ma l'applicazione client interagisce direttamente solo con il nodo leader. Un cluster tipico ha due o più nodi di elaborazione. I nodi di elaborazione sono coordinati tramite il nodo leader.
-
Nodo leader: un nodo leader gestisce le comunicazioni per i programmi client e tutti i nodi di elaborazione. Un nodo leader prepara inoltre i piani per l'esecuzione di una query ogni volta che una query viene inviata a un cluster. Dopo che i piani sono pronti, il nodo leader compila il codice, distribuisce il codice compilato ai nodi di calcolo e quindi assegna porzioni di dati a ciascun nodo di calcolo per elaborare i risultati della query.
-
Nodo di calcolo: un nodo di calcolo esegue una query. Il nodo leader compila il codice per i singoli elementi del piano di esecuzione della query e lo assegna ai singoli nodi di calcolo. I nodi di calcolo eseguono il codice compilato e restituiscono risultati intermedi al nodo principale per l'aggregazione finale. Ogni nodo di elaborazione dispone di CPU, memoria e storage su disco collegati dedicati. Con il crescere del carico di lavoro, puoi aumentare la capacità di elaborazione e di storage di un cluster aumentando il numero di nodi, aggiornando il tipo di nodi o tramite entrambe queste operazioni.
-
Node slice: un nodo di elaborazione è suddiviso in unità chiamate slice. A ogni slice in un nodo di calcolo viene allocata una parte della memoria e dello spazio su disco del nodo, dove elabora una parte del carico di lavoro assegnato al nodo. Le sezioni operano quindi in parallelo per completare l'operazione. I dati vengono distribuiti tra le slice in base allo stile di distribuzione e alla chiave di distribuzione di una particolare tabella. Una distribuzione uniforme dei dati consente ad Amazon Redshift di assegnare in modo uniforme i carichi di lavoro alle slice e massimizza i vantaggi dell'elaborazione parallela. Il numero di slice per nodo di elaborazione viene deciso in base al tipo di nodo. Per ulteriori informazioni, consulta Cluster e nodi in Amazon Redshift nella documentazione di Amazon Redshift.
-
Elaborazione parallela massiva (MPP): Amazon Redshift utilizza l'architettura MPP per elaborare rapidamente dati, anche query complesse e grandi quantità di dati. Più nodi di calcolo eseguono lo stesso codice di query su porzioni di dati per massimizzare l'elaborazione parallela.
-
Applicazione client: Amazon Redshift si integra con vari strumenti di estrazione, trasformazione e caricamento (ETL), di business intelligence (BI), di data mining e di analisi. Tutte le applicazioni client comunicano con il cluster solo tramite il nodo leader.
Il diagramma seguente mostra come i componenti dell'architettura di un data warehouse Amazon Redshift interagiscono per accelerare le query.