Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Caso d'uso: previsione degli esiti dei pazienti e dei tassi di riammissione
L'analisi predittiva basata sull'intelligenza artificiale offre ulteriori vantaggi prevedendo gli esiti dei pazienti e abilitando piani di trattamento personalizzati. Ciò può migliorare la soddisfazione dei pazienti e gli esiti sanitari. Integrando queste funzionalità di intelligenza artificiale con Amazon Bedrock e altre tecnologie, gli operatori sanitari possono ottenere significativi aumenti di produttività, ridurre i costi ed elevare la qualità complessiva dell'assistenza ai pazienti.
È possibile archiviare dati medici, come anamnesi dei pazienti, note cliniche, farmaci e trattamenti, in un Knowledge Graph.
Questa soluzione consente di prevedere la probabilità di una riammissione. Queste previsioni possono migliorare gli esiti dei pazienti e ridurre i costi sanitari. Questa soluzione può anche aiutare i medici e gli amministratori ospedalieri a concentrare la propria attenzione sui pazienti con un rischio più elevato di riammissione. Inoltre, li aiuta ad avviare interventi proattivi con tali pazienti tramite avvisi, azioni self-service e basate sui dati.
Panoramica della soluzione
Questa soluzione utilizza un framework multi-retrieval Augmented Generation (RAG) per analizzare i dati dei pazienti. Prevede la probabilità di riammissione ospedaliera per i singoli pazienti e aiuta a calcolare un punteggio di propensione alla riammissione a livello ospedaliero. Questa soluzione integra le seguenti funzionalità:
-
Knowledge graph: archivia i dati strutturati e cronologici dei pazienti, come gli incontri ospedalieri, i precedenti ricoveri, i sintomi, i risultati di laboratorio, i trattamenti prescritti e l'anamnesi di aderenza ai farmaci
-
Database vettoriale: archivia dati clinici non strutturati, come riepiloghi delle dimissioni, note mediche e registrazioni degli appuntamenti mancati o degli effetti collaterali segnalati dei farmaci
-
LLM ottimizzato: utilizza sia i dati strutturati del Knowledge Graph che i dati non strutturati del database vettoriale per generare inferenze sul comportamento del paziente, sull'aderenza al trattamento e sulla probabilità di riammissione
I modelli di valutazione del rischio quantificano le inferenze del LLM in punteggi numerici. È possibile aggregare i punteggi in un punteggio di propensione alla riammissione a livello ospedaliero. Questo punteggio definisce l'esposizione al rischio di ogni paziente ed è possibile calcolarlo periodicamente o in base alle necessità. Tutte le inferenze e i punteggi di rischio sono indicizzati e archiviati in Amazon OpenSearch Service in modo che i responsabili sanitari e i medici possano recuperarli. Integrando un agente di intelligenza artificiale conversazionale con questo database vettoriale, i medici e i responsabili dell'assistenza possono estrarre informazioni senza problemi a livello di singolo paziente, a livello di struttura o per specialità medica. Puoi anche impostare avvisi automatici basati sui punteggi di rischio, per incoraggiare interventi proattivi.
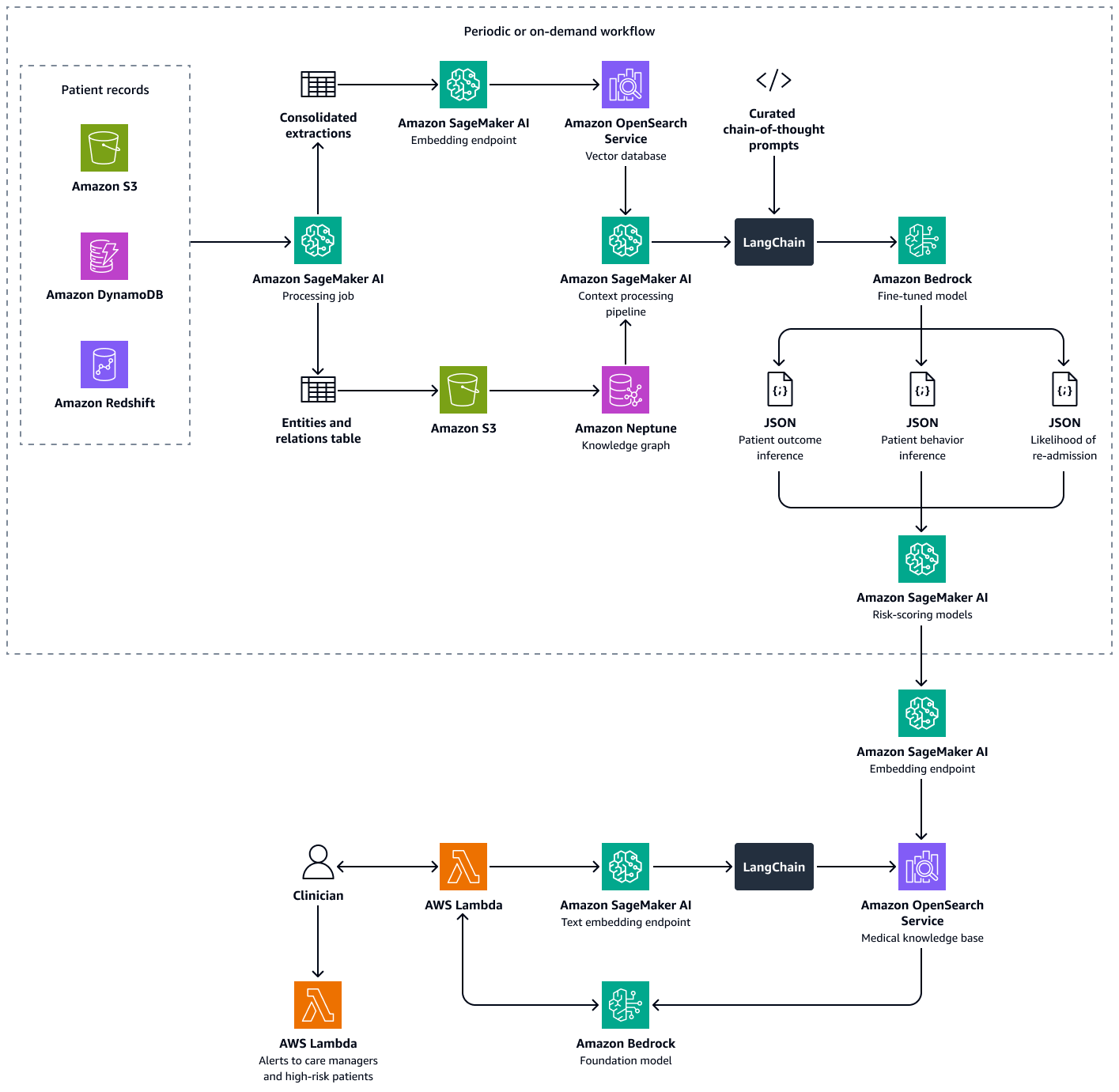
La creazione di questa soluzione prevede i seguenti passaggi:
-
Fase 1: Previsione degli esiti dei pazienti utilizzando un grafico delle conoscenze mediche
-
Fase 2: Previsione del comportamento del paziente rispetto ai farmaci o ai trattamenti prescritti
-
Fase 3: Previsione della probabilità di riammissione del paziente
-
Fase 4: Calcolo del punteggio di propensione alla riammissione in ospedale
Fase 1: Previsione degli esiti dei pazienti utilizzando un grafico delle conoscenze mediche
In Amazon Neptune, puoi utilizzare un Knowledge Graph per archiviare informazioni temporali sulle visite e sugli esiti dei pazienti nel tempo. Il modo più efficace per creare e archiviare un knowledge graph consiste nell'utilizzare un modello grafico e un database grafico. I database a grafi sono progettati appositamente per archiviare e gestire le relazioni. I database a grafi semplificano la modellazione e la gestione di dati altamente connessi e dispongono di schemi flessibili.
Il Knowledge Graph consente di eseguire analisi di serie temporali. Di seguito sono riportati gli elementi chiave del database grafico utilizzato per la previsione temporale degli esiti dei pazienti:
-
Dati storici: diagnosi precedenti, terapia continuativa, farmaci usati in precedenza e risultati di laboratorio relativi al paziente
-
Visite dei pazienti (cronologiche): date delle visite, sintomi, allergie osservate, note cliniche, diagnosi, procedure, trattamenti, farmaci prescritti e risultati di laboratorio
-
Sintomi e parametri clinici: informazioni cliniche e basate sui sintomi, tra cui la gravità, i modelli di progressione e la risposta del paziente al farmaco
Puoi utilizzare gli approfondimenti del Medical Knowledge Graph per perfezionare un LLM in Amazon Bedrock, come Llama 3. Puoi perfezionare il LLM con dati sequenziali del paziente sulla risposta del paziente a una serie di farmaci o trattamenti nel tempo. Utilizzate un set di dati etichettato che classifica una serie di farmaci o trattamenti e i dati di interazione paziente-clinica in categorie predefinite che indicano lo stato di salute di un paziente. Esempi di queste categorie sono il deterioramento della salute, il miglioramento o il progresso stabile. Quando il medico inserisce un nuovo contesto sul paziente e sui suoi sintomi, il LLM ottimizzato può utilizzare i modelli del set di dati di formazione per prevedere il potenziale esito del paziente.
L'immagine seguente mostra i passaggi sequenziali necessari per perfezionare un LLM in Amazon Bedrock utilizzando un set di dati di formazione specifico per il settore sanitario. Questi dati potrebbero includere le condizioni mediche dei pazienti e le risposte ai trattamenti nel tempo. Questo set di dati di formazione aiuterebbe il modello a fare previsioni generalizzate sugli esiti dei pazienti.
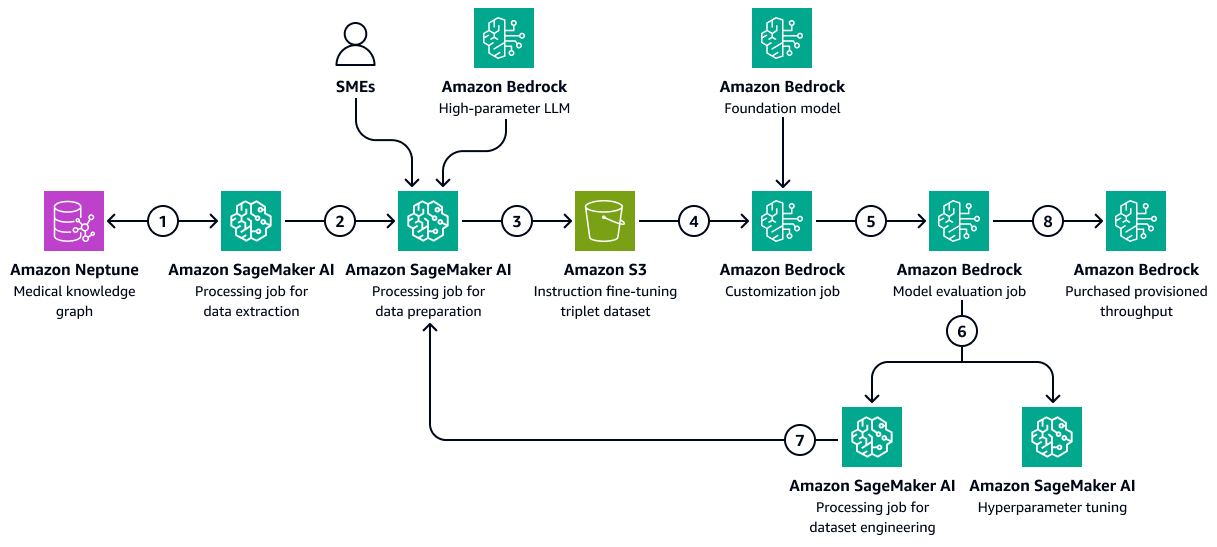
Il diagramma mostra il flusso di lavoro seguente:
-
Il processo di estrazione dei dati di Amazon SageMaker AI interroga il Knowledge Graph per recuperare dati cronologici sulle risposte dei diversi pazienti a una serie di farmaci o trattamenti nel tempo.
-
Il processo di preparazione dei dati SageMaker AI integra un Amazon Bedrock LLM e input di esperti in materia (). SMEs Il lavoro classifica i dati recuperati dal Knowledge Graph in categorie predefinite (come deterioramento della salute, miglioramento o progresso stabile) che indicano lo stato di salute di ciascun paziente.
-
Il lavoro crea un set di dati di ottimizzazione che include le informazioni estratte dal Knowledge Graph, le istruzioni e la categoria di esiti del paziente. chain-of-thought Carica questo set di dati di addestramento in un bucket Amazon S3.
-
Un processo di personalizzazione di Amazon Bedrock utilizza questo set di dati di formazione per mettere a punto un LLM.
-
Il processo di personalizzazione di Amazon Bedrock integra il modello base di Amazon Bedrock preferito nell'ambiente di formazione. Avvia il processo di ottimizzazione e utilizza il set di dati di addestramento e gli iperparametri di allenamento che configuri.
-
Un processo di valutazione di Amazon Bedrock valuta il modello ottimizzato utilizzando un framework di valutazione del modello predefinito.
-
Se il modello necessita di miglioramenti, il processo di formazione viene riavviato con più dati dopo un'attenta valutazione del set di dati di addestramento. Se il modello non dimostra un miglioramento incrementale delle prestazioni, valuta anche la possibilità di modificare gli iperparametri di allenamento.
-
Dopo che la valutazione del modello soddisfa gli standard definiti dagli stakeholder aziendali, esegui l'hosting del modello ottimizzato in base al throughput assegnato da Amazon Bedrock.
Fase 2: Previsione del comportamento del paziente rispetto ai farmaci o ai trattamenti prescritti
Fine-tuned è in LLMs grado di elaborare note cliniche, riepiloghi delle dimissioni e altri documenti specifici del paziente tratti dal grafico temporale delle conoscenze mediche. Possono valutare se è probabile che il paziente segua i farmaci o i trattamenti prescritti.
Questo passaggio utilizza il Knowledge Graph creato inFase 1: Previsione degli esiti dei pazienti utilizzando un grafico delle conoscenze mediche. Il Knowledge Graph contiene i dati del profilo del paziente, inclusa l'aderenza storica del paziente come nodo. Tra le caratteristiche di tali nodi sono inclusi anche casi di mancata aderenza a farmaci o trattamenti, effetti collaterali dei farmaci, mancanza di accesso o barriere di costo ai farmaci o regimi di dosaggio complessi.
Fine-tuned LLMs può utilizzare i dati di adempimento delle prescrizioni precedenti tratti dal Medical Knowledge Graph e i riepiloghi descrittivi delle note cliniche da un database vettoriale di Amazon Service. OpenSearch Queste note cliniche potrebbero menzionare appuntamenti saltati frequentemente o la mancata osservanza dei trattamenti. L'LLM può utilizzare queste note per prevedere la probabilità di future non aderenze.
-
Preparare i dati di input come segue:
-
Dati strutturati: estrai i dati recenti dei pazienti, come le ultime tre visite e i risultati di laboratorio, dal grafico delle conoscenze mediche.
-
Dati non strutturati: recupera le note cliniche recenti dal database vettoriale di Amazon OpenSearch Service.
-
-
Crea un prompt di input che includa l'anamnesi del paziente e il contesto attuale. Di seguito è riportato un prompt di esempio:
You are a highly specialized AI model trained in healthcare predictive analytics. Your task is to analyze a patient's historical medical records, adherence patterns, and clinical context to predict the **likelihood of future non-adherence** to prescribed medications or treatments. ### **Patient Details** - **Patient ID:** {patient_id} - **Age:** {age} - **Gender:** {gender} - **Medical Conditions:** {medical_conditions} - **Current Medications:** {current_medications} - **Prescribed Treatments:** {prescribed_treatments} ### **Chronological Medical History** - **Visit Dates & Symptoms:** {visit_dates_symptoms} - **Diagnoses & Procedures:** {diagnoses_procedures} - **Prescribed Medications & Treatments:** {medications_treatments} - **Past Adherence Patterns:** {historical_adherence} - **Instances of Non-Adherence:** {past_non_adherence} - **Side Effects Experienced:** {side_effects} - **Barriers to Adherence (e.g., Cost, Access, Dosing Complexity):** {barriers} ### **Patient-Specific Insights** - **Clinical Notes & Discharge Summaries:** {clinical_notes} - **Missed Appointments & Non-Compliance Patterns:** {missed_appointments} ### **Let's think Step-by-Step to predict the patient behaviour** 1. You should first analyze past adherence trends and patterns of non-adherence. 2. Identify potential barriers, such as financial constraints, medication side effects, or complex dosing regimens. 3. Thoroughly examine clinical notes and documented patient behaviors that may hint at non-adherence. 4. Correlate adherence history with prescribed treatments and patient conditions. 5. Finally predict the likelihood of non-adherence based on these contextual insights. ### **Output Format (JSON)** Return the prediction in the following structured format: ```json { "patient_id": "{patient_id}", "likelihood_of_non_adherence": "{low | moderate | high}", "reasoning": "{detailed_explanation_based_on_patient_history}" } -
Passa il prompt al LLM ottimizzato. L'LLM elabora il prompt e prevede il risultato. Di seguito è riportato un esempio di risposta del LLM:
{ "patient_id": "P12345", "likelihood_of_non_adherence": "high", "reasoning": "The patient has a history of missed appointments, has reported side effects to previous medications. Additionally, clinical notes indicate difficulty following complex dosing schedules." } -
Analizza la risposta del modello per estrarre la categoria di risultati prevista. Ad esempio, la categoria della risposta di esempio nel passaggio precedente potrebbe essere un'elevata probabilità di non aderenza.
-
(Facoltativo) Utilizzate i log dei modelli o metodi aggiuntivi per assegnare punteggi di confidenza. I logit sono le probabilità non normalizzate dell'elemento appartenente a una determinata classe o categoria.
Fase 3: Previsione della probabilità di riammissione del paziente
Le riammissioni ospedaliere sono una delle principali preoccupazioni a causa degli elevati costi di amministrazione sanitaria e del loro impatto sul benessere del paziente. Il calcolo dei tassi di riammissione ospedaliera è un modo per misurare la qualità dell'assistenza ai pazienti e le prestazioni di un operatore sanitario.
Per calcolare il tasso di riammissione, hai definito un indicatore, ad esempio un tasso di riammissione di 7 giorni. Questo indicatore è la percentuale di pazienti ricoverati che tornano in ospedale per una visita non programmata entro sette giorni dalla dimissione. Per prevedere la possibilità di riammissione di un paziente, un LLM ottimizzato può utilizzare i dati temporali del grafico delle conoscenze mediche in cui è stato creato. Fase 1: Previsione degli esiti dei pazienti utilizzando un grafico delle conoscenze mediche Questo Knowledge Graph conserva registrazioni cronologiche degli incontri, delle procedure, dei farmaci e dei sintomi dei pazienti. Questi record di dati contengono quanto segue:
-
Periodo di tempo trascorso dall'ultima dimissione del paziente
-
La risposta del paziente ai trattamenti e ai farmaci precedenti
-
La progressione dei sintomi o delle condizioni nel tempo
È possibile elaborare queste serie temporali per prevedere la probabilità di riammissione di un paziente tramite un prompt di sistema curato. Il prompt impartisce la logica di previsione al LLM ottimizzato.
-
Preparate i dati di input come segue:
-
Cronologia di aderenza: estrai le date di ritiro dei farmaci, le frequenze di ricarica dei farmaci, la diagnosi e i dettagli del farmaco, la storia medica cronologica e altre informazioni dal grafico delle conoscenze mediche.
-
Indicatori comportamentali: recupera e includi note cliniche sugli appuntamenti mancati e sugli effetti collaterali segnalati dai pazienti.
-
-
Crea un prompt di input che includa la cronologia di aderenza e gli indicatori comportamentali. Di seguito è riportato un prompt di esempio:
You are a highly specialized AI model trained in healthcare predictive analytics. Your task is to analyze a patient's historical medical records, clinical events, and adherence patterns to predict the **likelihood of hospital readmission** within the next few days. ### **Patient Details** - **Patient ID:** {patient_id} - **Age:** {age} - **Gender:** {gender} - **Primary Diagnoses:** {diagnoses} - **Current Medications:** {current_medications} - **Prescribed Treatments:** {prescribed_treatments} ### **Chronological Medical History** - **Recent Hospital Encounters:** {encounters} - **Time Since Last Discharge:** {time_since_last_discharge} - **Previous Readmissions:** {past_readmissions} - **Recent Lab Results & Vital Signs:** {recent_lab_results} - **Procedures Performed:** {procedures_performed} - **Prescribed Medications & Treatments:** {medications_treatments} - **Past Adherence Patterns:** {historical_adherence} - **Instances of Non-Adherence:** {past_non_adherence} ### **Patient-Specific Insights** - **Clinical Notes & Discharge Summaries:** {clinical_notes} - **Missed Appointments & Non-Compliance Patterns:** {missed_appointments} - **Patient-Reported Side Effects & Complications:** {side_effects} ### **Reasoning Process – You have to analyze this use case step-by-step.** 1. First assess **time since last discharge** and whether recent hospital encounters suggest a pattern of frequent readmissions. 2. Second examine **recent lab results, vital signs, and procedures performed** to identify clinical deterioration. 3. Third analyze **adherence history**, checking if past non-adherence to medications or treatments correlates with readmissions. 4. Then identify **missed appointments, self-reported side effects, or symptoms worsening** from clinical notes. 5. Finally predict the **likelihood of readmission** based on these contextual insights. ### **Output Format (JSON)** Return the prediction in the following structured format: ```json { "patient_id": "{patient_id}", "likelihood_of_readmission": "{low | moderate | high}", "reasoning": "{detailed_explanation_based_on_patient_history}" } -
Passa il prompt al LLM ottimizzato. L'LLM elabora la richiesta e prevede la probabilità e le ragioni della riammissione. Di seguito è riportato un esempio di risposta del LLM:
{ "patient_id": "P67890", "likelihood_of_readmission": "high", "reasoning": "The patient was discharged only 5 days ago, has a history of more than two readmissions to hospitals where the patient received treatment. Recent lab results indicate abnormal kidney function and high liver enzymes. These factors suggest a medium risk of readmission." } -
Categorizza la previsione in una scala standardizzata, ad esempio bassa, media o alta.
-
Esamina il ragionamento fornito dal LLM e identifica i fattori chiave che contribuiscono alla previsione.
-
Mappa i risultati qualitativi in punteggi quantitativi. Ad esempio, molto alto potrebbe corrispondere a una probabilità di 0,9.
-
Utilizza set di dati di convalida per calibrare gli output del modello rispetto ai tassi di riammissione effettivi.
Fase 4: Calcolo del punteggio di propensione alla riammissione in ospedale
Successivamente, si calcola un punteggio di propensione alla riammissione ospedaliera per paziente. Questo punteggio riflette l'impatto netto delle tre analisi eseguite nelle fasi precedenti: esiti potenziali per i pazienti, comportamento del paziente nei confronti di farmaci e trattamenti e probabilità di riammissione del paziente. Aggregando il punteggio di propensione alla riammissione a livello di paziente a livello di specialità e quindi a livello ospedaliero, è possibile ottenere informazioni utili a medici, responsabili dell'assistenza e amministratori. Il punteggio di propensione alla riammissione ospedaliera aiuta a valutare le prestazioni complessive per struttura, specialità o condizione. Quindi, è possibile utilizzare questo punteggio per implementare interventi proattivi.
-
Assegna dei pesi a ciascuno dei diversi fattori (previsione dei risultati, probabilità di aderenza, riammissione). Di seguito sono riportati alcuni esempi di pesi:
-
Peso della previsione del risultato: 0,4
-
Peso di previsione dell'aderenza: 0,3
-
Peso della probabilità di riammissione: 0,3
-
-
Usa il seguente calcolo per calcolare il punteggio composito:
ReadadmissionPropensityScore= (OutcomeScore×OutcomeWeight) + (AdherenceScore×AdherenceWeight) + (ReadmissionLikelihoodScore×ReadmissionLikelihoodWeight) -
Assicurati che tutti i punteggi individuali siano sulla stessa scala, ad esempio da 0 a 1.
-
Definite le soglie di azione. Ad esempio, i punteggi superiori a 0,7 avviano gli avvisi.
Sulla base delle analisi di cui sopra e del punteggio di propensione alla riammissione di un paziente, i medici o i responsabili sanitari possono impostare avvisi per monitorare i singoli pazienti in base al punteggio calcolato. Se supera una soglia predefinita, vengono avvisati quando viene raggiunta tale soglia. Questo aiuta i responsabili sanitari a essere proattivi anziché reattivi nella creazione di piani di assistenza alla dimissione per i loro pazienti. Salva i punteggi degli esiti, del comportamento e della propensione alla riammissione dei pazienti in forma indicizzata in un database vettoriale di Amazon OpenSearch Service in modo che i responsabili dell'assistenza possano recuperarli senza problemi utilizzando un agente di intelligenza artificiale conversazionale.
Il diagramma seguente mostra il flusso di lavoro di un agente di intelligenza artificiale conversazionale che un medico o un responsabile sanitario può utilizzare per recuperare informazioni sugli esiti dei pazienti, sul comportamento previsto e sulla propensione alla riammissione. Gli utenti possono recuperare informazioni a livello di paziente, di reparto o di ospedale. L'agente AI recupera queste informazioni, che vengono archiviate in forma indicizzata in un database vettoriale Amazon OpenSearch Service. L'agente utilizza la query per recuperare i dati pertinenti e fornisce risposte personalizzate, comprese le azioni suggerite per i pazienti ad alto rischio di riammissione. In base al livello di rischio, l'operatore può anche impostare promemoria per pazienti e operatori sanitari.
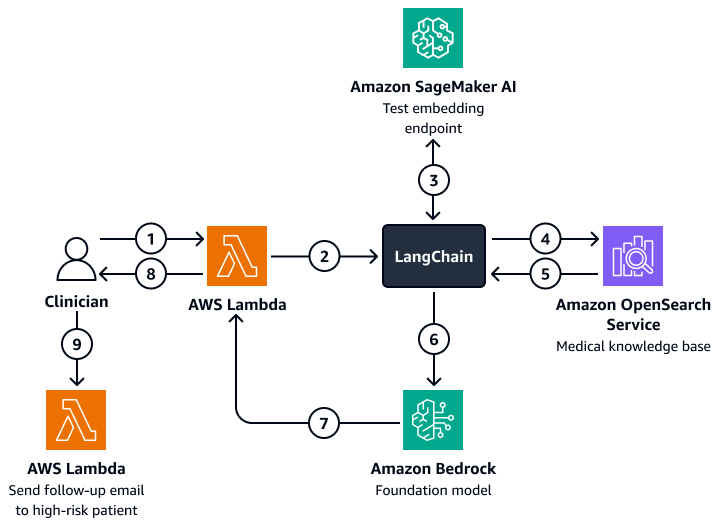
Il diagramma mostra il flusso di lavoro seguente:
-
Il medico pone una domanda a un agente di intelligenza artificiale conversazionale, che ospita una funzione. AWS Lambda
-
La funzione Lambda avvia un LangChain agente.
-
Il LangChain l'agente invia la domanda dell'utente a un endpoint di incorporamento di testo Amazon SageMaker AI. L'endpoint incorpora la domanda.
-
Il LangChain l'agente passa la domanda incorporata a una knowledge base medica in Amazon OpenSearch Service.
-
Amazon OpenSearch Service restituisce le informazioni specifiche più pertinenti alla richiesta dell'utente al LangChain agente.
-
Il LangChain agent invia la query e il contesto recuperato dalla knowledge base a un modello di base Amazon Bedrock.
-
Il modello di base Amazon Bedrock genera una risposta e la invia alla funzione Lambda.
-
La funzione Lambda restituisce la risposta al medico.
-
Il medico avvia una funzione Lambda che invia un'e-mail di follow-email a un paziente ad alto rischio di riammissione.
Allineamento al Well-Architected AWS Framework
-
Eccellenza operativa: la soluzione è un sistema automatizzato e disaccoppiato che utilizza Amazon Bedrock e AWS Lambda per avvisi in tempo reale.
-
Sicurezza: questa soluzione è progettata per rispettare le normative sanitarie, come l'HIPAA. Puoi anche implementare la crittografia, il controllo granulare degli accessi e i guardrail Amazon Bedrock per proteggere i dati dei pazienti.
-
Affidabilità: l'architettura utilizza sistemi serverless e con tolleranza ai guasti. Servizi AWS
-
Efficienza delle prestazioni: Amazon OpenSearch Service e il fine-tuned LLMs possono fornire previsioni rapide e accurate.
-
Ottimizzazione dei costi: le tecnologie e i modelli serverless aiutano a ridurre al minimo i pay-per-inference costi. Sebbene l'utilizzo di un LLM ottimizzato possa comportare costi aggiuntivi, il modello utilizza un approccio RAG che riduce i dati e il tempo di calcolo necessari per il processo di messa a punto.
-
Sostenibilità: l'architettura riduce al minimo il consumo di risorse attraverso l'uso di un'infrastruttura serverless. Supporta inoltre operazioni sanitarie efficienti e scalabili.
