Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Retriever per flussi di lavoro RAG
Questa sezione spiega come costruire un retriever. Puoi utilizzare una soluzione di ricerca semantica completamente gestita, come Amazon Kendra, oppure puoi creare una ricerca semantica personalizzata utilizzando un database vettoriale. AWS
Prima di esaminare le opzioni di retriever, assicurati di aver compreso i tre passaggi del processo di ricerca vettoriale:
-
I documenti che devono essere indicizzati vengono separati in parti più piccole. Questa operazione si chiama suddivisione in blocchi.
-
Si utilizza un processo chiamato incorporamento
per convertire ogni blocco in un vettore matematico. Quindi, indicizzate ogni vettore in un database vettoriale. L'approccio utilizzato per indicizzare i documenti influenza la velocità e la precisione della ricerca. L'approccio di indicizzazione dipende dal database vettoriale e dalle opzioni di configurazione che offre. -
La query dell'utente viene convertita in un vettore utilizzando lo stesso processo. Il retriever cerca nel database vettoriale vettori simili al vettore di query dell'utente. La somiglianza
viene calcolata utilizzando metriche come la distanza euclidea, la distanza del coseno o il prodotto scalare.
Questa guida descrive come utilizzare i seguenti servizi Servizi AWS o quelli di terze parti per creare un livello di recupero personalizzato su: AWS
Amazon Kendra
Amazon Kendra è un servizio di ricerca intelligente e completamente gestito che utilizza l'elaborazione del linguaggio naturale e algoritmi avanzati di apprendimento automatico per restituire risposte specifiche alle domande di ricerca dai tuoi dati. Amazon Kendra ti aiuta a importare direttamente documenti da più fonti e a interrogare i documenti dopo che si sono sincronizzati correttamente. Il processo di sincronizzazione crea l'infrastruttura necessaria per creare una ricerca vettoriale sul documento importato. Pertanto, Amazon Kendra non richiede i tre passaggi tradizionali del processo di ricerca vettoriale. Dopo la sincronizzazione iniziale, puoi utilizzare una pianificazione definita per gestire l'ingestione continua.
Di seguito sono riportati i vantaggi dell'utilizzo di Amazon Kendra for RAG:
-
Non è necessario mantenere un database vettoriale perché Amazon Kendra gestisce l'intero processo di ricerca vettoriale.
-
Amazon Kendra contiene connettori predefiniti per le fonti di dati più diffuse, come database, crawler di siti Web, bucket Amazon S3, istanze e istanze. Microsoft SharePoint Atlassian Confluence Sono disponibili connettori sviluppati dai AWS partner, come connettori per e. Box GitLab
-
Amazon Kendra fornisce un filtro per la lista di controllo degli accessi (ACL) che restituisce solo i documenti a cui l'utente finale ha accesso.
-
Amazon Kendra può potenziare le risposte in base ai metadati, come la data o l'archivio di origine.
L'immagine seguente mostra un'architettura di esempio che utilizza Amazon Kendra come livello di recupero del sistema RAG. Per ulteriori informazioni, consulta Crea rapidamente applicazioni di intelligenza artificiale generativa ad alta precisione su dati aziendali utilizzando Amazon Kendra LangChain e modelli linguistici di grandi dimensioni (post
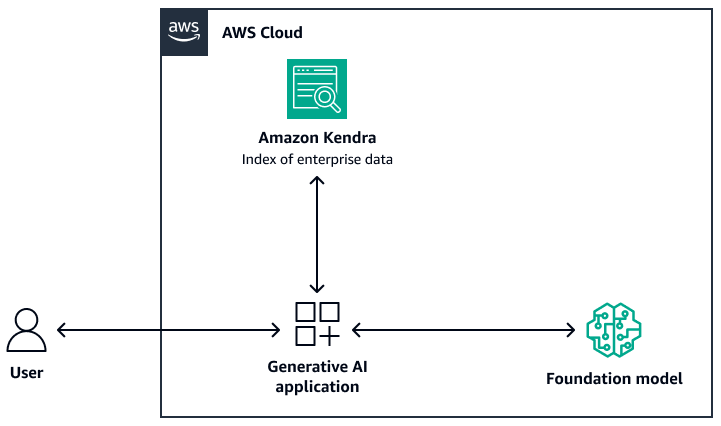
Per il modello base, puoi utilizzare Amazon Bedrock o un LLM distribuito tramite Amazon AI. SageMaker JumpStart Puoi usare AWS Lambda with LangChain
OpenSearch Servizio Amazon
Amazon OpenSearch Service fornisce algoritmi ML integrati per la ricerca k-Nearest Neighbors (k-NN) al fine di eseguire una ricerca
Di seguito sono riportati i vantaggi dell'utilizzo di Service per la ricerca vettoriale: OpenSearch
-
Fornisce il controllo completo sul database vettoriale, inclusa la creazione di una ricerca vettoriale scalabile utilizzando Serverless. OpenSearch
-
Fornisce il controllo sulla strategia di suddivisione in blocchi.
-
Utilizza algoritmi approssimativi più vicini (ANN) delle librerie Non-Metric Space Library (NMSLIB), Faiss
e Apache Lucene per alimentare una ricerca k-NN . È possibile modificare l'algoritmo in base al caso d'uso. Per ulteriori informazioni sulle opzioni per personalizzare la ricerca vettoriale tramite OpenSearch Service, consulta la spiegazione delle funzionalità del database vettoriale di Amazon OpenSearch Service (AWS post del blog). -
OpenSearch Serverless si integra con le knowledge base di Amazon Bedrock come indice vettoriale.
Amazon Aurora PostgreSQL e pgvector
Amazon Aurora PostgreSQL Compatible Edition è un motore di database relazionale completamente gestito che ti aiuta a configurare, gestire e scalare le distribuzioni PostgreSQL. pgvector è un'estensione
Di seguito sono riportati i vantaggi dell'utilizzo di pgvector e Aurora PostgreSQL compatibili:
-
Supporta la ricerca esatta e approssimativa del vicino più prossimo. Supporta anche le seguenti metriche di somiglianza: distanza L2, prodotto interno e distanza del coseno.
-
Supporta l'indicizzazione Inverted File with Flat Compression (IVFFlat)
e Hierarchical Navigable Small Worlds (HNSW). -
È possibile combinare la ricerca vettoriale con query su dati specifici del dominio disponibili nella stessa istanza PostgreSQL.
-
Aurora PostgreSQL Compatible è ottimizzata e fornisce la memorizzazione nella cache su più livelli. I/O Per carichi di lavoro che superano la memoria disponibile dell'istanza, pgvector può aumentare le query al secondo per la ricerca vettoriale fino a 8 volte.
Analisi di Amazon Neptune
Amazon Neptune Analytics è un motore di database grafico ottimizzato per la memoria per l'analisi. Supporta una libreria di algoritmi di analisi dei grafici ottimizzati, query grafiche a bassa latenza e funzionalità di ricerca vettoriale all'interno delle traversate di grafici. Dispone inoltre di una ricerca integrata per somiglianza vettoriale. Fornisce un endpoint per creare un grafico, caricare dati, richiamare query ed eseguire ricerche di somiglianza vettoriale. Per ulteriori informazioni su come creare un sistema basato su RAG che utilizza Neptune Analytics, consulta Utilizzo dei knowledge graphs per creare applicazioni GraphRag con Amazon Bedrock e Amazon
Di seguito sono riportati i vantaggi dell'utilizzo di Neptune Analytics:
-
È possibile archiviare e cercare gli incorporamenti nelle query grafiche.
-
Se integri Neptune Analytics LangChain con, questa architettura supporta le query grafiche in linguaggio naturale.
-
Questa architettura archivia grandi set di dati grafici in memoria.
Amazon MemoryDB
Amazon MemoryDB è un servizio di database in memoria durevole che offre prestazioni ultraveloci. Tutti i dati sono archiviati in memoria, che supporta la lettura in microsecondi, una latenza di scrittura di una cifra in millisecondi e un throughput elevato. La ricerca vettoriale per MemoryDB estende le funzionalità di MemoryDB e può essere utilizzata insieme alle funzionalità di MemoryDB esistenti. Per ulteriori informazioni, consulta la sezione Risposte alle domande
Il diagramma seguente mostra un'architettura di esempio che utilizza MemoryDB come database vettoriale.
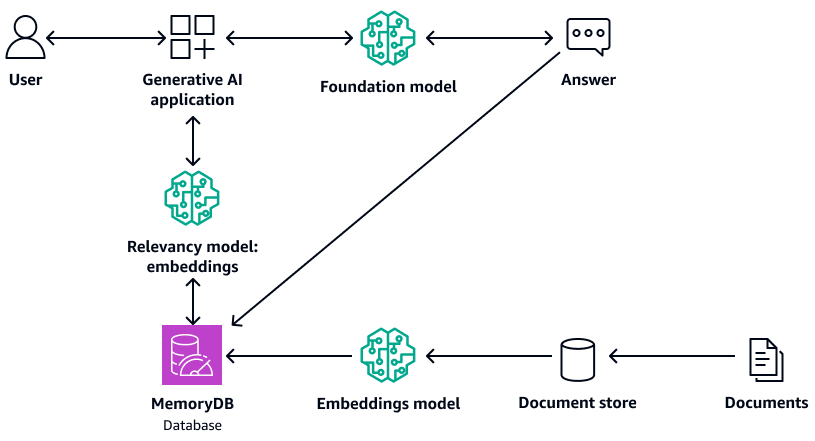
Di seguito sono riportati i vantaggi dell'utilizzo di MemoryDB:
-
Supporta algoritmi di indicizzazione sia Flat che HNSW. Per ulteriori informazioni, consulta Vector search for Amazon MemoryDB è ora disponibile a tutti nel News
Blog AWS -
Può anche fungere da memoria buffer per il modello di base. Ciò significa che le domande a cui si è risposto in precedenza vengono recuperate dal buffer anziché ripetere il processo di recupero e generazione. Il diagramma seguente mostra questo processo.
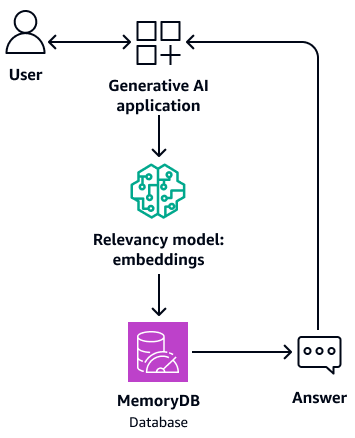
-
Poiché utilizza un database in memoria, questa architettura fornisce un tempo di interrogazione di una cifra di millisecondi per la ricerca semantica.
-
Fornisce fino a 33.000 query al secondo con un richiamo del 95-99% e 26.500 query al secondo con un richiamo superiore al 99%. Per ulteriori informazioni, guarda il video AWS re:Invent 2023 - Ricerca vettoriale a latenza ultra bassa per
Amazon MemoryDB su. YouTube
Amazon DocumentDB
Amazon DocumentDB (con compatibilità con MongoDB) è un servizio di database veloce, affidabile e completamente gestito. Semplifica la configurazione, il funzionamento e la scalabilità di database MongoDB compatibili nel cloud. La ricerca vettoriale per Amazon DocumentDB combina la flessibilità e la ricca capacità di interrogazione di un database di documenti basato su JSON con la potenza della ricerca vettoriale. Per ulteriori informazioni, consulta il repository Question response with LLM and RAG on.
Il diagramma seguente mostra un'architettura di esempio che utilizza Amazon DocumentDB come database vettoriale.
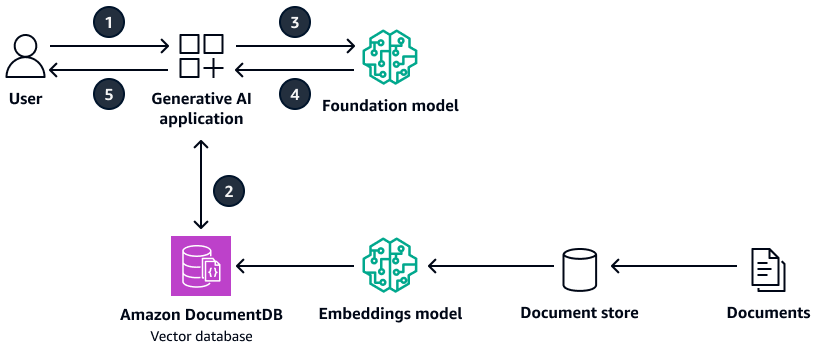
Il diagramma mostra il flusso di lavoro seguente:
-
L'utente invia una query all'applicazione AI generativa.
-
L'applicazione AI generativa esegue una ricerca di similarità nel database vettoriale Amazon DocumentDB e recupera gli estratti dei documenti pertinenti.
-
L'applicazione di intelligenza artificiale generativa aggiorna la query dell'utente con il contesto recuperato e invia il prompt al modello di base di destinazione.
-
Il modello di base utilizza il contesto per generare una risposta alla domanda dell'utente e restituisce la risposta.
-
L'applicazione AI generativa restituisce la risposta all'utente.
Di seguito sono riportati i vantaggi dell'utilizzo di Amazon DocumentDB:
-
Supporta sia i metodi HNSW che quelli di indicizzazione IVFFlat .
-
Supporta fino a 2.000 dimensioni nei dati vettoriali e supporta le metriche della distanza dei prodotti euclidei, coseni e scalari.
-
Fornisce tempi di risposta di millisecondi.
Pinecone
Pinecone
Il diagramma seguente mostra un'architettura di esempio che utilizza Pinecone come database vettoriale.
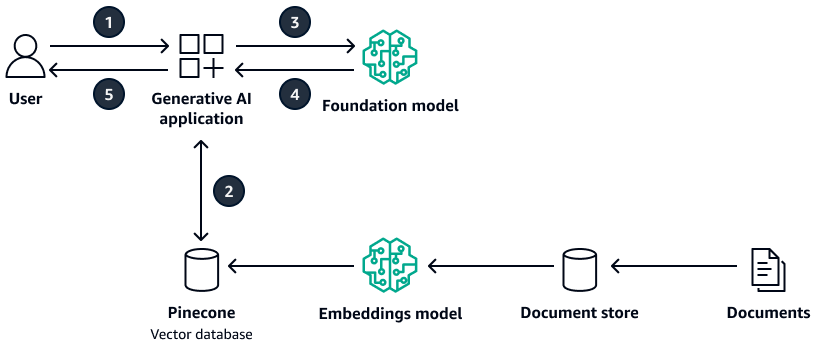
Il diagramma mostra il flusso di lavoro seguente:
-
L'utente invia una query all'applicazione AI generativa.
-
L'applicazione di intelligenza artificiale generativa esegue una ricerca di somiglianza nel database Pinecone vettoriale e recupera gli estratti dei documenti pertinenti.
-
L'applicazione di intelligenza artificiale generativa aggiorna la query dell'utente con il contesto recuperato e invia il prompt al modello di base di destinazione.
-
Il modello di base utilizza il contesto per generare una risposta alla domanda dell'utente e restituisce la risposta.
-
L'applicazione AI generativa restituisce la risposta all'utente.
Di seguito sono riportati i vantaggi dell'utilizzoPinecone:
-
È un database vettoriale completamente gestito che elimina il sovraccarico di gestione della propria infrastruttura.
-
Fornisce funzionalità aggiuntive di filtraggio, aggiornamenti in tempo reale degli indici e potenziamento delle parole chiave (ricerca ibrida).
MongoDB Atlas
MongoDB
Atlas
Per ulteriori informazioni su come utilizzare la ricerca MongoDB Atlas vettoriale per RAG, consulta Retrieval-Augmented Generation withLangChain, SageMaker Amazon JumpStart AI MongoDB Atlas e Semantic
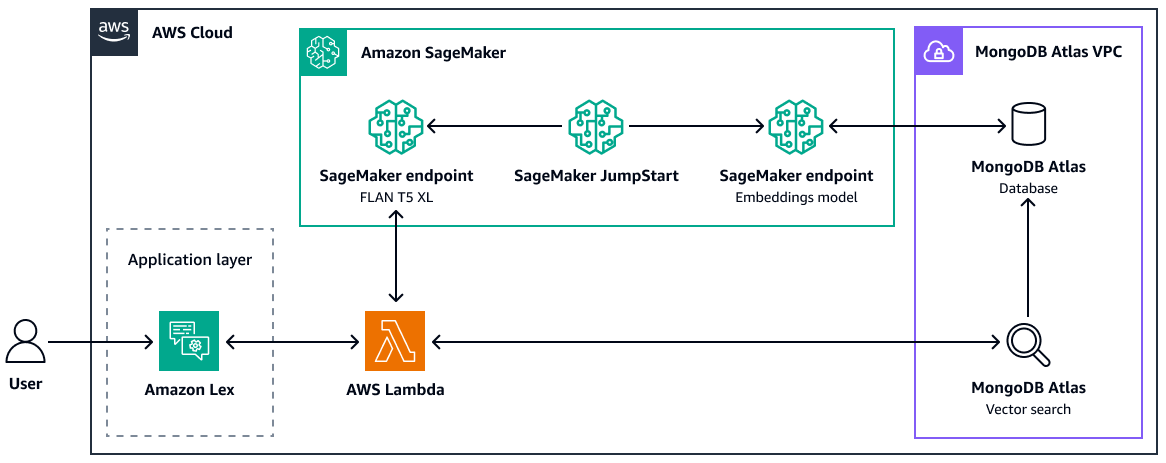
Di seguito sono riportati i vantaggi dell'utilizzo della ricerca vettoriale: MongoDB Atlas
-
È possibile utilizzare l'implementazione esistente di MongoDB Atlas per archiviare e cercare incorporamenti vettoriali.
-
È possibile utilizzare l'API MongoDB Query
per interrogare gli incorporamenti vettoriali. -
È possibile scalare in modo indipendente la ricerca vettoriale e il database.
-
Gli incorporamenti vettoriali vengono archiviati vicino ai dati di origine (documenti), il che migliora le prestazioni di indicizzazione.
Weaviate
Weaviate
Di seguito sono riportati i vantaggi dell'utilizzo: Weaviate
-
È open source e supportato da una forte comunità.
-
È progettato per la ricerca ibrida (sia vettoriali che parole chiave).
-
Puoi implementarlo AWS come offerta SaaS (Managed Software as a Service) o come cluster Kubernetes.
