Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Panoramica della soluzione
Un framework ML scalabile
In un'azienda con milioni di clienti distribuiti su più linee di business, i flussi di lavoro ML richiedono l'integrazione di dati posseduti e gestiti da team isolati che utilizzano strumenti diversi per sbloccare il valore aziendale. Le banche si impegnano a proteggere i dati dei propri clienti. Allo stesso modo, anche l'infrastruttura utilizzata per lo sviluppo di modelli ML è soggetta a elevati standard di sicurezza. Questa sicurezza aggiuntiva aggiunge ulteriore complessità e influisce sul time to value dei nuovi modelli ML. In un framework ML scalabile, è possibile utilizzare un set di strumenti modernizzato e standardizzato per ridurre lo sforzo necessario per combinare diversi strumenti e semplificare il route-to-live processo per i nuovi modelli di machine learning.
Normalmente, la gestione e il supporto delle attività di data science nel settore FS sono controllati da un team di piattaforma centrale che raccoglie i requisiti, fornisce risorse e mantiene l'infrastruttura per i team di dati in tutta l'organizzazione. Per dimensionare rapidamente l'uso del machine learning nei team federati dell'organizzazione, puoi utilizzare un framework ML scalabile per fornire funzionalità self-service agli sviluppatori di nuovi modelli e pipeline. Ciò consente a questi sviluppatori di implementare un'infrastruttura moderna, preapprovata, standardizzata e sicura. In definitiva, queste funzionalità self-service riducono la dipendenza dell'organizzazione dai team di piattaforma centralizzati e velocizzano il time-to-value per lo sviluppo di modelli di machine learning.
Il framework ML scalabile consente ai consumatori di dati (ad esempio, data scientist o ingegneri di machine learning) di sbloccare il valore aziendale offrendo loro la possibilità di fare quanto segue:
Esplorare e scoprire i dati preapprovati necessari per la formazione dei modelli
Accedere ai dati preapprovati in modo rapido e semplice
Utilizzare dati preapprovati per dimostrare la fattibilità del modello
Mettere in produzione il modello collaudato per consentirne l'utilizzo da parte di altri
Il diagramma seguente evidenzia il end-to-end flusso del framework e il percorso semplificato di utilizzo per i casi d'uso del machine learning.
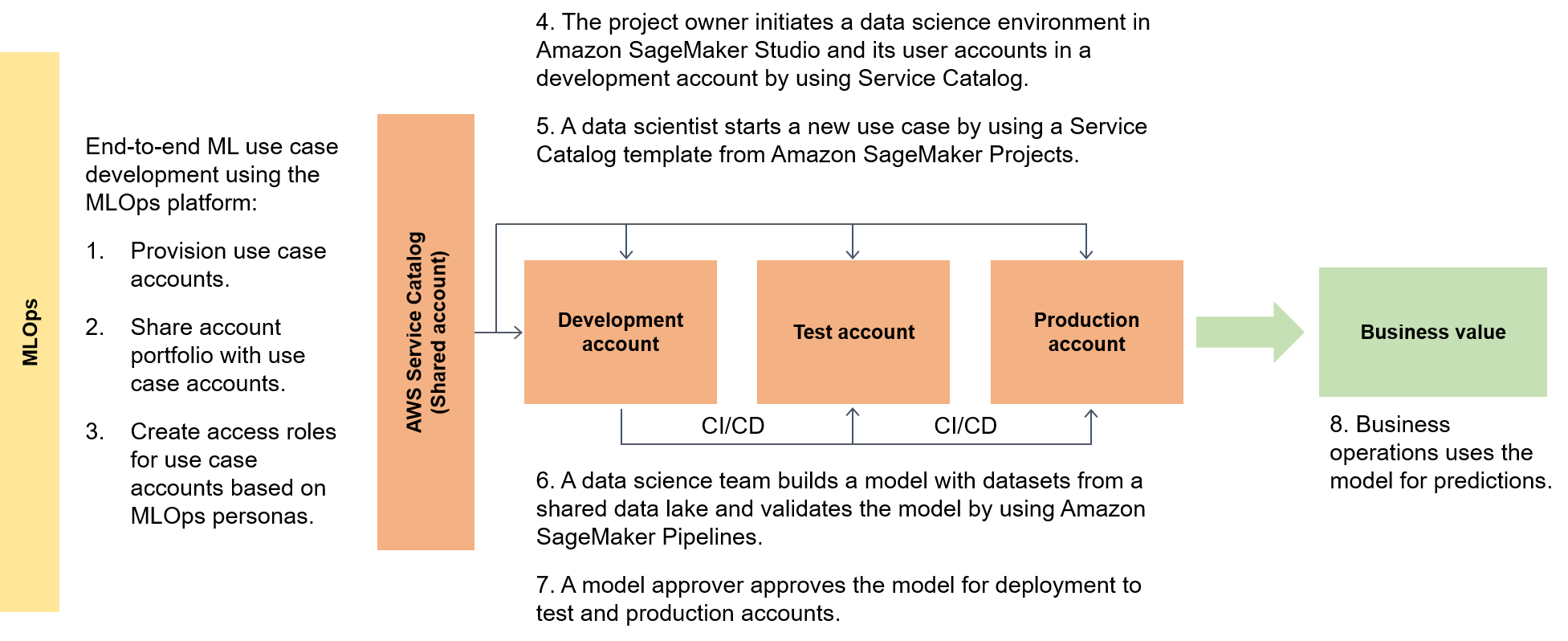
In un contesto più ampio, i consumatori di dati utilizzano un acceleratore serverless chiamato data.all per reperire dati su più data lake e quindi utilizzare i dati per addestrare i propri modelli, come illustrato nel diagramma seguente.
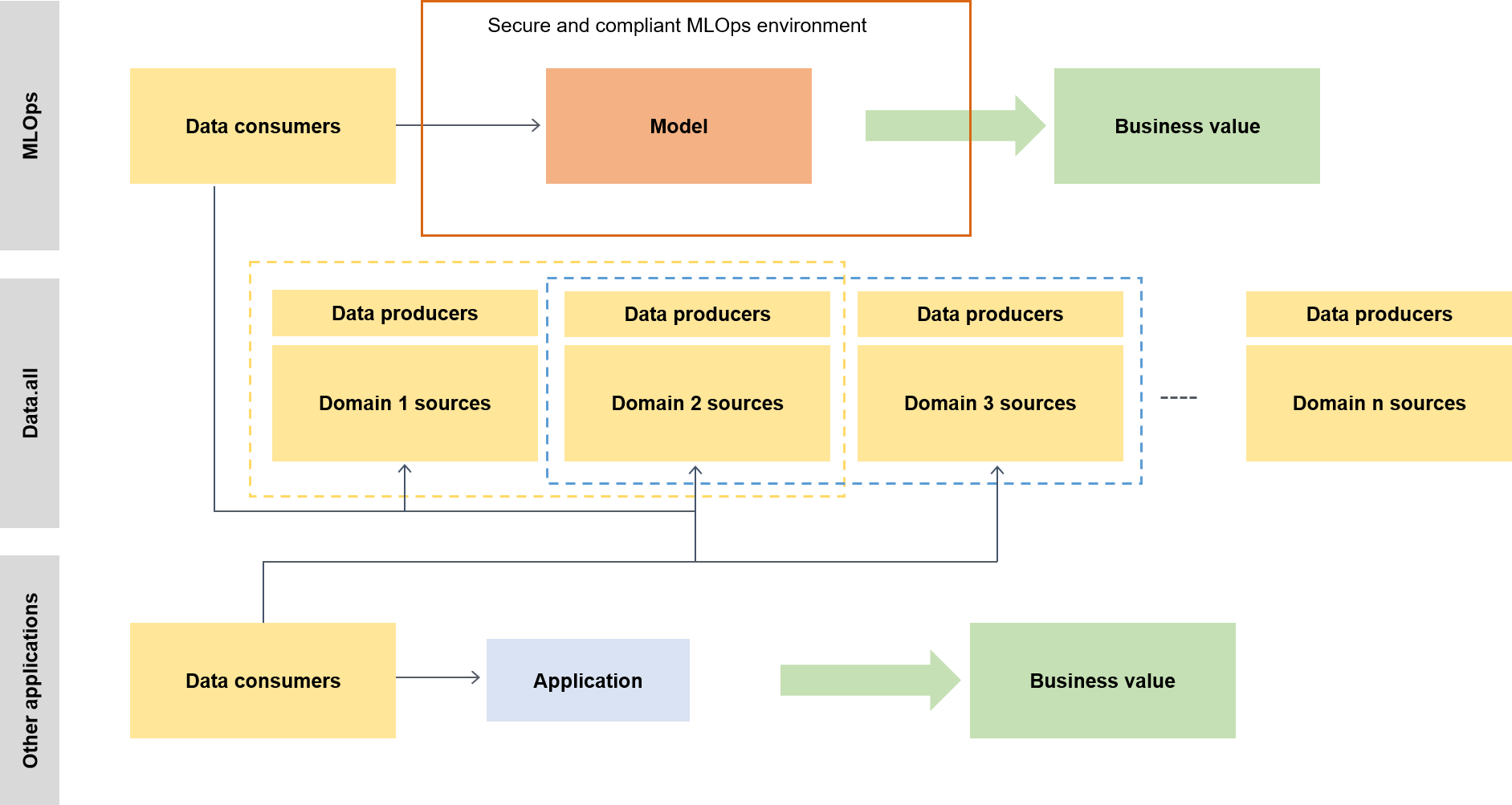
A un livello inferiore, il framework ML scalabile contiene quanto segue:
Implementazione dell'infrastruttura self-service: riduci la dipendenza dai team centralizzati.
Sistema centrale di gestione dei pacchetti Python: rendi disponibili pacchetti Python preapprovati per lo sviluppo di modelli.
Pipeline CI/CD per lo sviluppo e la promozione di modelli: riduci il time to live includendo pipeline di integrazione continua e distribuzione continua (CI/CD) come parte dei modelli di infrastruttura come codice (IaC).
Funzionalità di test dei modelli: sfrutta le funzionalità di unit test, test dei modelli, test di integrazione e end-to-end test che sono automaticamente disponibili per i nuovi modelli.
Disaccoppiamento e orchestrazione dei modelli: evita il calcolo non necessario e rendi le distribuzioni più solide disaccoppiando le fasi del modello in base ai requisiti delle risorse di calcolo e orchestrazione delle diverse fasi utilizzando Amazon AI Pipelines. SageMaker
Standardizzazione del codice: migliora la qualità del codice utilizzando l'integrazione della CI/CD pipeline per la convalida degli standard Python Enhancement
Proposal (PEP 8). Modelli ML generici con avvio rapido: ottieni modelli di Service Catalog che istanziano i tuoi ambienti di modellazione ML (sviluppo, preproduzione e produzione) e le pipeline associate con un semplice clic utilizzando AI Projects per l'implementazione. SageMaker
Monitoraggio della qualità di dati e modelli: assicurati che i tuoi modelli soddisfino i requisiti operativi e rispettino il tuo livello di tolleranza al rischio utilizzando Amazon SageMaker AI Model Monitor per monitorare automaticamente la variazione dei dati e della qualità del modello.
Monitoraggio della polarizzazione: consenti ai proprietari dei modelli di prendere decisioni giuste ed eque controllando automaticamente gli squilibri dei dati e se i cambiamenti nel mondo hanno introdotto distorsioni nel modello.
Un hub centrale per i metadati
Data.all
SageMaker convalida
Per dimostrare le capacità dell' SageMaker intelligenza artificiale in una vasta gamma di architetture di elaborazione dati e ML, il team che implementa le funzionalità seleziona, insieme al team dirigenziale del settore bancario, casi d'uso di varia complessità provenienti da diverse divisioni dei clienti bancari. I dati dei casi d'uso vengono offuscati e resi disponibili in un bucket di dati locale di Amazon Simple Storage Service (Amazon
Una volta completata la migrazione del modello dall'ambiente di formazione originale a un'architettura di SageMaker intelligenza artificiale, il data lake ospitato nel cloud rende i dati disponibili per essere letti dai modelli di produzione. Le previsioni generate dai modelli di produzione vengono quindi riscritte nel data lake.
Dopo la migrazione dei casi d'uso candidati, il framework ML scalabile utilizza un valore di riferimento iniziale per i parametri di destinazione. Puoi confrontare il valore di riferimento con le precedenti tempistiche on premise o di altri provider di servizi cloud come prova dei miglioramenti temporali consentiti dal framework ML scalabile.
