Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Rapporto di esplorazione dei dati Autopilot
Amazon SageMaker Autopilot pulisce e preelabora automaticamente il set di dati. I dati di alta qualità migliorano l'efficienza del machine learning e producono modelli che effettuano previsioni più accurate.
Esistono problemi con i set di dati forniti dal cliente che non possono essere risolti automaticamente senza il vantaggio di una conoscenza approfondita del dominio. Valori anomali elevati nella colonna di destinazione per problemi di regressione, ad esempio, possono causare previsioni non ottimali per i valori non anomali. Potrebbe essere necessario rimuovere i valori anomali a seconda dell'obiettivo di modellazione. Se una colonna di destinazione viene inclusa accidentalmente come una delle funzionalità di input, il modello finale verrà convalidato correttamente, ma avrà scarso valore per le previsioni future.
Per aiutare i clienti a scoprire questo tipo di problemi, Autopilot fornisce un report di esplorazione dei dati che contiene informazioni sui potenziali problemi relativi ai dati. Il report suggerisce anche come gestire i problemi.
Per ogni processo di Autopilot viene generato un notebook di esplorazione dei dati contenente il report. Il report è archiviato in un bucket Amazon S3 ed è accessibile dal percorso di output. Il percorso del report di esplorazione dei dati di solito segue lo schema seguente.
[s3 output path]/[name of the automl job]/sagemaker-automl-candidates/[name of processing job used for data analysis]/notebooks/SageMaker AIAutopilotDataExplorationNotebook.ipynb
La posizione del notebook per l'esplorazione dei dati può essere ottenuta dall'API Autopilot utilizzando la risposta operativa, che è memorizzata in. DescribeAutoMLJobDataExplorationNotebookLocation
Quando si esegue Autopilot di SageMaker Studio Classic, è possibile aprire il rapporto di esplorazione dei dati utilizzando i seguenti passaggi:
-
Scegli l'icona Home
 dal riquadro di navigazione a sinistra per visualizzare il menu di navigazione Amazon SageMaker Studio Classic di primo livello.
dal riquadro di navigazione a sinistra per visualizzare il menu di navigazione Amazon SageMaker Studio Classic di primo livello. -
Seleziona la scheda AutoML dall'area di lavoro principale. Si aprirà una nuova scheda Autopilot.
-
Nella sezione Nome, seleziona il processo Autopilot contenente il notebook di esplorazione dei dati che desideri esaminare. Si aprirà una nuova scheda Processo Autopilot.
-
Seleziona Apri notebook di esplorazione dei dati dalla sezione in alto a destra della scheda Processo Autopilot.
Il report di esplorazione dei dati viene generato dai dati prima dell'inizio del processo di addestramento. Ciò consente di interrompere i processi di Autopilot che potrebbero portare a risultati insignificanti. Allo stesso modo, puoi gestire eventuali problemi o miglioramenti relativi al set di dati prima di eseguire nuovamente Autopilot. In questo modo, puoi utilizzare la tua esperienza nel dominio per migliorare manualmente la qualità dei dati, prima di addestrare un modello su un set di dati meglio curato.
Il report sui dati contiene solo markdown statici e può essere aperto in qualsiasi ambiente Jupyter. Il notebook che contiene il report può essere convertito in altri formati, come PDF o HTML. Per ulteriori informazioni sulle conversioni, consulta Utilizzo dello script nbconvert per convertire i notebook Jupyter in altri formati
Argomenti
Riepilogo del set di dati
Questo Riepilogo del set di dati fornisce le statistiche chiave che caratterizzano il set di dati, tra cui il numero di righe, colonne, la percentuale di righe duplicate e i valori di destinazione mancanti. Ha lo scopo di fornirti un avviso rapido in caso di problemi con il set di dati rilevati da Amazon SageMaker Autopilot e che potrebbero richiedere il tuo intervento. Le informazioni vengono visualizzate come avvertenze classificate come di gravità “alta” o “bassa”. La classificazione dipende dal livello di certezza che il problema avrà un impatto negativo sulle prestazioni del modello.
Le informazioni sulla gravità alta e bassa vengono visualizzate nel riepilogo sotto forma di pop-up. Per la maggior parte delle informazioni, vengono forniti consigli su come confermare la presenza di un problema con il set di dati che richiede la tua attenzione. Vengono inoltre fornite proposte su come risolvere i problemi.
Autopilot fornisce statistiche aggiuntive sui valori di destinazione mancanti o non validi nel nostro set di dati per aiutarti a rilevare altri problemi che potrebbero non essere rilevati da informazioni di elevata gravità. Un numero imprevisto di colonne di un tipo particolare potrebbe indicare che alcune colonne che desideri utilizzare potrebbero mancare nel set di dati. Potrebbe anche indicare che si è verificato un problema con il modo in cui i dati sono stati preparati o archiviati. La risoluzione di questi problemi relativi ai dati segnalati alla tua attenzione da Autopilot può migliorare le prestazioni dei modelli di machine learning addestrati sui dati.
Le informazioni sulla gravità sono mostrate nella sezione di riepilogo e in altre sezioni pertinenti del report. Di solito vengono forniti esempi di informazioni di alta e bassa gravità a seconda della sezione del report dei dati.
Analisi dei dati di destinazione
In questa sezione vengono mostrati varie informazioni di alta e bassa gravità relative alla distribuzione dei valori nella colonna di destinazione. Verifica che la colonna di destinazione contenga i valori corretti. I valori errati nella colonna di destinazione probabilmente porteranno a un modello di machine learning che non serve allo scopo aziendale previsto. In questa sezione sono presenti diverse informazioni sui dati di alta e bassa gravità. Di seguito sono riportati vari esempi.
-
Valori di destinazione anomali: distribuzione distorta o insolita degli obiettivi per la regressione, ad esempio obiettivi con code pesanti.
-
Cardinalità di destinazione alta o bassa: numero poco frequente di etichette di classe o un gran numero di classi univoche per la classificazione.
Sia per i tipi di problemi di regressione che per quelli di classificazione, vengono visualizzati valori non validi come l'infinito numerico, NaN o lo spazio vuoto nella colonna di destinazione. A seconda del tipo di problema, vengono presentate statistiche diverse sui set di dati. Una distribuzione dei valori delle colonne di destinazione per un problema di regressione consente di verificare se la distribuzione è quella prevista.
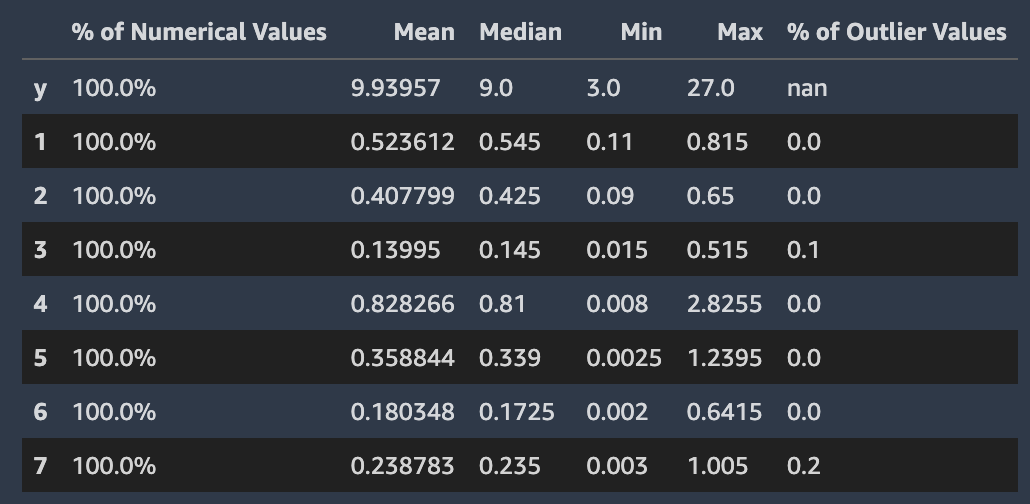
La schermata seguente mostra un report di dati di Autopilot, che include statistiche come la media, la mediana, il minimo, il massimo e la percentuale di valori anomali nel set di dati. La schermata include anche un istogramma che mostra la distribuzione delle etichette nella colonna di destinazione. L'istogramma mostra i valori della colonna di destinazione sull'asse orizzontale e il conteggio sull'asse verticale. Una casella evidenzia la sezione Percentuale di valori anomali della schermata per indicare dove appare questa statistica.

Vengono mostrate più statistiche relative ai valori di destinazione e alla loro distribuzione. Se uno qualsiasi dei valori anomali, dei valori non validi o delle percentuali di valori mancanti è maggiore di zero, questi valori vengono visualizzati in modo da poter individuare il motivo per cui i dati contengono valori di destinazione inutilizzabili. Alcuni valori di destinazione inutilizzabili vengono evidenziati come un avviso di analisi di bassa severità.
Nella schermata seguente, è stato aggiunto accidentalmente il simbolo ` nella colonna di destinazione, il che ha impedito l'analisi del valore numerico dei dati di destinazione. Viene visualizzato un avviso Informazioni di gravità bassa: “Valori di destinazione non validi”. L'avviso in questo esempio indica che «lo 0,14% delle etichette nella colonna di destinazione non può essere convertito in valori numerici. I valori non numerici più comuni sono: ["-3.8e-05","-9-05","-4.7e-05","-1.4999999999999999e-05","-4.3e-05"]. Questo di solito indica che ci sono problemi con la raccolta o l'elaborazione dei dati. Amazon SageMaker Autopilot ignora tutte le osservazioni con un'etichetta di destinazione non valida».

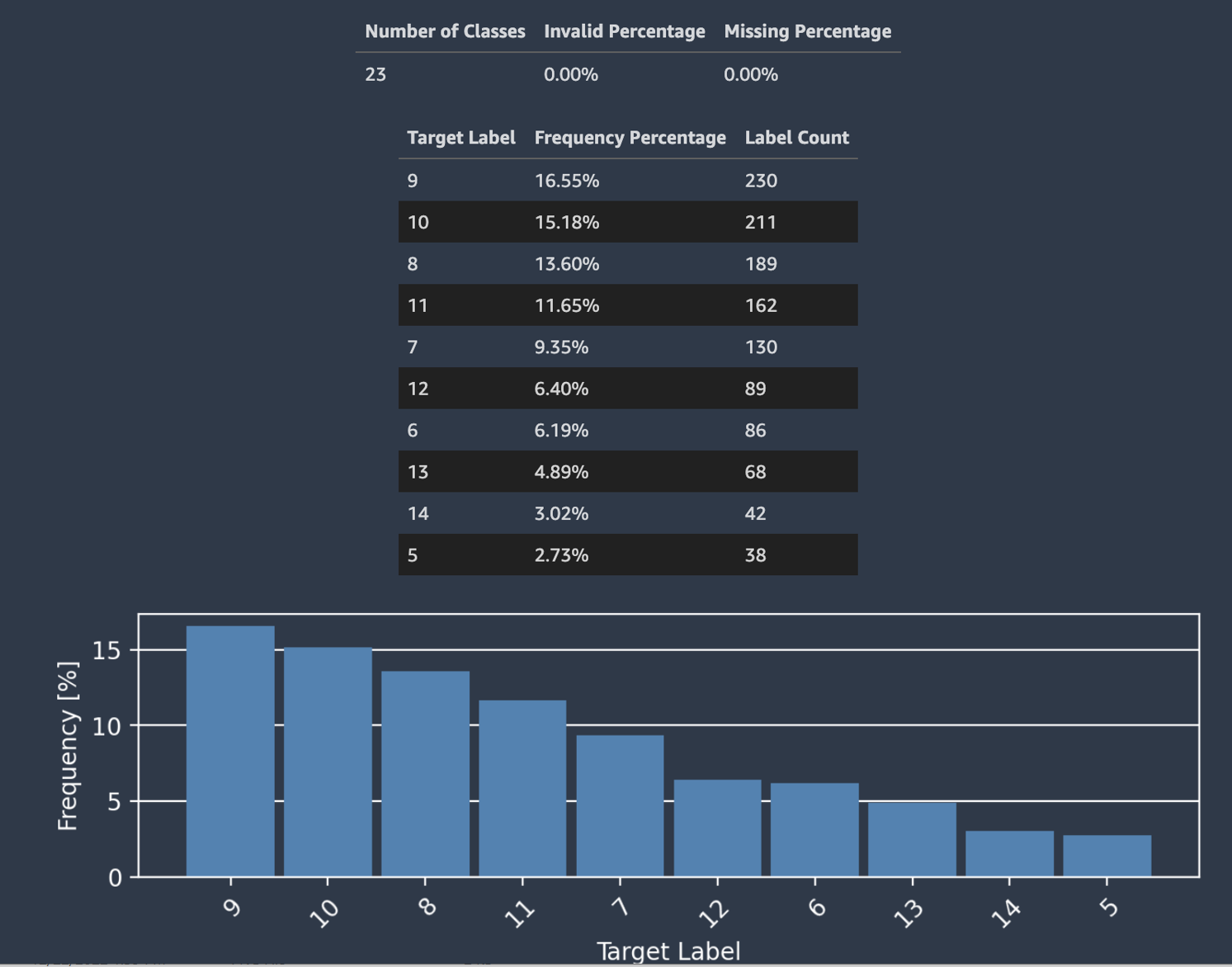
Autopilot fornisce anche un istogramma che mostra la distribuzione delle etichette per la classificazione.
La schermata seguente mostra un esempio di statistiche fornite per la colonna di destinazione, incluso il numero di classi, i valori mancanti o non validi. Un istogramma con Etichetta di destinazione sull'asse orizzontale e Frequenza sull'asse verticale mostra la distribuzione di ciascuna categoria di etichette.
Nota
Puoi trovare le definizioni di tutti i termini presentati in questa e in altre sezioni nella sezione Definizioni nella parte inferiore del notebook del report.
Dati di esempio
Autopilot presenta un campione reale dei tuoi dati per aiutarti a individuare problemi con il tuo set di dati. La tabella di esempio scorre orizzontalmente. Ispeziona i dati di esempio per verificare che tutte le colonne necessarie siano presenti nel set di dati.
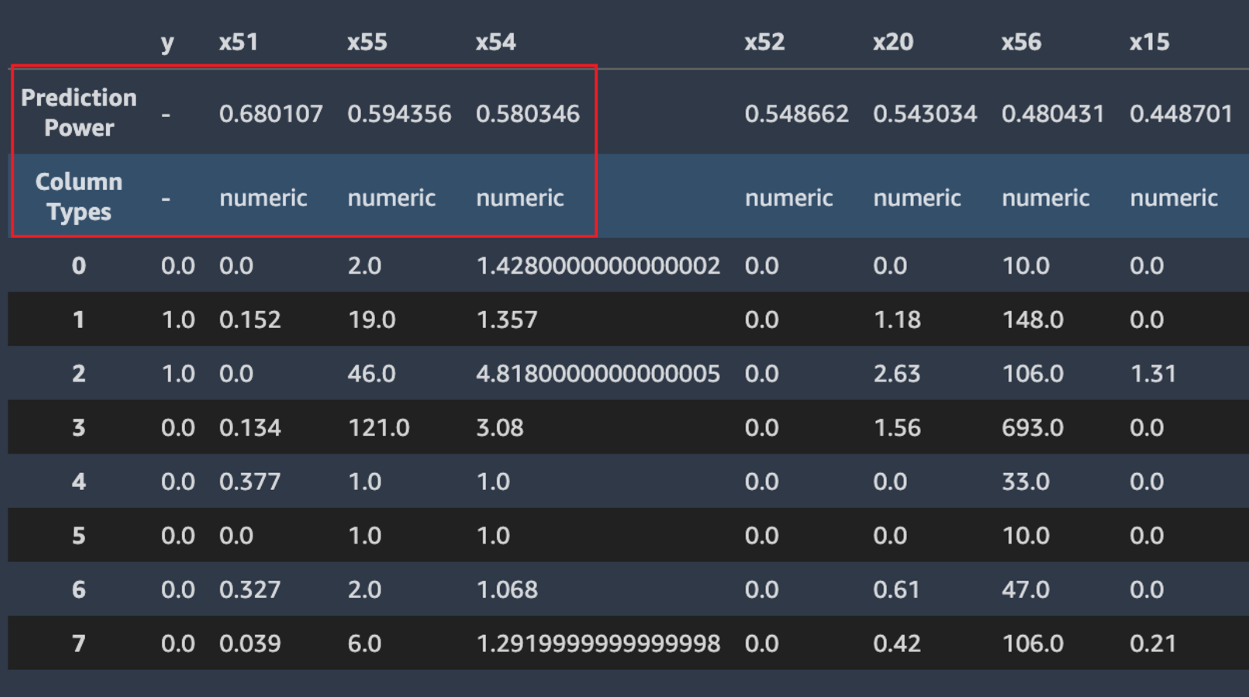
Autopilot calcola anche una misura della potenza di previsione, che può essere utilizzata per identificare una relazione lineare o non lineare tra una funzionalità e la variabile di destinazione. Un valore di 0 indica che la funzionalità non ha alcun valore predittivo nella previsione della variabile di destinazione. Un valore di 1 indica il potere predittivo più elevato per la variabile di destinazione. Per ulteriori informazioni sulla potenza predittiva, consulta la sezione Definizioni.
Nota
Non è consigliabile utilizzare la potenza di previsione come sostituto dell'importanza delle funzionalità. Usala solo se sei certo che la potenza di previsione sia una misura appropriata per il tuo caso d'uso.
La schermata seguente mostra un campione di dati di esempio. La riga superiore contiene la potenza di previsione di ogni colonna del set di dati. La seconda riga contiene il tipo di dati della colonna. Le righe successive contengono le etichette. Le colonne contengono la colonna di destinazione seguita da ogni colonna di funzionalità. Ogni colonna di funzionalità ha un potere di previsione associato, evidenziato in questa schermata, con un riquadro. In questo esempio, la colonna contenente la funzionalità x51 ha un potere predittivo di 0.68 per la variabile di destinazione y. La funzionalità x55 è leggermente meno predittiva con un potere di previsione di 0.59.
Righe duplicate
Se nel set di dati sono presenti righe duplicate, Amazon SageMaker Autopilot ne visualizza un esempio.
Nota
Non è consigliabile bilanciare un set di dati mediante un sovracampionamento prima di fornirlo ad Autopilot. Ciò può comportare punteggi di convalida imprecisi per i modelli addestrati da Autopilot e i modelli prodotti potrebbero essere inutilizzabili.
Correlazioni tra colonne
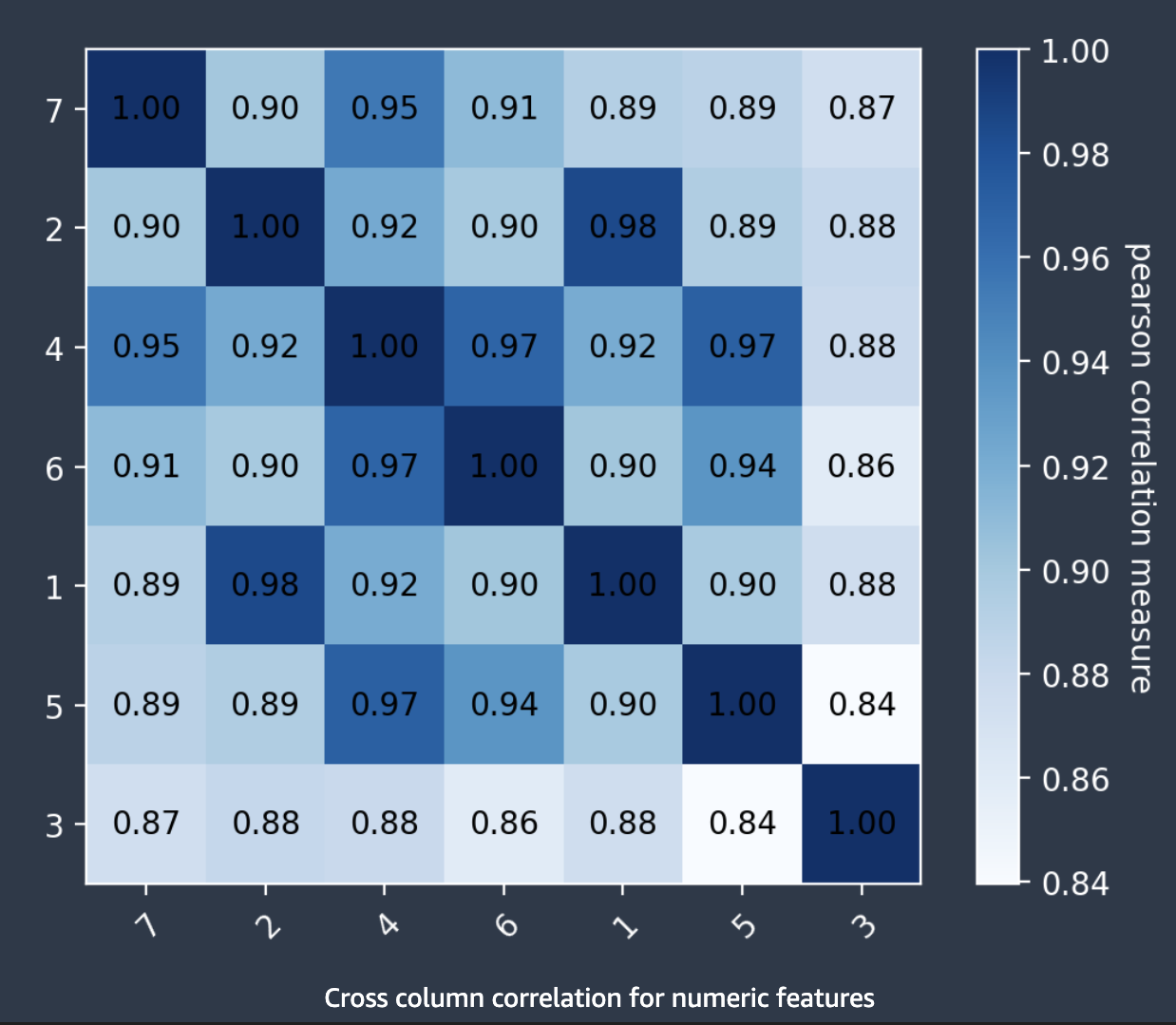
Autopilot utilizza il coefficiente di correlazione di Pearson, una misura della correlazione lineare tra due funzionalità, per compilare una matrice di correlazione. Nella matrice di correlazione, le funzionalità numeriche vengono tracciate su entrambi gli assi orizzontale e verticale, con il coefficiente di correlazione di Pearson tracciato alle loro intersezioni. Maggiore è la correlazione tra due funzionalità, maggiore è il coefficiente, con un valore massimo di |1|.
-
Un valore di
-1indica che le funzionalità sono perfettamente correlate negativamente. -
Un valore di
1, che si verifica quando una funzionalità è correlata con se stessa, indica una correlazione positiva perfetta.
È possibile utilizzare le informazioni nella matrice di correlazione per rimuovere funzionalità altamente correlate. Un numero inferiore di funzionalità riduce le possibilità di sovradimensionamento di un modello e può ridurre i costi di produzione in due modi. Riduce il runtime di Autopilot necessario e, per alcune applicazioni, può rendere più economiche le procedure di raccolta dei dati.
La schermata seguente mostra un esempio di matrice di correlazione tra 7 funzionalità. Ogni funzionalità viene visualizzata in una matrice su entrambi gli assi orizzontale e verticale. Il coefficiente di correlazione di Pearson viene visualizzato all'intersezione tra due funzionalità. A ogni intersezione di funzionalità è associata una tonalità di colore. Maggiore è la correlazione, più scura è la tonalità. Le tonalità più scure occupano la diagonale della matrice, dove ogni funzionalità è correlata a se stessa, rappresentando una correlazione perfetta.
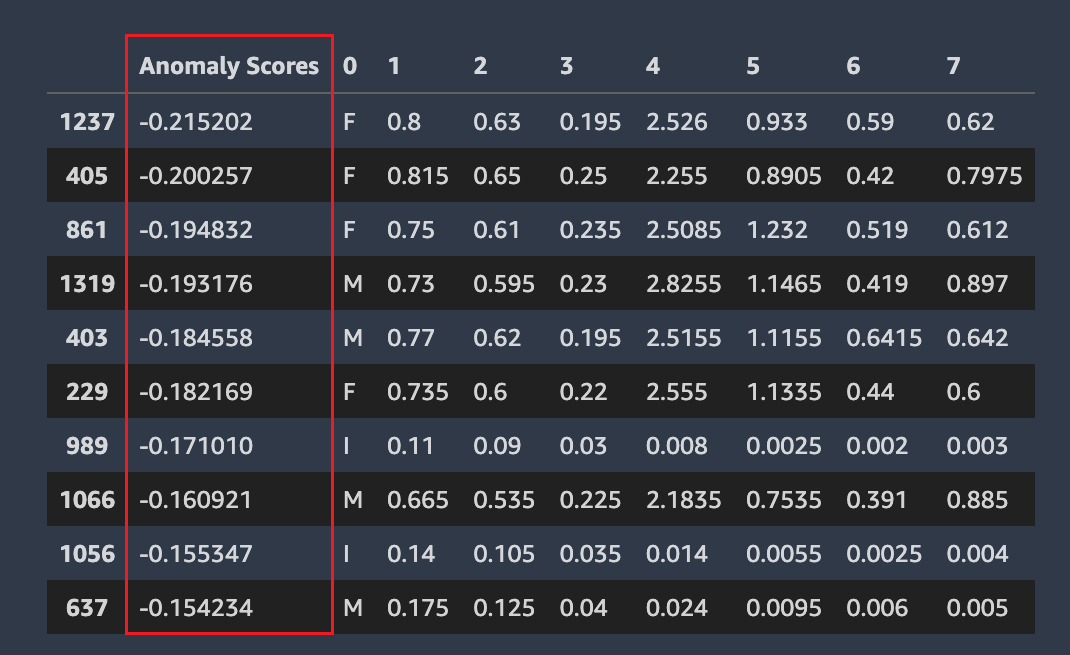
Righe anomale
Amazon SageMaker Autopilot rileva quali righe del set di dati potrebbero essere anomale. Quindi assegna un punteggio di anomalia a ciascuna riga. Le righe con punteggi di anomalia negativi sono considerate anomale.
La schermata seguente mostra l'output di un'analisi Autopilot per le righe contenenti anomalie. Una colonna contenente un punteggio anomalo viene visualizzata accanto alle colonne del set di dati per ogni riga.
Valori mancanti, cardinalità e statistiche descrittive
Amazon SageMaker Autopilot esamina e riporta le proprietà delle singole colonne del set di dati. In ogni sezione del report di dati che presenta questa analisi, il contenuto è disposto in ordine. In questo modo puoi controllare prima i valori più “sospetti”. Utilizzando queste statistiche puoi migliorare il contenuto delle singole colonne e migliorare la qualità del modello prodotto da Autopilot.
Autopilot calcola diverse statistiche sui valori categorici nelle colonne che li contengono. Questi includono il numero di voci uniche e, per il testo, il numero di parole univoche.
Autopilot calcola diverse statistiche standard sui valori numerici nelle colonne che li contengono. L'immagine seguente mostra queste statistiche, inclusi i valori medi, mediani, minimi e massimi e le percentuali dei tipi numerici e dei valori anomali.