Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Analisi e visualizzazione
Amazon SageMaker Data Wrangler include analisi integrate che ti aiutano a generare visualizzazioni e analisi dei dati in pochi clic. Puoi anche creare analisi personalizzate utilizzando il tuo codice.
Puoi aggiungere un'analisi a un dataframe selezionando una fase nel flusso di dati e quindi scegliendo Aggiungi analisi. Per accedere a un'analisi che hai creato, seleziona la fase che contiene l'analisi e seleziona l'analisi.
Tutte le analisi vengono generate utilizzando 100.000 righe del set di dati.
Puoi aggiungere l'analisi seguente a un dataframe:
-
Visualizzazioni dei dati, inclusi istogrammi e grafici a dispersione.
-
Un breve riepilogo del set di dati, incluso il numero di voci, i valori minimo e massimo (per i dati numerici) e le categorie più e meno frequenti (per i dati categoriali).
-
Un modello rapido del set di dati, che può essere utilizzato per generare un punteggio di importanza per ciascuna funzionalità.
-
Un report sulla perdita di dati, che puoi utilizzare per determinare se una o più funzionalità sono fortemente correlate alla funzionalità di destinazione.
-
Una visualizzazione personalizzata che utilizza il tuo codice.
Utilizza le seguenti sezioni per avere ulteriori informazioni su queste opzioni.
Istogramma
Utilizza gli istogrammi per visualizzare i conteggi dei valori delle funzionalità per una funzionalità specifica. Puoi esaminare le relazioni tra le funzionalità utilizzando l'opzione Colora per. Ad esempio, l'istogramma seguente mostra la distribuzione delle valutazioni degli utenti dei libri più venduti su Amazon dal 2009 al 2019, suddivise per genere.

Puoi utilizzare la funzionalità Facet per per creare istogrammi di una colonna, per ogni valore in un'altra colonna. Ad esempio, il diagramma seguente mostra gli istogrammi delle recensioni degli utenti dei libri più venduti su Amazon, se suddivise per anno.

Grafico a dispersione
Usa la funzionalità Grafico a dispersione per esaminare la relazione tra le funzionalità. Per creare un grafico a dispersione, seleziona una funzionalità da tracciare sull'asse X e sull'asse Y. Entrambe queste colonne devono essere colonne di tipo numerico.
Puoi colorare i grafici a dispersione in base a una colonna aggiuntiva. Ad esempio, l'esempio seguente mostra un grafico a dispersione che confronta il numero di recensioni con le valutazioni degli utenti dei libri più venduti su Amazon tra il 2009 e il 2019. Il grafico a dispersione è colorato in base al genere di libro.

Inoltre, puoi suddividere i grafici a dispersione in base alle funzionalità. Ad esempio, l'immagine seguente mostra un esempio dello stesso grafico a dispersione tra recensioni e valutazioni degli utenti, suddivise per anno.

Riepilogo della tabella
Utilizza l'analisi Riepilogo della tabella per riepilogare rapidamente i dati.
Per le colonne con dati numerici, inclusi dati di log e float, una tabella di riepilogo riporta il numero di voci (conteggio), minimo (min), massimo (max), di media e deviazione standard (stddev) per ogni colonna.
Per le colonne con dati non numerici, incluse le colonne con stringhe, booleani o date/time dati, un riepilogo della tabella riporta il numero di voci (conteggio), il valore meno frequente (min) e il valore più frequente (max).
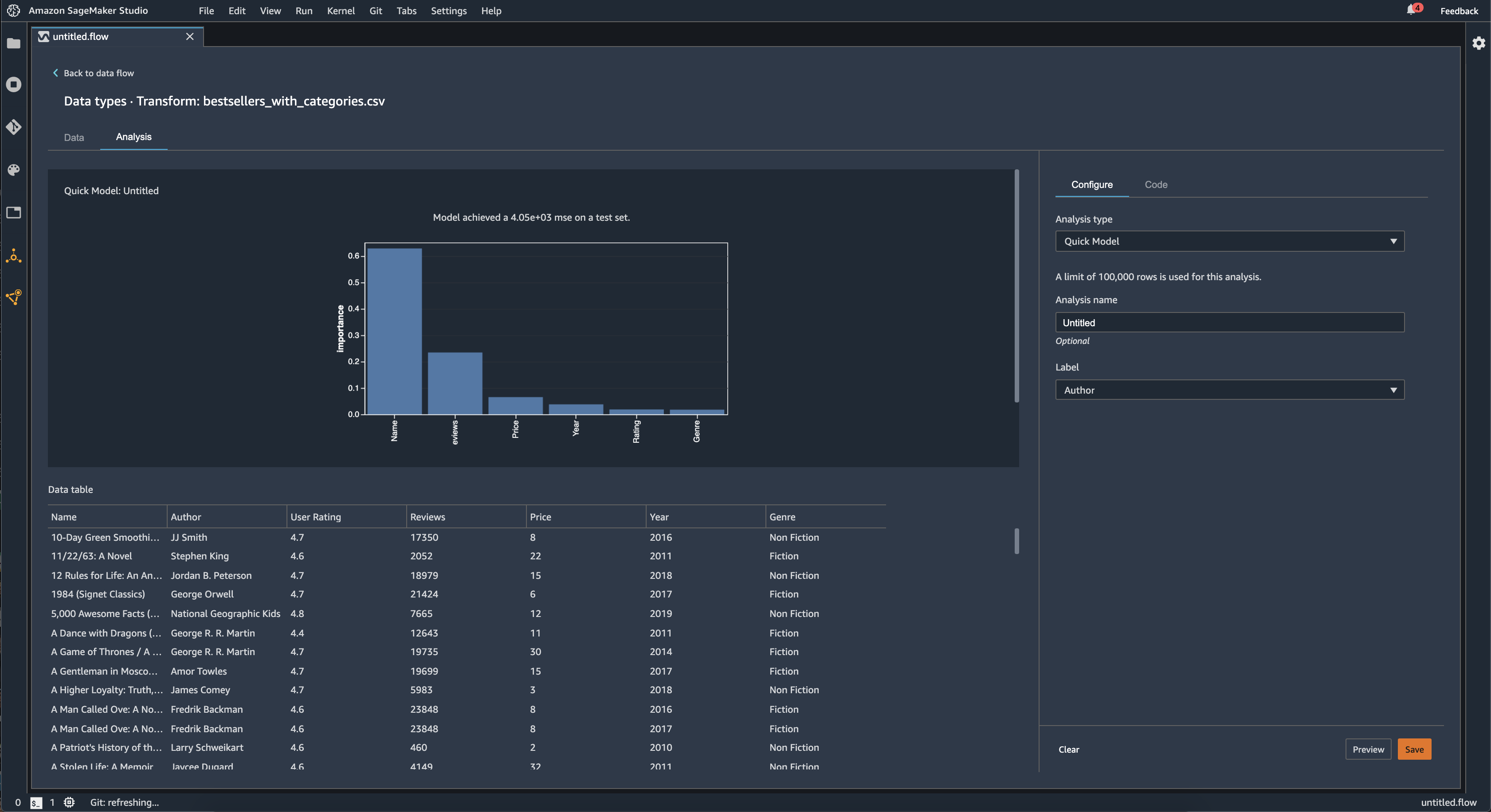
Modello rapido
Usa la visualizzazione Modello rapido per valutare rapidamente i tuoi dati e generare punteggi di importanza per ogni funzionalità. Un punteggio di importanza della funzionalità
Quando si crea un grafico di modello rapido, si seleziona un set di dati da valutare e un'etichetta di destinazione rispetto alla quale si desidera confrontare l'importanza delle funzionalità. Data Wrangler esegue le seguenti operazioni:
-
Deduce i tipi di dati per l'etichetta di destinazione e ogni funzionalità nel set di dati selezionato.
-
Determina il tipo di problema. In base al numero di valori distinti nella colonna dell'etichetta, Data Wrangler determina se si tratta di un tipo di problema di regressione o classificazione. Data Wrangler imposta una soglia categorica su 100. Se ci sono più di 100 valori distinti nella colonna dell'etichetta, Data Wrangler lo classifica come un problema di regressione; in caso contrario, viene classificato come un problema di classificazione.
-
Preelabora le funzionalità e i dati delle etichette per l’addestramento. L'algoritmo utilizzato richiede funzionalità di codifica in tipo vettoriale e etichette di codifica in doppio tipo.
-
Addestra un algoritmo forestale casuale con il 70% dei dati. Spark's RandomForestRegressor
viene utilizzato per addestrare un modello per problemi di regressione. RandomForestClassifier Viene utilizzato per addestrare un modello per problemi di classificazione. -
Valuta un modello di foresta casuale con il restante 30% di dati. Data Wrangler valuta i modelli di classificazione utilizzando un punteggio F1 e valuta i modelli di regressione utilizzando un punteggio MSE.
-
Calcola l'importanza delle funzionalità per ogni funzionalità utilizzando il metodo di importanza Gini.
L'immagine seguente mostra l'interfaccia utente per la funzionalità di modello rapido.
Perdita dei dati di destinazione
La perdita dei dati di destinazione si verifica quando in un set di dati di addestramento di machine learning sono presenti dati fortemente correlati all'etichetta di destinazione, ma non disponibili nei dati del mondo reale. Ad esempio, è possibile che nel set di dati sia presente una colonna che funge da proxy per la colonna che si desidera prevedere con il modello.
Quando utilizzi l'analisi Perdita di dati di destinazione, devi specificare quanto segue:
-
Destinazione: questa è la funzionalità in merito alla quale desideri che il tuo modello ML sia in grado di fare previsioni.
-
Tipo di problema: questo è il tipo di problema di machine learning su cui stai lavorando. Il tipo di problema può essere di classificazione o regressione.
-
(Facoltativo) Numero massimo di funzionalità: si tratta del numero massimo di funzionalità da presentare nella visualizzazione, che mostra le funzionalità classificate in base al rischio di perdita di dati.
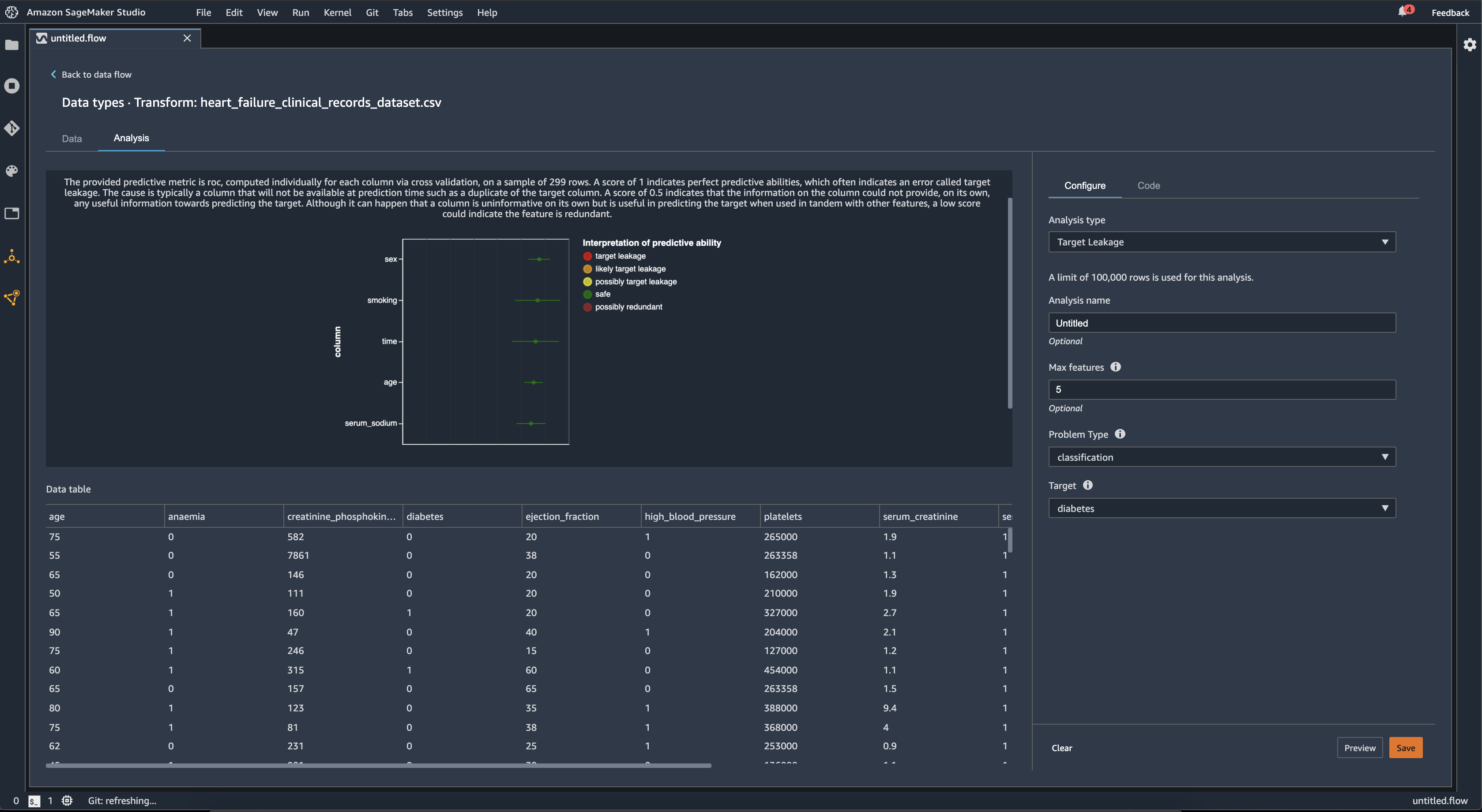
Per la classificazione, l'analisi della perdita di dati di destinazione utilizza l'area sotto la funzionalità operativa del ricevitore, o la curva AUC - ROC per ogni colonna, fino alle funzionalità max. Per la regressione, utilizza un coefficiente di determinazione, o parametro R2.
La curva AUC - ROC fornisce un parametro predittivo, calcolato individualmente per ogni colonna utilizzando la convalida incrociata, su un campione di un massimo di circa 1000 righe. Un punteggio pari a 1 indica capacità predittive perfette, il che spesso indica una perdita dei dati di destinazione. Un punteggio pari o inferiore a 0,5 indica che le informazioni sulla colonna non sono in grado di fornire, da sole, alcuna informazione utile per prevedere l'obiettivo. Anche se può succedere che una colonna di per sé non sia informativa ma sia utile per prevedere l'obiettivo se utilizzata insieme ad altre funzionalità, un punteggio basso potrebbe indicare che la funzionalità è ridondante.
Ad esempio, l'immagine seguente mostra un report sulle perdite di dati di destinazione relativo a un problema di classificazione del diabete, che consente di prevedere se una persona è affetta da diabete o meno. Una curva AUC - ROC viene utilizzata per calcolare la capacità predittiva di cinque funzionalità, e si determina che tutte sono protette da perdita di dati di destinazione.
Multicollinearità
La multicollinearità è una circostanza in cui due o più variabili predittive sono correlate tra loro. Le variabili predittive sono le funzionalità del set di dati che utilizzi per prevedere una variabile di destinazione. In presenza di multicollinearità, le variabili predittive non sono solo predittive della variabile di destinazione, ma anche predittive l'una dell'altra.
Puoi utilizzare il fattore di inflazione della varianza (Variance Inflation Factor, VIF), l’analisi delle componenti principali (Principal Component Analysis, PCA) o la selezione delle funzionalità Lasso come misure per la multicollinearità dei dati. Per ulteriori informazioni, consulta gli argomenti seguenti.
Rileva anomalie nei dati di serie temporali
Puoi utilizzare la visualizzazione del rilevamento delle anomalie per individuare i valori anomali nei dati di serie temporali. Per comprendere cosa determina un'anomalia, devi capire che scomponiamo le serie temporali in un termine previsto e un termine di errore. Consideriamo la stagionalità e l'andamento delle serie temporali come termine previsto. Trattiamo i residui come termine di errore.
Per il termine di errore, si specifica una soglia come il numero di deviazioni standard, il residuo può essere lontano dalla media perché venga considerato un'anomalia. Ad esempio, puoi specificare una soglia come 3 deviazioni standard. Qualsiasi residuo superiore a 3 deviazioni standard dalla media è un'anomalia.
È possibile utilizzare la procedura seguente per eseguire un'analisi di rilevamento delle anomalie.
-
Apri il flusso di dati Data Wrangler.
-
Nel flusso di dati, in Tipi di dati, scegli + e seleziona Aggiungi analisi.
-
Per Tipo di analisi, scegli Serie temporali.
-
Per Visualizzazione, scegli Rilevamento delle anomalie.
-
Per Soglia di anomalia, scegli la soglia per cui un valore è considerato un'anomalia.
-
Scegli Anteprima per generare un'anteprima dell'analisi.
-
Scegli Aggiungi per aggiungere la trasformazione al flusso di dati di Data Wrangler.
Scomposizione delle tendenze stagionali nei dati di serie temporali
Puoi determinare se esiste una stagionalità nei dati di serie temporali utilizzando la visualizzazione Scomposizione delle tendenze stagionali. Utilizziamo il metodo STL (Seasonal Trend decomposition using LOESS) per eseguire la scomposizione. Scomponiamo le serie temporali nelle sue componenti stagionali, di tendenza e residue. La tendenza riflette la progressione a lungo termine della serie. La componente stagionale è un segnale che ricorre in un determinato periodo di tempo. Dopo aver rimosso la tendenza e le componenti stagionali dalla serie temporale, si ottiene il residuo.
È possibile utilizzare la procedura seguente per eseguire un'analisi della scomposizione delle tendenze stagionali.
-
Apri il flusso di dati Data Wrangler.
-
Nel flusso di dati, in Tipi di dati, scegli + e seleziona Aggiungi analisi.
-
Per Tipo di analisi, scegli Serie temporali.
-
Per Visualizzazione, scegli Scomposizione delle tendenze stagionali.
-
Per Soglia di anomalia, scegli la soglia per cui un valore è considerato un'anomalia.
-
Scegli Anteprima per generare un'anteprima dell'analisi.
-
Scegli Aggiungi per aggiungere la trasformazione al flusso di dati di Data Wrangler.
Report dei bias
Puoi utilizzare il report dei bias di Data Wrangler per scoprire potenziali bias nei tuoi dati. Per generare un report dei bias, devi specificare la colonna di destinazione, o Etichetta, che desideri prevedere e un Facet, oppure la colonna che desideri controllare per individuare eventuali bias.
Etichetta: la funzionalità sulla quale desideri che un modello effettui previsioni. Ad esempio, se desideri prevedere la conversione dei clienti, puoi selezionare una colonna contenente dati relativi all'eventuale effettuazione o meno di un ordine da parte di un cliente. Devi inoltre specificare se questa funzionalità è un'etichetta o una soglia. Se specifichi un'etichetta, devi specificare l'aspetto di un risultato positivo nei dati. Nell'esempio di conversione di un cliente, un risultato positivo può essere un 1 nella colonna degli ordini, che rappresenta il risultato positivo di un cliente che ha effettuato un ordine negli ultimi tre mesi. Se specifichi una soglia, devi specificare un limite inferiore per definire un risultato positivo. Ad esempio, se le colonne relative agli ordini dei clienti contengono il numero di ordini effettuati nell'ultimo anno, potresti voler specificare 1.
Facet: la colonna da controllare per individuare eventuali bias. Ad esempio, se stai cercando di prevedere la conversione dei clienti, il facet potrebbe essere l'età del cliente. Puoi scegliere questo facet perché ritieni che i tuoi dati siano orientati verso una determinata fascia di età. Devi identificare se il facet viene misurato come valore o soglia. Ad esempio, se desideri esaminare una o più età specifiche, seleziona Valore e specifica tali età. Se vuoi esaminare una fascia di età, seleziona Soglia e specifica la soglia di età che desideri controllare.
Dopo aver selezionato la funzionalità e l'etichetta, seleziona i tipi di parametri di bias che desideri calcolare.
Per ulteriori informazioni, consulta Generare report sui bias nei dati di pre-addestramento.
Creazione di visualizzazioni personalizzate
Puoi aggiungere un'analisi al flusso di Data Wrangler per creare una visualizzazione personalizzata. Il tuo set di dati, con tutte le trasformazioni che hai applicato, è disponibile come Pandas. DataFramedf Puoi accedere al dataframe chiamando la variabile.
Devi fornire la variabile di output, chart, per memorizzare un grafico di output Altair
import altair as alt df = df.iloc[:30] df = df.rename(columns={"Age": "value"}) df = df.assign(count=df.groupby('value').value.transform('count')) df = df[["value", "count"]] base = alt.Chart(df) bar = base.mark_bar().encode(x=alt.X('value', bin=True, axis=None), y=alt.Y('count')) rule = base.mark_rule(color='red').encode( x='mean(value):Q', size=alt.value(5)) chart = bar + rule
Per creare una visualizzazione personalizzata:
-
Accanto al nodo contenente la trasformazione che desideri visualizzare, scegli +.
-
Scegli Aggiungi analisi.
-
Per Tipo di analisi, scegli Visualizzazione personalizzata.
-
Per Nome dell'analisi, specifica un nome.
-
Inserisci il codice nella casella del codice.
-
Scegli Anteprima per visualizzare in anteprima la visualizzazione.
-
Scegli Salva per aggiungere la tua visualizzazione.

Se non sai come usare il pacchetto di visualizzazione Altair in Python, puoi usare frammenti di codice personalizzati per iniziare.
Data Wrangler dispone di una raccolta ricercabile di frammenti di visualizzazione. Per utilizzare uno snippet di visualizzazione, scegli Cerca frammenti di esempio e specifica una query nella barra di ricerca.
L'esempio seguente utilizza lo snippet di codice Scatterplot Binned. Traccia un istogramma per 2 dimensioni.
Gli snippet contengono commenti per aiutarti a comprendere le modifiche da apportare al codice. In genere è necessario specificare i nomi delle colonne del set di dati nel codice.
import altair as alt # Specify the number of top rows for plotting rows_number = 1000 df = df.head(rows_number) # You can also choose bottom rows or randomly sampled rows # df = df.tail(rows_number) # df = df.sample(rows_number) chart = ( alt.Chart(df) .mark_circle() .encode( # Specify the column names for binning and number of bins for X and Y axis x=alt.X("col1:Q", bin=alt.Bin(maxbins=20)), y=alt.Y("col2:Q", bin=alt.Bin(maxbins=20)), size="count()", ) ) # :Q specifies that label column has quantitative type. # For more details on Altair typing refer to # https://altair-viz.github.io/user_guide/encoding.html#encoding-data-types
