Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Fase 4: addestrare un modello
L'SDK Amazon SageMaker Python
Argomenti
Scegliere l'algoritmo di addestramento
Per scegliere l'algoritmo giusto per il tuo set di dati, in genere devi valutare diversi modelli per trovare i modelli più adatti ai tuoi dati. Per semplicità, l'algoritmo SageMaker Usa l'algoritmo XGBoost con Amazon SageMaker integrato viene utilizzato in tutto questo tutorial senza la valutazione preliminare dei modelli.
Suggerimento
Se desideri SageMaker trovare un modello appropriato per il tuo set di dati tabulari, usa Amazon SageMaker Autopilot che automatizza una soluzione di machine learning. Per ulteriori informazioni, consulta SageMaker Pilota automatico.
Creazione ed esecuzione di un processo di addestramento
Dopo aver capito quale modello usare, inizia a costruire uno stimatore per l'addestramento. SageMaker Questo tutorial utilizza l'algoritmo integrato XGBoost per lo stimatore generico. SageMaker
Per eseguire il processo di addestramento di un modello
-
Importa l'SDK Amazon SageMaker Python
e inizia recuperando le informazioni di base dalla sessione corrente. SageMaker import sagemaker region = sagemaker.Session().boto_region_name print("AWS Region: {}".format(region)) role = sagemaker.get_execution_role() print("RoleArn: {}".format(role))Questa procedura restituisce le seguenti informazioni:
-
region— La AWS regione corrente in cui è in esecuzione l'istanza del SageMaker notebook. -
role: il ruolo IAM utilizzato dall'istanza del notebook.
Nota
Controlla la versione di SageMaker Python SDK eseguendo.
sagemaker.__version__Questo tutorial è basato susagemaker>=2.20. Se l'SDK non è aggiornato, installa la versione più recente eseguendo il seguente comando:! pip install -qU sagemakerSe esegui questa installazione nelle istanze di SageMaker Studio o notebook esistenti, devi aggiornare manualmente il kernel per completare l'applicazione dell'aggiornamento della versione.
-
-
Creazione di uno strumento di valutazione XGBoost utilizzando la classe
sagemaker.estimator.Estimator. Nel seguente codice di esempio, lo strumento di valutazione XGBoost viene denominatoxgb_model.from sagemaker.debugger import Rule, ProfilerRule, rule_configs from sagemaker.session import TrainingInput s3_output_location='s3://{}/{}/{}'.format(bucket, prefix, 'xgboost_model') container=sagemaker.image_uris.retrieve("xgboost", region, "1.2-1") print(container) xgb_model=sagemaker.estimator.Estimator( image_uri=container, role=role, instance_count=1, instance_type='ml.m4.xlarge', volume_size=5, output_path=s3_output_location, sagemaker_session=sagemaker.Session(), rules=[ Rule.sagemaker(rule_configs.create_xgboost_report()), ProfilerRule.sagemaker(rule_configs.ProfilerReport()) ] )Per costruire lo SageMaker stimatore, specificate i seguenti parametri:
-
image_uri: specifica l'URI dell'immagine del container di addestramento. In questo esempio, l'URI del contenitore di formazione SageMaker XGBoost viene specificato utilizzando.sagemaker.image_uris.retrieve -
role— Il ruolo AWS Identity and Access Management (IAM) SageMaker utilizzato per eseguire attività per tuo conto (ad esempio, leggere i risultati della formazione, chiamare gli artefatti del modello da Amazon S3 e scrivere i risultati della formazione su Amazon S3). -
instance_counteinstance_type: il tipo e il numero di istanze di calcolo ML Amazon EC2 da utilizzare per l'addestramento del modello. Per questo esercizio di addestramento, utilizza una singola istanzaml.m4.xlargecon 4 CPU, 16 GB di memoria, uno storage Amazon Elastic Block Store (Amazon EBS) e prestazioni di rete elevate. Per ulteriori informazioni sui tipi di istanze di calcolo EC2, consulta Amazon EC2 Instance Types. Per ulteriori informazioni sulla fatturazione, consulta i SageMaker prezzi di Amazon . -
volume_size: la dimensione, in GB, del volume di storage EBS da collegare all'istanza di addestramento. Deve avere spazio sufficiente per archiviare i dati di addestramento se utilizzi la modalitàFile(la modalitàFileè attivata per impostazione predefinita). Se non specifichi questo parametro, il suo valore predefinito è 30. -
output_path— Il percorso verso il bucket S3 in cui vengono SageMaker archiviati gli artefatti del modello e i risultati del training. -
sagemaker_session— L'oggetto di sessione che gestisce le interazioni con le operazioni SageMaker API e altri AWS servizi utilizzati dal processo di formazione. -
rules— Specificare un elenco di regole integrate nel SageMaker Debugger. In questo esempio, la regolacreate_xgboost_report()crea un report XGBoost che fornisce informazioni sull'avanzamento e sui risultati dell'addestramento, mentre la regolaProfilerReport()crea un report sull'utilizzo delle risorse di calcolo EC2. Per ulteriori informazioni, consulta SageMaker Report di formazione su Debugger XGBoost.
Suggerimento
Se desideri eseguire l'addestramento distribuito di modelli di deep learning di grandi dimensioni, come reti neurali convoluzionali (CNN) e modelli di elaborazione del linguaggio naturale (NLP), usa Distributed for data parallelism o model parallelism. SageMaker Per ulteriori informazioni, consulta Formazione distribuita in Amazon SageMaker.
-
-
Imposta gli iperparametri per l'algoritmo XGBoost chiamando il metodo
set_hyperparametersdello strumento di valutazione. Per un elenco completo degli iperparametri XGBoost, consulta Iperparametri XGBoost.xgb_model.set_hyperparameters( max_depth = 5, eta = 0.2, gamma = 4, min_child_weight = 6, subsample = 0.7, objective = "binary:logistic", num_round = 1000 )Suggerimento
Puoi anche regolare gli iperparametri utilizzando la funzione di ottimizzazione degli iperparametri. SageMaker Per ulteriori informazioni, consulta Esegui l'ottimizzazione automatica del modello con SageMaker.
-
Utilizza la classe
TrainingInputper configurare un flusso di input di dati per l'addestramento. Il seguente codice di esempio mostra come configurare gli oggettiTrainingInputper utilizzare i set di dati di addestramento e di convalida che hai caricato su Amazon S3 nella sezione Suddivisione del set di dati in set di dati di addestramento, di convalida e di test.from sagemaker.session import TrainingInput train_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/train.csv"), content_type="csv" ) validation_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/validation.csv"), content_type="csv" ) -
Per iniziare l'addestramento del modello, chiama il metodo
fitdello strumento di valutazione con i set di dati di addestramento e di convalida. Impostandowait=True, il metodofitvisualizza i log di avanzamento e attende il completamento dell'addestramento.xgb_model.fit({"train": train_input, "validation": validation_input}, wait=True)Per ulteriori informazioni sull’addestramento del modello, consulta Addestra un modello con Amazon SageMaker. Questo processo di addestramento del tutorial potrebbe richiedere fino a 10 minuti.
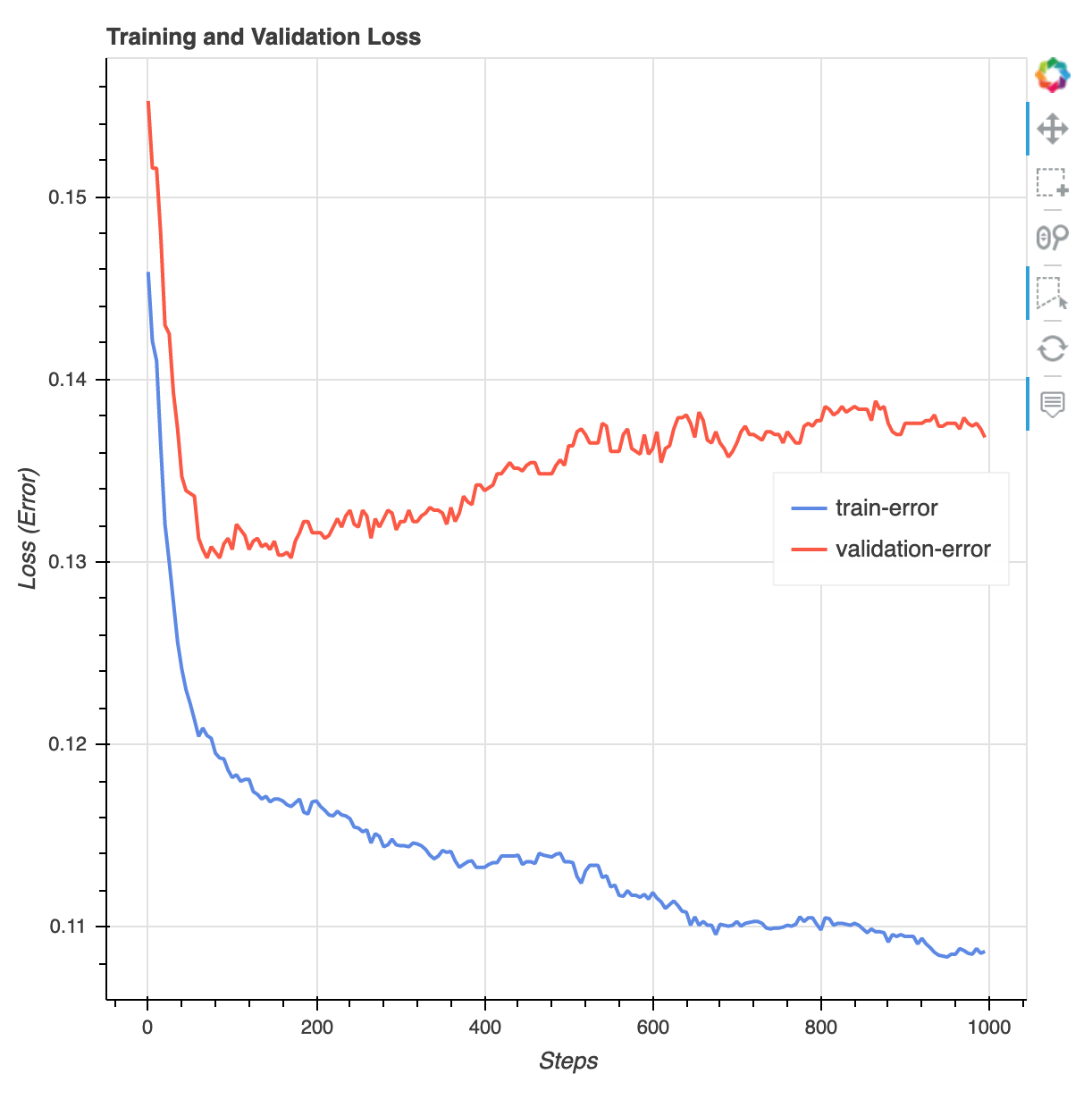
Al termine del processo di formazione, puoi scaricare un rapporto di formazione XGBoost e un rapporto di profilazione generato da Debugger. SageMaker Il report di addestramento XGBoost offre informazioni dettagliate sull'avanzamento e sui risultati dell'addestramento, ad esempio la funzione di perdita rispetto all'iterazione, l'importanza della funzionalità, la matrice di confusione, le curve di precisione e altri risultati statistici dell'addestramento. Ad esempio, puoi trovare la seguente curva di perdita del report di addestramento XGBoost che indica chiaramente che esiste un problema di overfitting.
Esegui il seguente codice per specificare l'URI del bucket S3 in cui vengono generati i report di addestramento di Debugger e controlla se i report esistono.
rule_output_path = xgb_model.output_path + "/" + xgb_model.latest_training_job.job_name + "/rule-output" ! aws s3 ls {rule_output_path} --recursiveScarica i report di addestramento e di profiling XGBoost di Debugger nel workspace corrente:
! aws s3 cp {rule_output_path} ./ --recursiveEsegui il seguente script IPython per ottenere il collegamento al file del report di addestramento XGBoost:
from IPython.display import FileLink, FileLinks display("Click link below to view the XGBoost Training report", FileLink("CreateXgboostReport/xgboost_report.html"))Il seguente script IPython restituisce il collegamento al file del report di profiling di Debugger che mostra riepiloghi e dettagli relativi a utilizzo delle risorse dell'istanza EC2, risultati del rilevamento dei colli di bottiglia del sistema e risultati di profiling delle operazioni Python:
profiler_report_name = [rule["RuleConfigurationName"] for rule in xgb_model.latest_training_job.rule_job_summary() if "Profiler" in rule["RuleConfigurationName"]][0] profiler_report_name display("Click link below to view the profiler report", FileLink(profiler_report_name+"/profiler-output/profiler-report.html"))Suggerimento
Se i report HTML non visualizzano grafici nella JupyterLab vista, è necessario scegliere Trust HTML nella parte superiore dei report.
Per identificare problemi di formazione, come l'overfit, la scomparsa dei gradienti e altri problemi che impediscono la convergenza del modello, usa SageMaker Debugger e intraprendi azioni automatiche durante la prototipazione e l'addestramento dei modelli ML. Per ulteriori informazioni, consulta Usa Amazon SageMaker Debugger per eseguire il debug e migliorare le prestazioni del modello. Per trovare un'analisi completa dei parametri del modello, consulta il notebook di esempio Explainability with Amazon SageMaker Debugger
.
Ora disponi di un modello XGBoost addestrato. SageMaker memorizza l'artefatto del modello nel tuo bucket S3. Per trovare la posizione dell'artefatto del modello, esegui il seguente codice per stampare l'attributo model_data dello strumento di valutazione xgb_model:
xgb_model.model_data
Suggerimento
Per misurare le distorsioni che possono verificarsi durante ogni fase del ciclo di vita del machine learning (raccolta dei dati, addestramento e ottimizzazione dei modelli e monitoraggio dei modelli ML implementati per la previsione), usa Clarify. SageMaker Per ulteriori informazioni, consulta Spiegabilità del modello. Per un end-to-end esempio, consultate il taccuino di esempio Fairness
