Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Crea un modello in Amazon SageMaker AI con ModelBuilder
La preparazione del modello per l'implementazione su un endpoint SageMaker AI richiede diversi passaggi, tra cui la scelta di un'immagine del modello, la configurazione dell'endpoint, la codifica delle funzioni di serializzazione e deserializzazione per trasferire dati da e verso server e client, l'identificazione delle dipendenze del modello e il caricamento su Amazon S3. ModelBuilderpuò ridurre la complessità della configurazione e della distribuzione iniziali per aiutarti a creare un modello implementabile in un unico passaggio.
ModelBuilderesegue per te le seguenti attività:
Converte i modelli di machine learning addestrati utilizzando vari framework simili XGBoost o PyTorch in modelli implementabili in un unico passaggio.
Esegue la selezione automatica dei contenitori in base al framework del modello in modo da non dover specificare manualmente il contenitore. Puoi comunque portare il tuo contenitore passando il tuo URI a
ModelBuilder.Gestisce la serializzazione dei dati sul lato client prima di inviarli al server per l'inferenza e la deserializzazione dei risultati restituiti dal server. I dati vengono formattati correttamente senza elaborazione manuale.
Consente l'acquisizione automatica delle dipendenze e impacchetta il modello in base alle aspettative del server del modello.
ModelBuilderl'acquisizione automatica delle dipendenze è l'approccio ottimale per caricare dinamicamente le dipendenze. (Si consiglia di testare l'acquisizione automatica a livello locale e di aggiornare le dipendenze per soddisfare le proprie esigenze.)Per i casi d'uso di Large Language Model (LLM), esegue facoltativamente l'ottimizzazione locale dei parametri delle proprietà di servizio che possono essere implementate per prestazioni migliori durante l'hosting su un endpoint AI. SageMaker
Supporta la maggior parte dei modelli di server e container più diffusi come Triton e TorchServe TGI container. DJLServing
Costruisci il tuo modello con ModelBuilder
ModelBuilderè una classe Python che accetta un modello di framework, come XGBoost or PyTorch, o una specifica di inferenza specificata dall'utente e lo converte in un modello implementabile. ModelBuilderfornisce una funzione di compilazione che genera gli artefatti per la distribuzione. L'artefatto del modello generato è specifico del server del modello, che potete anche specificare come uno degli input. Per ulteriori dettagli sulla ModelBuilder classe, consultate. ModelBuilder
Il diagramma seguente illustra il flusso di lavoro complessivo per la creazione del modello quando si utilizza. ModelBuilder ModelBuilderaccetta un modello o una specifica di inferenza insieme allo schema per creare un modello distribuibile che è possibile testare localmente prima della distribuzione.
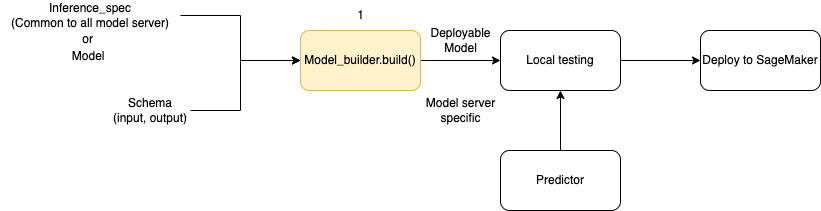
ModelBuilderè in grado di gestire qualsiasi personalizzazione che desideri applicare. Tuttavia, per implementare un modello di framework, il costruttore di modelli si aspetta almeno un modello, input e output di esempio e il ruolo. Nel seguente esempio di codice, ModelBuilder viene chiamato con un modello di framework e un'istanza di SchemaBuilder con argomenti minimi (per dedurre le funzioni corrispondenti per la serializzazione e la deserializzazione dell'input e dell'output dell'endpoint). Non viene specificato alcun contenitore e non viene passata alcuna dipendenza pacchettizzata: l'SageMaker IA deduce automaticamente queste risorse quando si crea il modello.
from sagemaker.serve.builder.model_builder import ModelBuilder from sagemaker.serve.builder.schema_builder import SchemaBuilder model_builder = ModelBuilder( model=model, schema_builder=SchemaBuilder(input, output), role_arn="execution-role", )
Il seguente esempio di codice richiama ModelBuilder con una specifica di inferenza (come InferenceSpec esempio) anziché con un modello, con personalizzazione aggiuntiva. In questo caso, la chiamata al generatore di modelli include un percorso per memorizzare gli artefatti del modello e attiva anche l'acquisizione automatica di tutte le dipendenze disponibili. Per ulteriori dettagli su, vedere. InferenceSpec Personalizza il caricamento del modello e la gestione delle richieste
model_builder = ModelBuilder( mode=Mode.LOCAL_CONTAINER, model_path=model-artifact-directory, inference_spec=your-inference-spec, schema_builder=SchemaBuilder(input, output), role_arn=execution-role, dependencies={"auto": True} )
Definire i metodi di serializzazione e deserializzazione
Quando si richiama un endpoint SageMaker AI, i dati vengono inviati tramite payload HTTP con diversi tipi MIME. Ad esempio, un'immagine inviata all'endpoint per l'inferenza deve essere convertita in byte sul lato client e inviata tramite un payload HTTP all'endpoint. Quando l'endpoint riceve il payload, deve deserializzare la stringa di byte riportandola al tipo di dati previsto dal modello (nota anche come deserializzazione lato server). Dopo che il modello ha terminato la previsione, è inoltre necessario serializzare i risultati in byte che possono essere rispediti all'utente o al client tramite il payload HTTP. Una volta ricevuti i dati dei byte di risposta, il client deve eseguire la deserializzazione lato client per riconvertire i dati in byte nel formato di dati previsto, ad esempio JSON. È necessario convertire almeno i dati per le seguenti attività:
Serializzazione delle richieste di inferenza (gestita dal client)
Deserializzazione delle richieste di inferenza (gestita dal server o dall'algoritmo)
Richiamo del modello rispetto al payload e invio del payload di risposta
Serializzazione della risposta inferenziale (gestita dal server o dall'algoritmo)
Deserializzazione della risposta di inferenza (gestita dal client)
Il diagramma seguente mostra i processi di serializzazione e deserializzazione che si verificano quando si richiama l'endpoint.
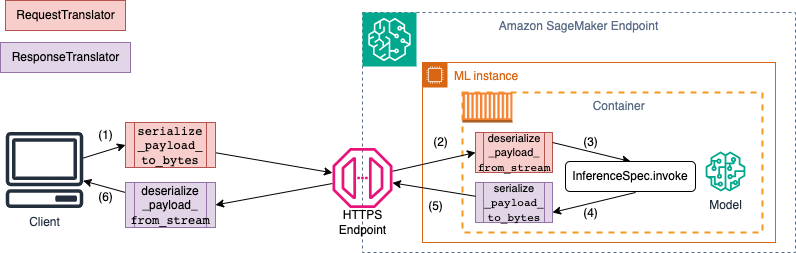
Quando si forniscono input e output di esempio aSchemaBuilder, il generatore di schemi genera le funzioni di marshalling corrispondenti per la serializzazione e la deserializzazione dell'input e dell'output. È possibile personalizzare ulteriormente le funzioni di serializzazione con. CustomPayloadTranslator Ma nella maggior parte dei casi, un serializzatore semplice come il seguente funzionerebbe:
input = "How is the demo going?" output = "Comment la démo va-t-elle?" schema = SchemaBuilder(input, output)
Per ulteriori dettagli in meritoSchemaBuilder, vedere. SchemaBuilder
Il seguente frammento di codice illustra un esempio in cui si desidera personalizzare le funzioni di serializzazione e deserializzazione sul lato client e server. È possibile definire i propri traduttori di richieste e risposte con e trasferirli a. CustomPayloadTranslator SchemaBuilder
Includendo gli input e gli output con i traduttori, il costruttore di modelli può estrarre il formato di dati previsto dal modello. Ad esempio, supponiamo che l'input di esempio sia un'immagine non elaborata e che i traduttori personalizzati ritagliino l'immagine e inviino l'immagine ritagliata al server come tensore. ModelBuildernecessita sia dell'input non elaborato che di qualsiasi codice di preelaborazione o postelaborazione personalizzato per ricavare un metodo per convertire i dati sia sul lato client che su quello server.
from sagemaker.serve import CustomPayloadTranslator # request translator class MyRequestTranslator(CustomPayloadTranslator): # This function converts the payload to bytes - happens on client side def serialize_payload_to_bytes(self, payload: object) -> bytes: # converts the input payload to bytes ... ... return //return object as bytes # This function converts the bytes to payload - happens on server side def deserialize_payload_from_stream(self, stream) -> object: # convert bytes to in-memory object ... ... return //return in-memory object # response translator class MyResponseTranslator(CustomPayloadTranslator): # This function converts the payload to bytes - happens on server side def serialize_payload_to_bytes(self, payload: object) -> bytes: # converts the response payload to bytes ... ... return //return object as bytes # This function converts the bytes to payload - happens on client side def deserialize_payload_from_stream(self, stream) -> object: # convert bytes to in-memory object ... ... return //return in-memory object
L'input e l'output di esempio vengono trasmessi insieme ai traduttori personalizzati definiti in precedenza quando si crea l'SchemaBuilderoggetto, come illustrato nell'esempio seguente:
my_schema = SchemaBuilder( sample_input=image, sample_output=output, input_translator=MyRequestTranslator(), output_translator=MyResponseTranslator() )
Quindi passate l'input e l'output di esempio, insieme ai traduttori personalizzati definiti in precedenza, all'oggetto. SchemaBuilder
my_schema = SchemaBuilder( sample_input=image, sample_output=output, input_translator=MyRequestTranslator(), output_translator=MyResponseTranslator() )
Le sezioni seguenti spiegano in dettaglio come creare un modello con le relative classi di supporto ModelBuilder e utilizzarne le classi di supporto per personalizzare l'esperienza in base al caso d'uso.
Argomenti
Personalizza il caricamento del modello e la gestione delle richieste
Fornire il proprio codice di inferenza tramite il proprio codice di inferenza InferenceSpec offre un ulteriore livello di personalizzazione. ConInferenceSpec, puoi personalizzare il modo in cui il modello viene caricato e il modo in cui gestisce le richieste di inferenza in entrata, aggirando i meccanismi di caricamento e gestione delle inferenze predefiniti. Questa flessibilità è particolarmente utile quando si lavora con modelli non standard o pipeline di inferenza personalizzate. È possibile personalizzare il invoke metodo per controllare il modo in cui il modello preelabora e postelabora le richieste in arrivo. Il invoke metodo garantisce che il modello gestisca correttamente le richieste di inferenza. L'esempio seguente utilizza InferenceSpec per generare un modello con la HuggingFace pipeline. Per ulteriori dettagli suInferenceSpec, fare riferimento a. InferenceSpec
from sagemaker.serve.spec.inference_spec import InferenceSpec from transformers import pipeline class MyInferenceSpec(InferenceSpec): def load(self, model_dir: str): return pipeline("translation_en_to_fr", model="t5-small") def invoke(self, input, model): return model(input) inf_spec = MyInferenceSpec() model_builder = ModelBuilder( inference_spec=your-inference-spec, schema_builder=SchemaBuilder(X_test, y_pred) )
L'esempio seguente illustra una variante più personalizzata di un esempio precedente. Un modello è definito con una specifica di inferenza che presenta dipendenze. In questo caso, il codice nella specifica di inferenza dipende dal pacchetto lang-segment. L'argomento for dependencies contiene un'istruzione che indica al builder di installare lang-segment usando Git. Poiché il generatore di modelli è indirizzato dall'utente all'installazione personalizzata di una dipendenza, la auto chiave è False disattivare l'acquisizione automatica delle dipendenze.
model_builder = ModelBuilder( mode=Mode.LOCAL_CONTAINER, model_path=model-artifact-directory, inference_spec=your-inference-spec, schema_builder=SchemaBuilder(input, output), role_arn=execution-role, dependencies={"auto": False, "custom": ["-e git+https://github.com/luca-medeiros/lang-segment-anything.git#egg=lang-sam"],} )
Crea il tuo modello e implementalo
Chiama la build funzione per creare il tuo modello implementabile. Questo passaggio crea un codice di inferenza nella directory di lavoro con il codice necessario per creare lo schema, eseguire la serializzazione e la deserializzazione di input e output ed eseguire altra logica personalizzata specificata dall'utente. inference.py
Come controllo di integrità, SageMaker AI impacchetta e seleziona i file necessari per l'implementazione come parte della funzione di compilazione. ModelBuilder Durante questo processo, l' SageMaker IA crea anche la firma HMAC per il file pickle e aggiunge la chiave segreta nell'CreateModelAPI come variabile di ambiente durante deploy (o). create L'avvio dell'endpoint utilizza la variabile di ambiente per convalidare l'integrità del file pickle.
# Build the model according to the model server specification and save it as files in the working directory model = model_builder.build()
Implementa il tuo modello con il metodo esistente del modello. deploy In questa fase, l' SageMaker intelligenza artificiale configura un endpoint per ospitare il modello non appena inizia a fare previsioni sulle richieste in arrivo. Sebbene ModelBuilder deduca le risorse endpoint necessarie per implementare il modello, è possibile sovrascrivere tali stime con valori di parametro personalizzati. L'esempio seguente indirizza l' SageMaker IA a implementare il modello su una singola istanza. ml.c6i.xlarge Un modello costruito in ModelBuilder consente la registrazione in tempo reale durante l'implementazione come funzionalità aggiuntiva.
predictor = model.deploy( initial_instance_count=1, instance_type="ml.c6i.xlarge" )
Se desideri un controllo più preciso sulle risorse degli endpoint assegnate al tuo modello, puoi utilizzare un oggetto. ResourceRequirements Con l'ResourceRequirementsoggetto, puoi richiedere un numero minimo di CPUs acceleratori e copie dei modelli che desideri distribuire. Puoi anche richiedere un limite minimo e massimo di memoria (in MB). Per utilizzare questa funzionalità, è necessario specificare il tipo di endpoint comeEndpointType.INFERENCE_COMPONENT_BASED. L'esempio seguente richiede quattro acceleratori, una dimensione minima di memoria di 1024 MB e una copia del modello da distribuire su un endpoint di tipo 1. EndpointType.INFERENCE_COMPONENT_BASED
resource_requirements = ResourceRequirements( requests={ "num_accelerators": 4, "memory": 1024, "copies": 1, }, limits={}, ) predictor = model.deploy( mode=Mode.SAGEMAKER_ENDPOINT, endpoint_type=EndpointType.INFERENCE_COMPONENT_BASED, resources=resource_requirements, role="role" )
Bring your own container (BYOC)
Se desideri portare il tuo contenitore (esteso da un contenitore SageMaker AI), puoi anche specificare l'URI dell'immagine come mostrato nell'esempio seguente. È inoltre necessario identificare il server modello che corrisponde all'immagine per ModelBuilder generare artefatti specifici per il server modello.
model_builder = ModelBuilder( model=model, model_server=ModelServer.TORCHSERVE, schema_builder=SchemaBuilder(X_test, y_pred), image_uri="123123123123.dkr.ecr.ap-southeast-2.amazonaws.com/byoc-image:xgb-1.7-1") )
Utilizzo ModelBuilder in modalità locale
È possibile distribuire il modello localmente utilizzando l'modeargomento per passare dal test locale alla distribuzione su un endpoint. È necessario memorizzare gli artefatti del modello nella directory di lavoro, come mostrato nel seguente frammento:
model = XGBClassifier() model.fit(X_train, y_train) model.save_model(model_dir + "/my_model.xgb")
Passate l'oggetto del modello, un'SchemaBuilderistanza e impostate la modalità su. Mode.LOCAL_CONTAINER Quando si chiama la build funzione, identifica ModelBuilder automaticamente il contenitore del framework supportato e analizza le dipendenze. L'esempio seguente mostra la creazione di un modello con un XGBoost modello in modalità locale.
model_builder_local = ModelBuilder( model=model, schema_builder=SchemaBuilder(X_test, y_pred), role_arn=execution-role, mode=Mode.LOCAL_CONTAINER ) xgb_local_builder = model_builder_local.build()
Chiamate la deploy funzione per la distribuzione locale, come illustrato nel frammento seguente. Se si specificano parametri, ad esempio type o count, questi argomenti vengono ignorati.
predictor_local = xgb_local_builder.deploy()
Risoluzione dei problemi in modalità locale
A seconda della configurazione locale individuale, è possibile che si verifichino difficoltà a ModelBuilder funzionare correttamente nell'ambiente in uso. Consulta l'elenco seguente per conoscere alcuni problemi che potresti riscontrare e come risolverli.
Già in uso: è possibile che si verifichi un
Address already in useerrore. In questo caso, è possibile che un contenitore Docker sia in esecuzione su quella porta o che un altro processo lo stia utilizzando. È possibile seguire l'approccio descritto nella documentazione di Linuxper identificare il processo e reindirizzare correttamente il processo locale dalla porta 8080 a un'altra porta o ripulire l'istanza Docker. Problema di autorizzazione IAM: potresti riscontrare un problema di autorizzazione quando tenti di estrarre un'immagine Amazon ECR o accedere ad Amazon S3. In questo caso, accedi al ruolo di esecuzione del notebook o dell'istanza Studio Classic per verificare la policy
SageMakerFullAccesso le rispettive autorizzazioni API.Problema relativo alla capacità del volume EBS: se distribuisci un modello di linguaggio di grandi dimensioni (LLM), potresti esaurire lo spazio durante l'esecuzione di Docker in modalità locale o riscontrare limitazioni di spazio per la cache Docker. In questo caso, puoi provare a spostare il volume Docker su un filesystem con spazio sufficiente. Per spostare il volume Docker, completa i seguenti passaggi:
Apri un terminale ed
dfesegui per visualizzare l'utilizzo del disco, come mostrato nel seguente output:(python3) sh-4.2$ df Filesystem 1K-blocks Used Available Use% Mounted on devtmpfs 195928700 0 195928700 0% /dev tmpfs 195939296 0 195939296 0% /dev/shm tmpfs 195939296 1048 195938248 1% /run tmpfs 195939296 0 195939296 0% /sys/fs/cgroup /dev/nvme0n1p1 141545452 135242112 6303340 96% / tmpfs 39187860 0 39187860 0% /run/user/0 /dev/nvme2n1 264055236 76594068 176644712 31% /home/ec2-user/SageMaker tmpfs 39187860 0 39187860 0% /run/user/1002 tmpfs 39187860 0 39187860 0% /run/user/1001 tmpfs 39187860 0 39187860 0% /run/user/1000Sposta la directory Docker predefinita da
/dev/nvme0n1p1a/dev/nvme2n1in in modo da poter utilizzare appieno il volume SageMaker AI da 256 GB. Per maggiori dettagli, consulta la documentazione su come spostare la directory Docker. Arresta Docker con il seguente comando:
sudo service docker stopAggiungi un
daemon.jsonblob JSON/etc/dockero aggiungi il seguente blob JSON a quello esistente.{ "data-root": "/home/ec2-user/SageMaker/{created_docker_folder}" }Sposta la directory Docker in
/home/ec2-user/SageMaker AIcon/var/lib/dockeril seguente comando:sudo rsync -aP /var/lib/docker/ /home/ec2-user/SageMaker/{created_docker_folder}Avvia Docker con il seguente comando:
sudo service docker startPulisci il cestino con il seguente comando:
cd /home/ec2-user/SageMaker/.Trash-1000/files/* sudo rm -r *Se utilizzi un'istanza di SageMaker notebook, puoi seguire i passaggi del file di preparazione Docker
per preparare Docker per la modalità locale.
ModelBuilder esempi
Per altri esempi di utilizzo per ModelBuilder creare i tuoi modelli, consulta i taccuini ModelBuilder di esempio
