Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Pipeline di un modello
Una delle caratteristiche principali della libreria di parallelismo dei modelli SageMaker è il parallelismo delle pipeline, che determina l'ordine in cui vengono eseguiti i calcoli e i dati vengono elaborati tra i dispositivi durante l'addestramento del modello. Il pipelining è una tecnica per ottenere una vera parallelizzazione nel parallelismo dei modelli, mediante l' GPUs elaborazione simultanea su diversi campioni di dati, e per superare la perdita di prestazioni dovuta al calcolo sequenziale. Quando si utilizza il parallelismo delle pipeline, il processo di addestramento viene eseguito in con pipeline su microbatch per massimizzare l'utilizzo della GPU.
Nota
Il parallelismo delle pipeline, chiamato anche partizionamento dei modelli, è disponibile per entrambi e. PyTorch TensorFlow Per le versioni supportate dei framework, consulta Framework e Regioni AWS supportati.
Pianificazione di esecuzione della pipeline
Il pipelining si basa sulla suddivisione di un mini-batch in microbatch, che vengono inseriti nella pipeline one-by-one di formazione e seguono un programma di esecuzione definito dal runtime della libreria. Un microbatch è un sottoinsieme più piccolo di un determinato mini-batch di addestramento. La pianificazione della pipeline determina quale microbatch viene eseguito da quale dispositivo per ogni fascia oraria.
Ad esempio, a seconda della pianificazione della pipeline e della partizione del modello, la GPU i potrebbe eseguire il calcolo (in avanti o all'indietro) sul microbatch mentre la GPU i+1 esegue il calcolo sul microbatch, b mantenendo così entrambi attivi contemporaneamente. b+1 GPUs Durante un singolo passaggio in avanti o indietro, il flusso di esecuzione di un singolo microbatch potrebbe visitare lo stesso dispositivo più volte, a seconda della decisione di partizionamento. Ad esempio, un'operazione che si trova all'inizio del modello potrebbe essere posizionata sullo stesso dispositivo come operazione alla fine del modello, mentre le operazioni intermedie avvengono su dispositivi diversi, il che significa che il dispositivo viene visitato due volte.
La libreria offre due diverse pianificazioni di pipeline, semplici e interlacciate, che possono essere configurate utilizzando il pipeline parametro nell'SDK Python SageMaker . Nella maggior parte dei casi, una pipeline interlacciata può ottenere prestazioni migliori utilizzando la pipeline in modo più efficiente. GPUs
Pipeline interlacciata
In una pipeline interlacciata, quando possibile, viene data priorità all'esecuzione all'indietro dei microbatch. Ciò consente un rilascio più rapido della memoria utilizzata per le attivazioni, utilizzando la memoria in modo più efficiente. Consente inoltre di aumentare il numero di microbatch, riducendo il tempo di inattività di. GPUs Allo stato stazionario, ogni dispositivo alterna passaggi in avanti e indietro. Ciò significa che il passaggio all'indietro di un microbatch può essere eseguito prima del termine del passaggio in avanti di un altro microbatch.

La figura precedente illustra un esempio di programma di esecuzione per la pipeline interlacciata su 2. GPUs Nella figura, F0 rappresenta il passaggio in avanti del microbatch 0 e B1 rappresenta il passaggio all'indietro del microbatch 1. Aggiorna rappresenta l'aggiornamento dei parametri da parte dell'ottimizzatore. GPU0 dà sempre la priorità ai passaggi all'indietro quando possibile (ad esempio, esegue B0 prima di F2), il che consente di cancellare la memoria utilizzata per le attivazioni precedenti.
Pipeline semplice
Una pipeline semplice, al contrario, termina l'esecuzione del passaggio in avanti di ogni microbatch prima di iniziare il passaggio all'indietro. Ciò significa che convoglia solo le fasi di passaggio in avanti e indietro all'interno di se stesse. La figura seguente illustra un esempio di come funziona, più di 2. GPUs

Esecuzione della pipeline in framework specifici
Utilizza le sezioni seguenti per conoscere i modelli di parallelismo utilizzati dalla libreria di parallelismo dei modelli per le decisioni di pianificazione delle pipeline specifiche del framework per e. SageMaker TensorFlow PyTorch
Esecuzione della pipeline con TensorFlow
L'immagine seguente è un esempio di un TensorFlow grafico partizionato dalla libreria di parallelismo del modello, utilizzando la suddivisione automatica del modello. Quando un grafico viene suddiviso, ogni sottografo risultante viene replicato B volte (ad eccezione delle variabili), dove B è il numero di microbatch. In questa figura, ogni grafico secondario viene replicato 2 volte (B=2). Un'operazione SMPInput viene inserita in ogni input di un grafico secondario e un'operazione SMPOutput viene inserita in ogni output. Queste operazioni comunicano con il back-end della libreria per trasferire i tensori da e verso gli altri.

L'immagine seguente è un esempio di 2 grafici secondari suddivisi con B=2 con l'aggiunta di operazioni di gradiente. Il gradiente di un'operazione SMPInput è un'operazione SMPOutput e viceversa. Ciò consente ai gradienti di fluire all'indietro durante la retropropagazione.
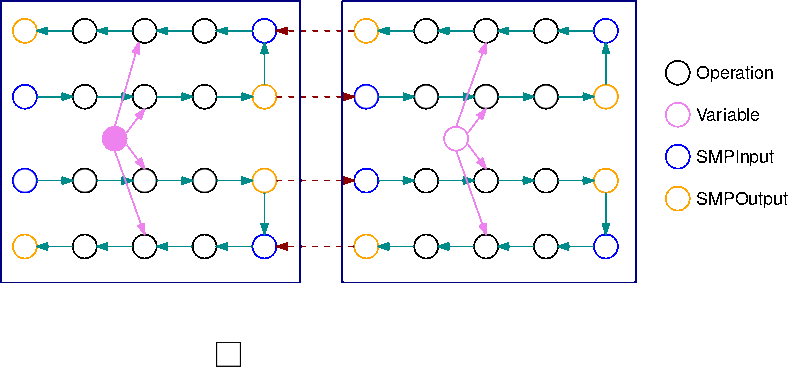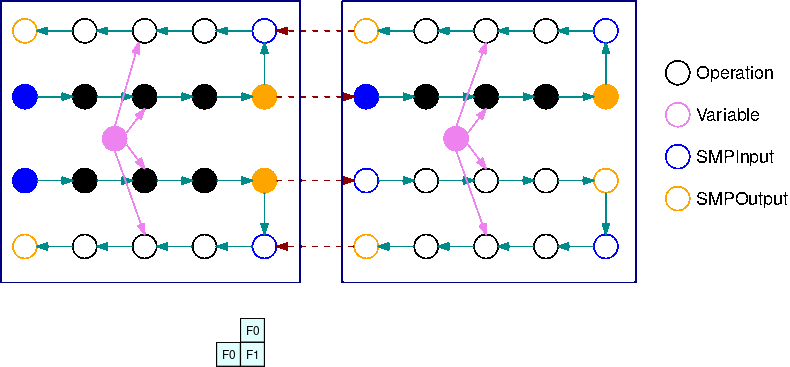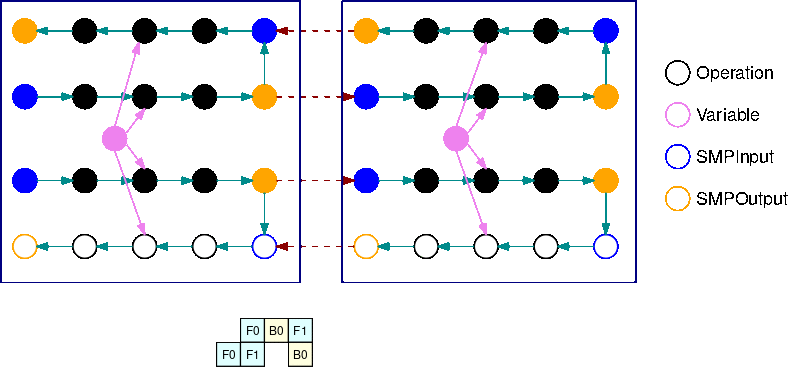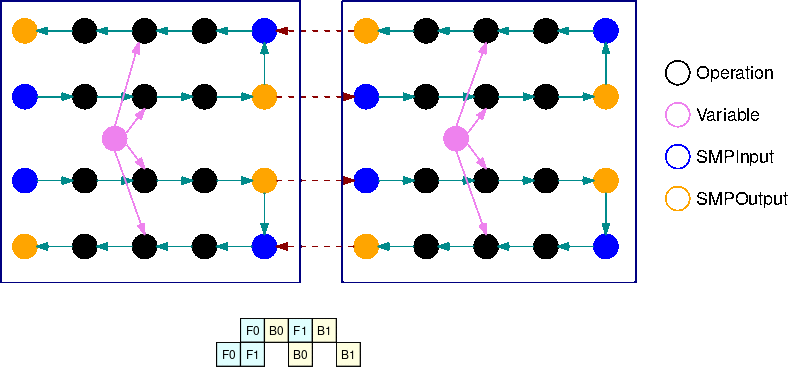
Questa GIF mostra un esempio di pianificazione di esecuzione di una pipeline interlacciata con microbatch B=2 e 2 grafici secondari. Ogni dispositivo esegue in sequenza una delle repliche dei grafici secondari per migliorare l'utilizzo della GPU. Man mano che B aumenta, la frazione degli intervalli di inattività scende a zero. Ogni volta che è il momento di eseguire calcoli (in avanti o indietro) su una specifica replica di grafico secondario, il livello della pipeline segnala alle corrispondenti operazioni blu di iniziare l'esecuzione SMPInput.
Una volta calcolati i gradienti di tutti i microbatch di un singolo mini-batch, la libreria combina i gradienti tra i microbatch, che possono quindi essere applicati ai parametri.
Esecuzione della pipeline con PyTorch
Concettualmente, il pipelining segue un'idea simile in. PyTorch Tuttavia, poiché PyTorch non prevede grafici statici, la PyTorch funzionalità della libreria di parallelismo dei modelli utilizza un paradigma di pipelining più dinamico.
Ad esempio TensorFlow, ogni batch è suddiviso in una serie di microbatch, che vengono eseguiti uno alla volta su ciascun dispositivo. Tuttavia, la pianificazione dell'esecuzione viene gestita tramite i server di esecuzione avviati su ciascun dispositivo. Ogni volta che l'output di un sottomodulo posizionato su un altro dispositivo è necessario sul dispositivo corrente, viene inviata una richiesta di esecuzione al server di esecuzione del dispositivo remoto insieme ai tensori di input al sottomodulo. Il server esegue quindi questo modulo con gli input forniti e restituisce la risposta al dispositivo corrente.
Poiché il dispositivo corrente è inattivo durante l'esecuzione del sottomodulo remoto, l'esecuzione locale del microbatch corrente viene messa in pausa e il runtime della libreria commuta l'esecuzione su un altro microbatch su cui il dispositivo corrente può lavorare attivamente. La prioritizzazione dei microbatch è determinata dalla pianificazione della pipeline scelta. Per una pianificazione di pipeline interlacciata, ai microbatch che si trovano nella fase precedente del calcolo viene data priorità ogni volta che è possibile.
