Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Panoramica delle pipeline
Una pipeline Amazon SageMaker AI è una serie di passaggi interconnessi in grafo aciclico diretto (DAG) definiti utilizzando l'interfaccia utente o l' drag-and-dropSDK Pipelines.
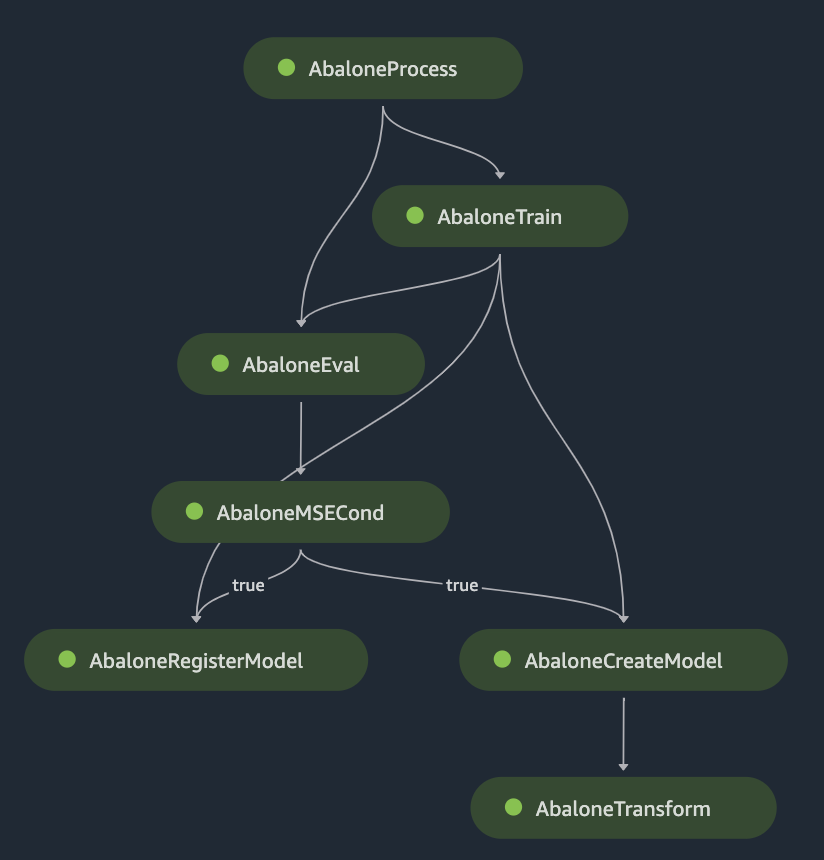
L'esempio DAG include i seguenti passaggi:
-
AbaloneProcess, un'istanza della fase Processing, esegue uno script di preelaborazione sui dati utilizzati per l'addestramento. Ad esempio, lo script può inserire i valori mancanti, normalizzare i dati numerici o suddividere i dati nei set di dati di addestramento, convalida e test. -
AbaloneTrain, un'istanza della fase di formazione, configura gli iperparametri e addestra un modello a partire dai dati di input preelaborati. -
AbaloneEval, un'altra istanza della fase Processing, valuta la precisione del modello. Questo passaggio mostra un esempio di dipendenza dai dati: questo passaggio utilizza l'output del set di dati di test di.AbaloneProcess -
AbaloneMSECondè un'istanza di una fase Condition che, in questo esempio, verifica che il mean-square-error risultato della valutazione del modello sia inferiore a un determinato limite. Se il modello non soddisfa i criteri, l'esecuzione della pipeline si interrompe. -
L'esecuzione della pipeline procede con i seguenti passaggi:
-
AbaloneRegisterModel, dove l' SageMaker intelligenza artificiale richiede una RegisterModelfase per registrare il modello come gruppo di pacchetti di modelli con versioni nell'Amazon SageMaker Model Registry. -
AbaloneCreateModel, dove l' SageMaker intelligenza artificiale prevede una CreateModelfase per creare il modello in preparazione della trasformazione in batch. NelAbaloneTransform, l' SageMaker intelligenza artificiale richiama una fase di trasformazione per generare previsioni del modello su un set di dati specificato dall'utente.
-
I seguenti argomenti descrivono i concetti fondamentali di Pipelines. Per un tutorial che descrive l'implementazione di questi concetti, consulta Azioni relative alle pipeline.
Argomenti
