Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Esplora i dati di output del profilo visualizzati nell'interfaccia utente di Profiler SageMaker
Questa sezione illustra l'interfaccia utente di SageMaker Profiler e fornisce suggerimenti su come utilizzarla e trarne informazioni.
Caricamento del profilo
Quando apri l'interfaccia utente SageMaker di Profiler, viene visualizzata la pagina Carica profilo. Per caricare e generare il pannello di controllo e la sequenza temporale, segui la procedura seguente.
Per caricare il profilo di un processo di addestramento
-
Dalla sezione Elenco dei processi di addestramento, utilizza la casella di controllo per scegliere il processo di addestramento per il quale desideri caricare il profilo.
-
Scegli Carica. Il nome del processo dovrebbe apparire nella sezione Profilo caricato nella parte superiore.
-
Scegli il pulsante di opzione a sinistra del nome del processo per generare il pannello di controllo e la sequenza temporale. Tieni presente che quando scegli il pulsante di opzione, l'interfaccia utente apre automaticamente il pannello di controllo. Tieni inoltre presente che se generi le visualizzazioni mentre lo stato del lavoro e lo stato di caricamento sembrano ancora in corso, l'interfaccia utente di SageMaker Profiler genera grafici del dashboard e una cronologia con i dati del profilo più recenti raccolti dal processo di formazione in corso o dai dati del profilo parzialmente caricati.
Suggerimento
È possibile caricare e visualizzare un profilo alla volta. Per caricare un altro profilo, devi prima scaricare il profilo precedentemente caricato. Per scaricare un profilo, utilizza l'icona del cestino all'estremità destra del profilo nella sezione Profilo caricato.
Pannello di controllo
Dopo aver completato il caricamento e la selezione del processo di addestramento, l'interfaccia utente apre la pagina Pannello di controllo, dotata, per impostazione predefinita, dei seguenti pannelli.
-
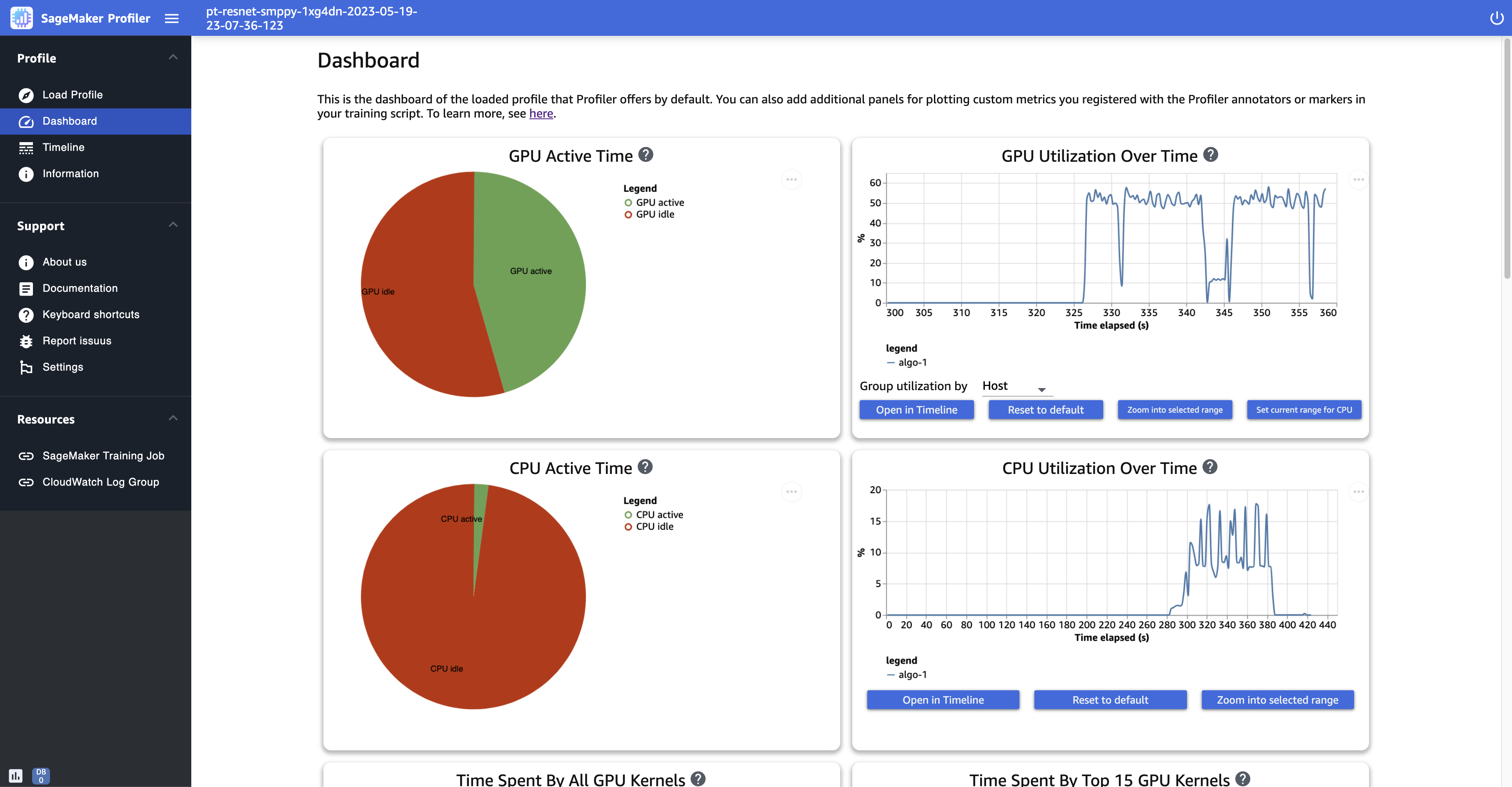
Tempo attivo della GPU: questo grafico a torta mostra la percentuale di tempo di attività rispetto al tempo di inattività della GPU. Puoi verificare se GPUs sei più attivo che inattivo durante l'intero processo di formazione. Il tempo di avvità della GPU si basa sui punti dati del profilo con un tasso di utilizzo superiore allo 0%, mentre il tempo di inattività della GPU è costituito dai punti dati profilati con un utilizzo dello 0%.
-
Utilizzo della GPU nel tempo: questo grafico di sequenza temporale mostra il tasso di utilizzo medio della GPU nel tempo per nodo, aggregando tutti i nodi in un unico grafico. Puoi verificare se GPUs hanno un carico di lavoro squilibrato, problemi di sottoutilizzo, strozzature o problemi di inattività durante determinati intervalli di tempo. Per tenere traccia del tasso di utilizzo a livello di singola GPU e delle relative esecuzioni del kernel, utilizza Interfaccia della sequenza temporale. Tieni presente che la raccolta delle attività GPU inizia dal punto in cui hai aggiunto la funzione di avvio del profilatore nello script di addestramento e
SMProf.start_profiling()si ferma inSMProf.stop_profiling(). -
Tempo di attività della CPU: questo grafico a torta mostra la percentuale di tempo di attività rispetto al tempo di inattività della GPU. Puoi verificare se sei più attivo che inattivo durante l'intero processo di CPUs formazione. Il tempo di avvità della CPU si basa sui punti dati profilati con un tasso di utilizzo superiore allo 0%, mentre il tempo di inattività della CPU è costituito dai punti dati profilati con un utilizzo dello 0%.
-
Utilizzo della CPU nel tempo: questo grafico di sequenza temporale mostra il tasso di utilizzo medio della CPU nel tempo per nodo, aggregando tutti i nodi in un unico grafico. È possibile verificare se CPUs sono bloccate o sottoutilizzate durante determinati intervalli di tempo. Per tenere traccia del tasso di utilizzo in CPUs linea con l'utilizzo della singola GPU e le esecuzioni del kernel, usa il. Interfaccia della sequenza temporale Tieni presente che i parametri di utilizzo iniziano dall'inizio dell'inizializzazione del processo.
-
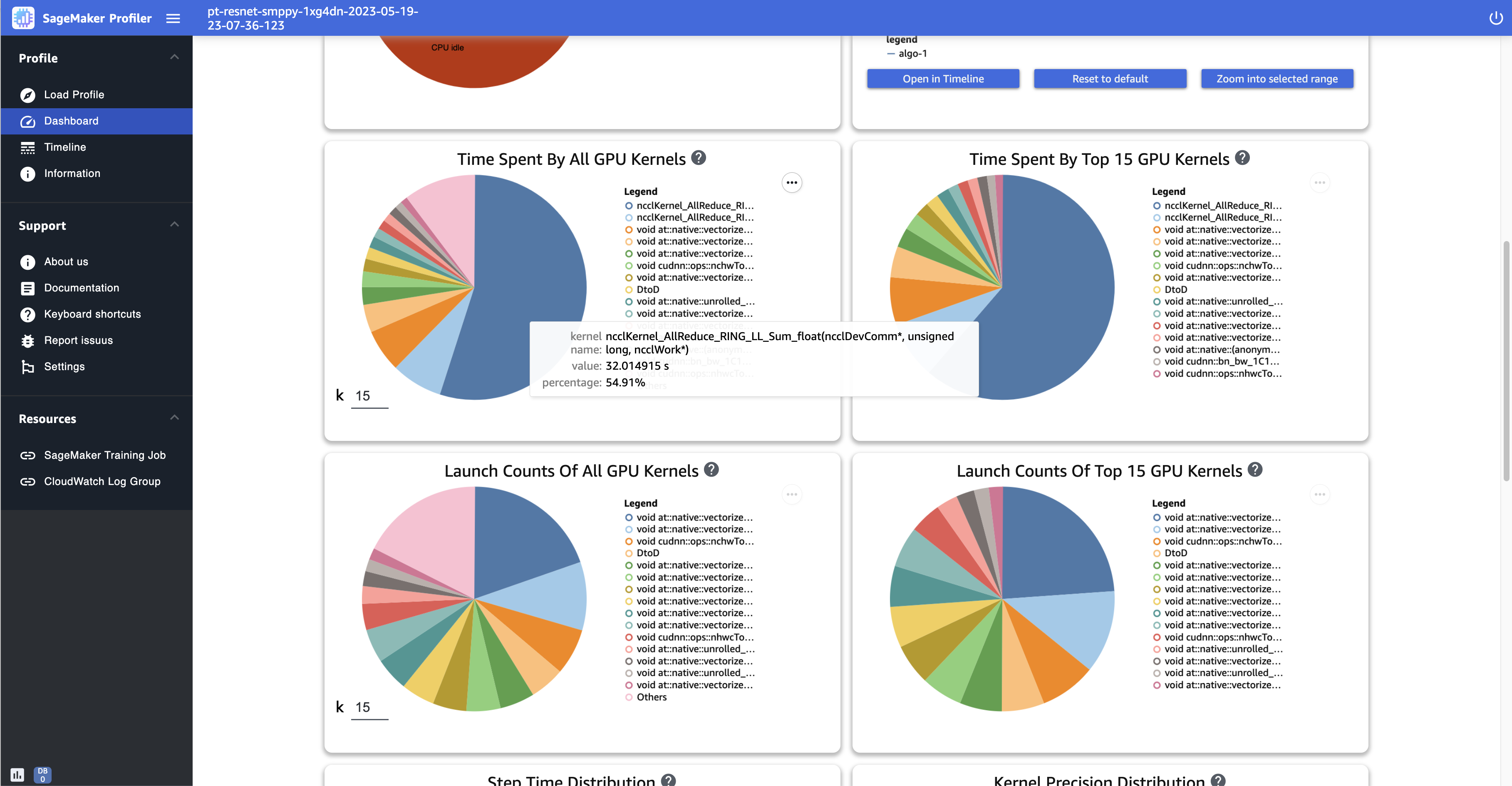
Tempo impiegato da tutti i kernel GPU: questo grafico a torta mostra tutti i kernel della GPU utilizzati durante il processo di addestramento. Per impostazione predefinita, mostra i 15 principali kernel della GPU come singoli settori e tutti gli altri kernel in un settore. Passa il mouse sui settori per visualizzare informazioni più dettagliate. Il valore mostra il tempo totale di funzionamento dei kernel della GPU in secondi, mentre la percentuale si basa sull'intero tempo del profilo.
-
Tempo impiegato dai 15 principali kernel GPU: questo grafico a torta mostra tutti i kernel della GPU utilizzati durante il processo di addestramento. Mostra i 15 principali kernel GPU suddivisi per singoli settori. Passa il mouse sui settori per visualizzare informazioni più dettagliate. Il valore mostra il tempo totale di funzionamento dei kernel della GPU in secondi, mentre la percentuale si basa sull'intero tempo del profilo.
-
Numero di lanci di tutti i kernel GPU: questo grafico a torta mostra il numero di conteggi per ogni kernel GPU lanciato durante il processo di addestramento. Mostra i 15 principali kernel della GPU come singoli settori e tutti gli altri kernel in un settore. Passa il mouse sui settori per visualizzare informazioni più dettagliate. Il valore mostra il numero totale dei kernel GPU lanciati e la percentuale si basa sul conteggio totale di tutti i kernel.
-
Numero di lanci dei 15 principali kernel GPU: questo grafico a torta mostra il numero di conteggi di ogni kernel GPU lanciato durante il processo di addestramento. Mostra i 15 principali kernel GPU. Passa il mouse sui settori per visualizzare informazioni più dettagliate. Il valore mostra il numero totale dei kernel GPU lanciati e la percentuale si basa sul conteggio totale di tutti i kernel.
-
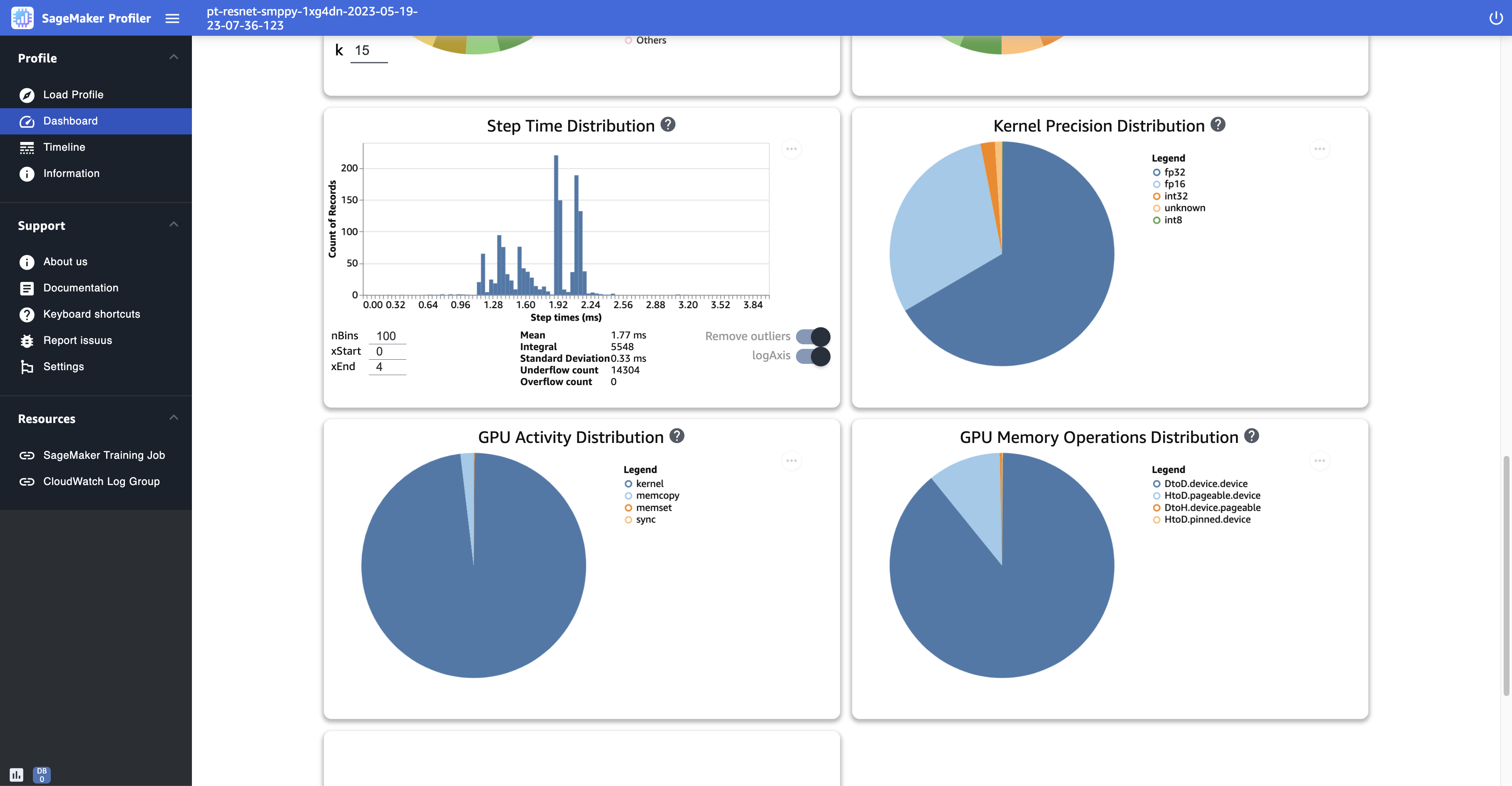
Distribuzione temporale delle fasi: questo istogramma mostra la distribuzione delle durate delle fasi su. GPUs Questo grafico viene generato solo dopo aver aggiunto l’annotatore delle fasi allo script di addestramento.
-
Distribuzione della precisione del kernel: questo grafico a torta mostra la percentuale di tempo impiegato per eseguire i kernel in diversi tipi di dati come FP32,, FP16 e. INT32 INT8
-
Distribuzione dell'attività della GPU: questo grafico a torta mostra la percentuale di tempo dedicato alle attività della GPU, come l'esecuzione dei kernel, la memoria (
memcpyememset) e la sincronizzazione (sync). -
Distribuzione delle operazioni di memoria della GPU: questo grafico a torta mostra la percentuale di tempo impiegato per le operazioni di memoria della GPU. Visualizza le attività
memcopye aiuta a capire se il processo di addestramento dedica troppo tempo a determinate operazioni di memoria. -
Crea un nuovo istogramma: crea un nuovo diagramma di un parametro personalizzato che hai annotato manualmente durante Passaggio 1: adattare lo script di formazione utilizzando i moduli SageMaker Profiler Python. Quando aggiungi un'annotazione personalizzata a un nuovo istogramma, seleziona o digita il nome dell'annotazione che hai aggiunto nello script di addestramento. Ad esempio, nello script di addestramento dimostrativo della fase 1,
step,Forward,Backward,OptimizeeLosssono le annotazioni personalizzate. Durante la creazione di un nuovo istogramma, i nomi delle annotazioni dovrebbero apparire nel menu a discesa per la selezione delle metriche. Se scegliBackward, l'interfaccia utente aggiunge al pannello di controllo l'istogramma del tempo impiegato per i passaggi all'indietro durante il periodo di tempo profilato. Questo tipo di istogramma è utile per verificare se vi sono valori anomali che richiedono tempi anormalmente più lunghi e determinano problemi con i colli di bottiglia.
Gli screenshot seguenti mostrano il rapporto tra tempo di attività di GPU e CPU e il tasso di utilizzo medio di GPU e CPU rispetto al tempo per nodo di calcolo.
Lo screenshot seguente mostra un esempio di grafici a torta per confrontare quante volte vengono avviati i kernel della GPU e per misurare il tempo impiegato per eseguirli. Nei pannelli Tempo impiegato da tutti i kernel GPU e Numero di avvii di tutti i kernel GPU, puoi anche specificare un numero intero nel campo di immissione per k per regolare il numero di legende da mostrare nei grafici. Ad esempio, se specifichi 10, i grafici mostrano rispettivamente i primi 10 kernel più eseguiti e lanciati.
Lo screenshot seguente mostra un esempio di istogramma della durata delle fasi e dei grafici a torta per la distribuzione di precisione del kernel, la distribuzione dell'attività della GPU e la distribuzione delle operazioni di memoria della GPU.
Interfaccia della sequenza temporale
Per ottenere una visione dettagliata delle risorse di calcolo a livello di operazioni e kernel pianificati CPUs ed eseguiti su di GPUs, utilizzate l'interfaccia Timeline.
È possibile ingrandire e rimpicciolire e spostarsi a sinistra o a destra nell'interfaccia della sequenza temporale utilizzando il mouse, i tasti [w, a, s, d] o i quattro tasti freccia sulla tastiera.
Suggerimento
Per ulteriori suggerimenti sui tasti di scelta rapida per interagire con l'interfaccia della Sequenza temporale, scegli Tasti di scelta rapida nel riquadro a sinistra.
Le tracce della sequenza temporale sono organizzate in una struttura ad albero, che fornisce informazioni dal livello di host a quello del dispositivo. Ad esempio, se esegui N istanze con otto GPUs istanze ciascuna, la struttura della sequenza temporale di ciascuna istanza sarebbe la seguente.
-
algo-i node: questo è il tipo di tag SageMaker AI per assegnare i lavori alle istanze assegnate. La cifra inode viene assegnata in modo casuale. Ad esempio, se utilizzi 4 istanze, questa sezione si espande da algo-1 ad algo-4.
-
CPU: in questa sezione, puoi controllare il tasso di utilizzo medio della CPU e i contatori delle prestazioni.
-
GPUs— In questa sezione, puoi controllare il tasso di utilizzo medio della GPU, il tasso di utilizzo della GPU individuale e i kernel.
-
Utilizzo SUM: i tassi di utilizzo medi della GPU per istanza.
-
HOST-0 PID-123: un nome univoco assegnato a ciascuna traccia del processo. L'acronimo PID è l'ID del processo e il numero aggiunto è il numero ID del processo registrato durante l'acquisizione dei dati dal processo. Questa sezione mostra le seguenti informazioni relative al processo.
-
Utilizzo della GPU-inum_gpu: il tasso di utilizzo della inum_gpuesima GPU nel tempo.
-
Dispositivo GPU-inum_gpu: il kernel viene eseguito sull'inum_gpu-esimo dispositivo GPU.
-
stream icuda_stream: stream CUDA che mostrano l'esecuzione del kernel sul dispositivo GPU. Per ulteriori informazioni sugli stream CUDA, consulta le diapositive in formato PDF all'indirizzo CUDA C/C++ Streams and Concurrency
fornito da NVIDIA.
-
-
Host GPU-inum_gpu: il kernel viene avviato sull'host GPU inum_gpuesino.
-
-
-
Le seguenti schermate mostrano la cronologia del profilo di un processo di formazione eseguito su ml.p4d.24xlarge istanze dotate di 8 NVIDIA A100 Tensor Core ciascuna. GPUs
Di seguito è riportata una visualizzazione ingrandita del profilo, che mostra una dozzina di fasi, tra cui un data loader intermittente tra step_232 e step_233 per il recupero del batch di dati successivo.
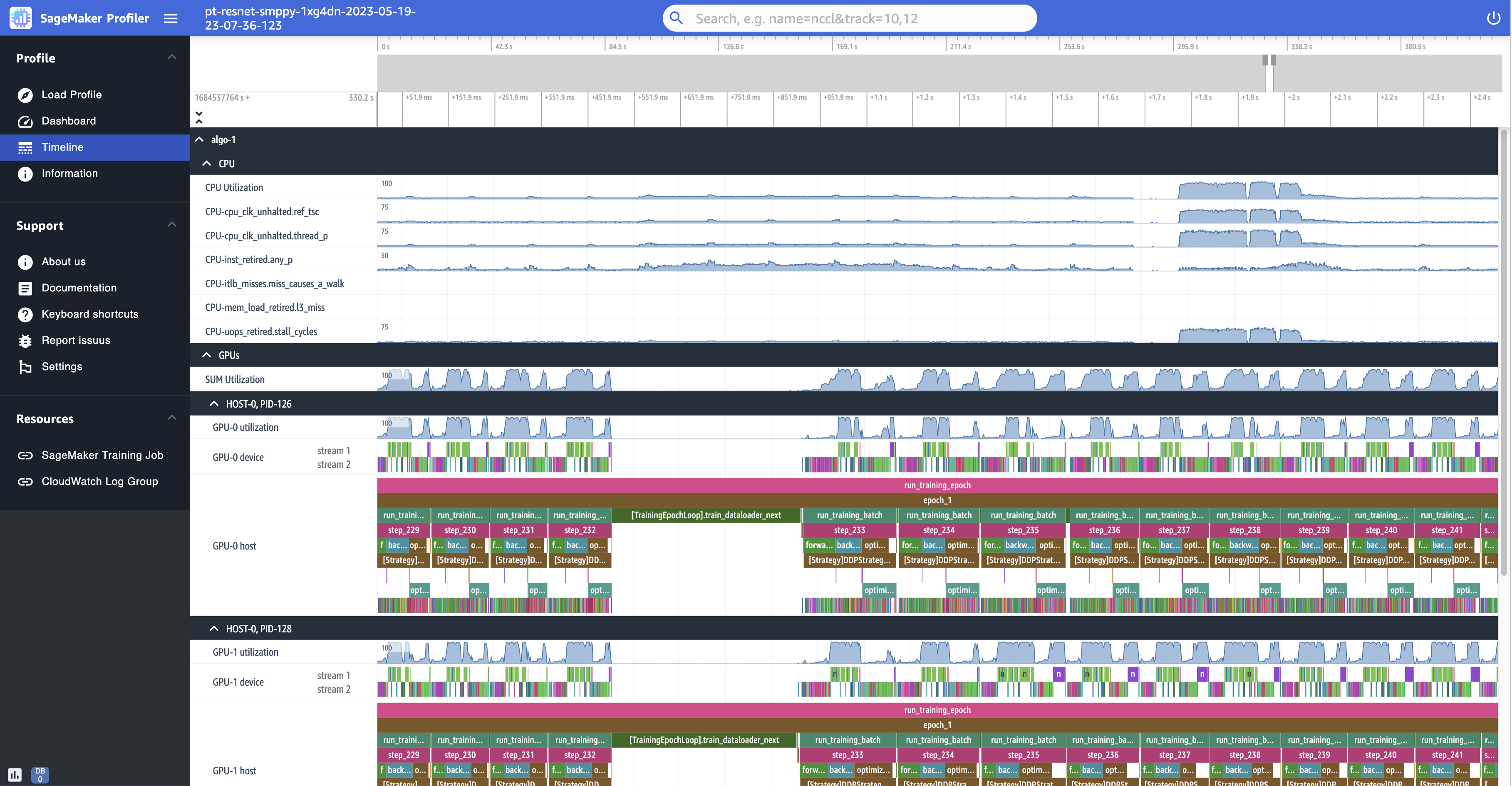
Per ogni CPU è possibile tenere traccia dell'utilizzo della CPU e dei contatori delle prestazioni, come "clk_unhalted_ref.tsc" e "itlb_misses.miss_causes_a_walk", che sono indicativi delle istruzioni eseguite sulla CPU.
Per ogni GPU, puoi visualizzare una sequenza temporale dell'host e una sequenza temporale del dispositivo. Gli avvii del kernel si trovano sulla sequenza temporale dell'host e le esecuzioni del kernel si trovano sulla sequenza temporale del dispositivo. Inoltre, puoi visualizzare le annotazioni (ad esempio Avanti, Indietro e Ottimizza) se hai aggiunto uno script di addestramento nella sequenza temporale dell'host della GPU.
Nella visualizzazione della sequenza temporale, puoi anche tenere traccia delle coppie di kernel. launch-and-run Questo aiuta a capire come viene eseguito un avvio del kernel pianificato su un host (CPU) sul dispositivo GPU corrispondente.
Suggerimento
Premi il tasto f per ingrandire il kernel selezionato.
Lo screenshot seguente è una vista ingrandita in step_233 e in step_234 dallo screenshot precedente. La sequenza temporale selezionata nello screenshot seguente è l'operazione AllReduce, una fase essenziale di comunicazione e sincronizzazione nell'addestramento distribuito, eseguita sul dispositivo GPU-0. Nello screenshot, nota che l'avvio del kernel nell'host GPU-0 si connette al kernel eseguito nel flusso 1 del dispositivo GPU-0, indicato con la freccia di colore ciano.
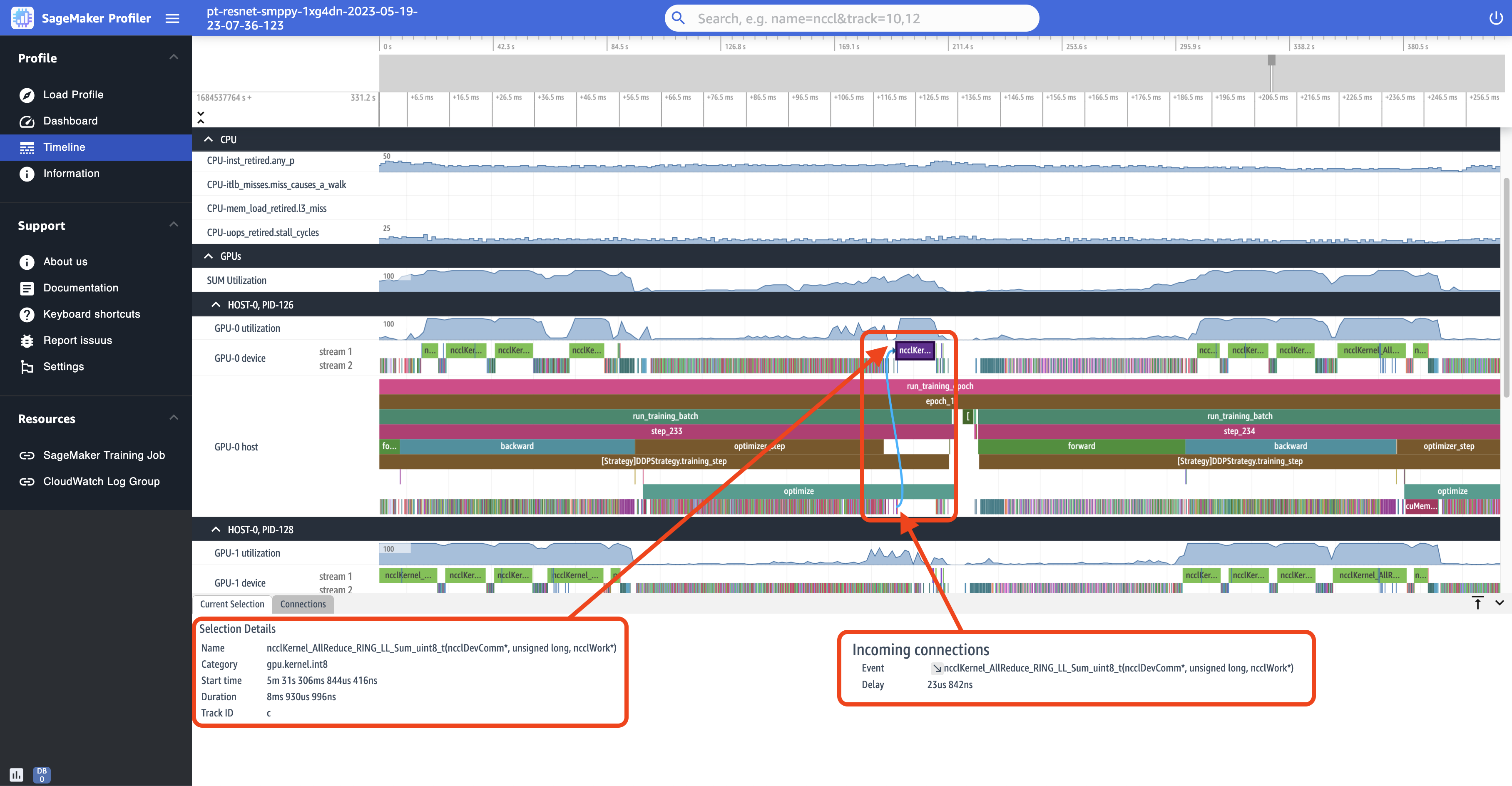
Inoltre, quando selezioni una sequenza temporale, nel riquadro inferiore dell'interfaccia utente vengono visualizzate due schede informative, come mostrato nello screenshot precedente. La scheda Selezione corrente mostra i dettagli del kernel selezionato e l’avvio del kernel connesso dall'host. La direzione di connessione è sempre dall'host (CPU) al dispositivo (GPU) poiché ogni kernel GPU viene sempre richiamato da una CPU. La scheda Connessioni mostra la coppia di avvio ed esecuzione del kernel scelta. È possibile selezionarne una per spostarla al centro della vista Sequenza temporale.
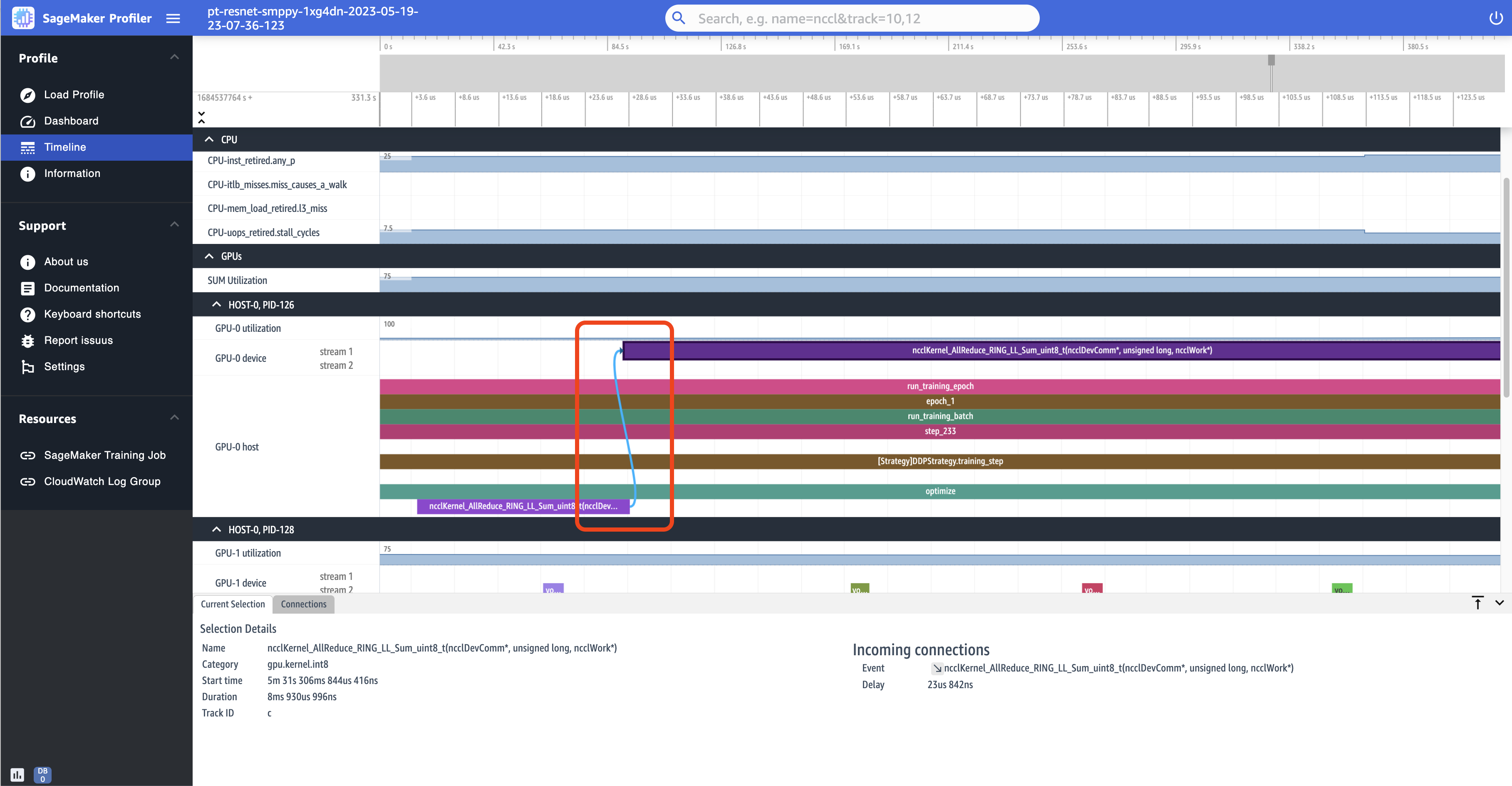
Il seguente screenshot ingrandisce ulteriormente l’operazione AllReduce della coppia di avvio ed esecuzione.
Informazioni
In Informazioni, puoi accedere alle informazioni sul processo di formazione caricato, come il tipo di istanza, Amazon Resource Names (ARNs) delle risorse di calcolo fornite per il lavoro, i nomi dei nodi e gli iperparametri.
Impostazioni
Per impostazione predefinita, l'istanza dell'applicazione SageMaker AI Profiler UI è configurata per chiudersi dopo 2 ore di inattività. In Impostazioni, usa le seguenti impostazioni per regolare il timer di spegnimento automatico.
-
Abilita l’arresto automatico dell'app: sceglilo e impostalo su Abilitato per consentire all'applicazione di chiudersi automaticamente dopo il numero di ore di tempo di inattività specificato. Per disattivare la funzionalità di arresto automatico, scegli Disabilitato.
-
Soglia di arresto automatico in ore: se scegli Abilitato per Abilita arresto automatico dell'app, puoi impostare il tempo di soglia in ore per l’arresto automatico dell'applicazione. Per impostazione predefinita, il valore è 2.
