Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Implementa modelli con Amazon SageMaker Serverless Inference
Amazon SageMaker Serverless Inference è un'opzione di inferenza appositamente progettata che consente di distribuire e scalare modelli di machine learning senza configurare o gestire alcuna infrastruttura sottostante. Inferenza Serverless On-demand è ideale per carichi di lavoro che presentano periodi di inattività tra picchi di traffico e possono tollerare avvii a freddo. Gli endpoint serverless avviano automaticamente le risorse di calcolo e le ridimensionano in base al traffico, eliminando la necessità di scegliere i tipi di istanza o gestire le policy di scalabilità. In questo modo si elimina l'onere indifferenziato della selezione e della gestione dei server. Inferenza Serverless si integra con AWS Lambda per offrire elevata disponibilità, tolleranza agli errori integrata e scalabilità automatica. Con un pay-per-use modello, Serverless Inference è un'opzione conveniente se hai uno schema di traffico poco frequente o imprevedibile. Nei periodi in cui non ci sono richieste, Inferenza Serverless ridimensiona l'endpoint fino a 0, aiutandoti a ridurre al minimo i costi. Per ulteriori informazioni sui prezzi di Serverless Inference on-demand, consulta Amazon Pricing. SageMaker
Facoltativamente, puoi anche utilizzare Simultaneità con provisioning con Inferenza Serverless. Inferenza Serverless con simultaneità con provisioning è un'opzione conveniente in caso di picchi di traffico prevedibili. Provisioned Concurrency ti consente di implementare modelli su endpoint serverless con prestazioni prevedibili e scalabilità elevata mantenendo gli endpoint caldi. SageMaker L'intelligenza artificiale garantisce che, in base al numero di Provisioned Concurrency allocate, le risorse di calcolo siano inizializzate e pronte a rispondere entro millisecondi. Per Inferenza Serverless con Simultaneità con provisioning, paghi in base alla capacità di calcolo utilizzata per elaborare le richieste di inferenza, fatturate in millisecondi, e alla quantità di dati elaborati. Paghi anche per l'utilizzo di Simultaneità con provisioning, in base alla memoria configurata, alla durata fornita e alla quantità di concorrenza abilitata. Per ulteriori informazioni sui prezzi di Serverless Inference with Provisioned Concurrency, consulta Amazon Pricing. SageMaker
Serverless Inference è generalmente disponibile in 21 AWS regioni: Stati Uniti orientali (Virginia settentrionale), Stati Uniti orientali (Ohio), Stati Uniti occidentali (California settentrionale), Stati Uniti occidentali (Oregon), Africa (Città del Capo), Asia Pacifico (Hong Kong), Asia Pacifico (Mumbai), Asia Pacifico (Tokyo), Asia Pacifico (Seoul), Asia Pacifico (Osaka), Asia Pacifico (Singapore), Asia Pacifico (Sydney), Canada (Centrale), Europa (Francoforte), Europa (Irlanda), Europa (Londra), Europa (Parigi), Europa (Stoccolma), Europa (Milano), Medio Oriente (Bahrein), Sud America (San Paolo). Per ulteriori informazioni sulla disponibilità regionale di Amazon SageMaker AI, consulta l'Elenco dei servizi AWS regionali
Come funziona
Il diagramma seguente mostra il flusso di lavoro di Inferenza Serverless on-demand e i vantaggi dell'utilizzo di un endpoint serverless.
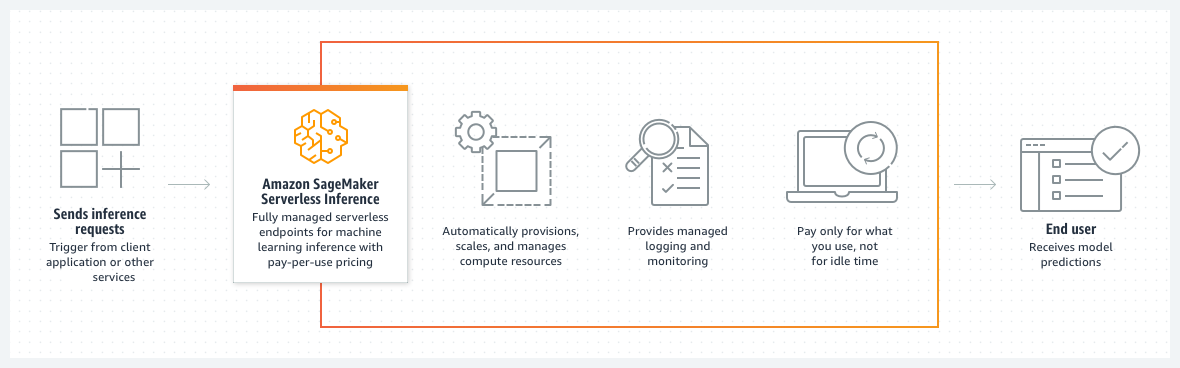
Quando crei un endpoint serverless on-demand, l' SageMaker IA fornisce e gestisce le risorse di elaborazione per te. Quindi, puoi effettuare richieste di inferenza all'endpoint e ricevere previsioni del modello in risposta. SageMaker L'intelligenza artificiale aumenta e riduce le risorse di calcolo in base alle esigenze per gestire il traffico delle richieste e paghi solo per ciò che utilizzi.
Per Simultaneità con provisioning, Inferenza Serverless si integra anche con Ridimensionamento automatico dell’applicazione, in modo da poter gestire Simultaneità con provisioning in base a un parametro destinazione o a una pianificazione. Per ulteriori informazioni, consulta Dimensionamento automatico del provisioning simultaneo per un endpoint serverless.
Nelle sezioni seguenti vengono forniti ulteriori dettagli sull'inferenza serverless e sul relativo funzionamento.
Argomenti
Supporto container
Per il tuo contenitore di endpoint, puoi scegliere un contenitore SageMaker fornito dall'intelligenza artificiale o portarne uno tuo. SageMaker L'intelligenza artificiale fornisce contenitori per i suoi algoritmi integrati e immagini Docker predefinite per alcuni dei framework di machine learning più comuni, come Apache, e Chainer. MXNet TensorFlow PyTorch Per un elenco delle SageMaker immagini disponibili, consulta Available Deep Learning Containers Images
La dimensione massima dell'immagine del container che è possibile utilizzare è di 10 GB. Per gli endpoint serverless, consigliamo di creare un solo worker nel container e caricare solo una copia del modello. Tieni presente che questo è diverso dagli endpoint in tempo reale, in cui alcuni contenitori di SageMaker intelligenza artificiale possono creare un worker per ogni vCPU per elaborare le richieste di inferenza e caricare il modello in ogni lavoratore.
Se disponi già di un container per un endpoint in tempo reale, puoi utilizzare lo stesso container per l'endpoint serverless, sebbene alcune funzionalità siano escluse. Per ulteriori informazioni sulle funzionalità dei container che non sono supportate in Inferenza Serverless, consulta Esclusione delle funzionalità. Se scegli di utilizzare lo stesso contenitore, l' SageMaker intelligenza artificiale deposita (conserva) una copia dell'immagine del contenitore fino a quando non elimini tutti gli endpoint che utilizzano l'immagine. SageMaker L'intelligenza artificiale crittografa l'immagine copiata quando è inattiva con una chiave di proprietà dell'IA. SageMaker AWS KMS
Dimensioni memoria
L'endpoint serverless ha una dimensione RAM minima di 1024 MB (1 GB) e la dimensione RAM massima che puoi scegliere è di 6144 MB (6 GB). Le dimensioni di memoria che puoi scegliere sono 1024 MB, 2048 MB, 3072 MB, 4096 MB, 5120 MB o 6144 MB. Inferenza Serverless assegna automaticamente le risorse di calcolo in modo proporzionale alla memoria selezionata. Se scegli una dimensione di memoria maggiore, il tuo contenitore ha accesso a più v. CPUs Scegli la dimensione della memoria del tuo endpoint in base alle dimensioni del modello. In genere, la dimensione della memoria deve essere almeno pari a quella del modello. Potrebbe essere necessario eseguire dei benchmark per scegliere la giusta selezione di memoria per il modello in base alla latenza. SLAs Per una guida dettagliata al benchmark, consulta Introduzione all'Amazon SageMaker Serverless Inference
Indipendentemente dalla dimensione di memoria scelta, l'endpoint serverless ha a disposizione 5 GB di archiviazione temporanea su disco. Per informazioni sui problemi relativi alle autorizzazioni dei container quando si lavora con l’archiviazione, consulta Risoluzione dei problemi.
Chiamate simultanee
Inferenza Serverless On-demand gestisce policy e quote di scalabilità predefinite per la capacità dell'endpoint. Gli endpoint serverless hanno una quota per il numero di chiamate simultanee che possono essere elaborate contemporaneamente. Se l'endpoint viene richiamato prima che termini l'elaborazione della prima richiesta, gestisce la seconda richiesta contemporaneamente.
La simultaneità totale che puoi condividere tra tutti gli endpoint serverless del tuo account dipende dalla tua Regione:
-
Per le Regioni Stati Uniti orientali (Ohio), Stati Uniti orientali (Virginia settentrionale), Stati Uniti occidentali (Oregon), Asia Pacifico (Singapore), Asia Pacifico (Sydney), Asia Pacifico (Tokyo), Europa (Francoforte), Europa (Irlanda), la simultaneità totale che puoi condividere tra tutti gli endpoint serverless per Regione nel tuo account è 1000.
-
Per le Regioni Stati Uniti occidentali (California settentrionale), Africa (Città del Capo), Asia Pacifico (Hong Kong), Asia Pacifico (Mumbai), Asia Pacifico (Osaka - Locale), Asia Pacifico (Seoul), Canada (Centrale), Europa (Londra), Europa (Milano), Europa (Parigi), Europa (Stoccolma) Medio Oriente (Bahrein) e Sud America (San Paolo), la simultaneità totale per Regione nel tuo account è 500.
Puoi impostare la simultaneità massima per un singolo endpoint fino a 200 e il numero totale di endpoint serverless che puoi ospitare in una Regione è 50. La simultaneità massima per un singolo endpoint impedisce a tale endpoint di accettare tutte le chiamate consentite per l'account e tutte le chiamate degli endpoint oltre il limite massimo vengono limitate.
Nota
La simultaneità assegnata a un endpoint serverless deve essere sempre inferiore o uguale alla simultaneità massima assegnata a tale endpoint.
Per informazioni su come impostare la simultaneità massima per l'endpoint, consulta Creare una configurazione endpoint. Per ulteriori informazioni su quote e limiti, consulta gli endpoint e le quote di Amazon SageMaker AI nel. Riferimenti generali di AWS Per richiedere un aumento delle restrizioni dei servizi, consulta Supporto AWS
Riduzione al minimo degli avvii a freddo
Se l'endpoint Inferenza Serverless on-demand non riceve traffico per un po' di tempo e poi improvvisamente riceve nuove richieste, l'endpoint può impiegare del tempo prima che l'endpoint attivi le risorse di elaborazione necessarie per elaborare le richieste. Questo procedimento è chiamato avvio a freddo. Poiché gli endpoint serverless forniscono risorse di calcolo su richiesta, l'endpoint potrebbe subire avvii a freddo. Un avvio a freddo può verificarsi anche se le richieste simultanee superano l'utilizzo corrente delle richieste simultanee. L'orario di avvio a freddo dipende dalle dimensioni del modello, dal tempo necessario per scaricare il modello e dal tempo di avvio del container.
Per monitorare la durata dell'orario di avvio a freddo, puoi utilizzare il CloudWatch parametro Amazon OverheadLatency per monitorare il tuo endpoint serverless. Questo parametro tiene traccia del tempo necessario per lanciare nuove risorse di calcolo per il tuo endpoint. Per ulteriori informazioni sull'utilizzo delle CloudWatch metriche con gli endpoint serverless, consulta. Allarmi e registri per tracciare le metriche dagli endpoint serverless
Puoi ridurre al minimo le partenze a freddo utilizzando Provisioned Concurrency. SageMaker L'intelligenza artificiale mantiene l'endpoint caldo e pronto a rispondere in millisecondi, per il numero di Provisioned Concurrency allocate.
Esclusione delle funzionalità
Alcune delle funzionalità attualmente disponibili per SageMaker AI Real-time Inference non sono supportate per Serverless Inference, tra cui pacchetti di modelli AWS marketplace GPUs, registri Docker privati, endpoint multimodel, configurazione VPC, isolamento di rete, acquisizione dati, più varianti di produzione, Model Monitor e pipeline di inferenza.
Non puoi convertire un endpoint in tempo reale basato su istanze in un endpoint serverless. Se provi ad aggiornare il tuo endpoint in tempo reale a serverless, ricevi un messaggio ValidationError. Puoi convertire un endpoint serverless in un endpoint serverless in tempo reale, ma una volta effettuato l'aggiornamento, non puoi ripristinarlo alla versione serverless.
Nozioni di base
Puoi creare, aggiornare, descrivere ed eliminare un endpoint serverless utilizzando la console SageMaker AI AWS SDKs, l'SDK Amazon SageMaker Python
Nota
Dimensionamento automatico dell’applicazione per Inferenza Serverless con Simultaneità con provisioning non è attualmente supportato su AWS CloudFormation.
Notebook e blog di esempio
