Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Configura un processo di formazione con un cluster eterogeneo in Amazon AI SageMaker
Questa sezione fornisce istruzioni su come eseguire un processo di addestramento utilizzando un cluster eterogeneo composto da più tipi di istanze.
Tieni presente quanto segue prima di iniziare.
-
Tutti i gruppi di istanze condividono la stessa immagine Docker e lo stesso script di addestramento. Pertanto, lo script di addestramento deve essere modificato per rilevare a quale gruppo di istanze appartiene e modificare di conseguenza l'esecuzione.
-
La funzionalità di cluster eterogeneo non è compatibile con SageMaker la modalità locale AI.
-
I flussi di CloudWatch log Amazon di un processo di formazione su cluster eterogenei non sono raggruppati per gruppi di istanze. È necessario capire dai log quali nodi si trovano in quale gruppo.
Argomenti
Opzione 1: utilizzo dell' SageMaker SDK Python
Segui le istruzioni su come configurare i gruppi di istanze per un cluster eterogeneo utilizzando Python SageMaker SDK.
-
Per configurare i gruppi di istanze di un cluster eterogeneo per un processo di addestramento, usa la classe
sagemaker.instance_group.InstanceGroup. Puoi specificare un nome personalizzato per ogni gruppo di istanze, il tipo di istanze e il numero di istanze per ogni gruppo di istanze. Per ulteriori informazioni, consulta sagemaker.instance_group. InstanceGroupnella documentazione di SageMaker AI Python SDK. Nota
Per ulteriori informazioni sui tipi di istanze disponibili e sul numero massimo di gruppi di istanze che è possibile configurare in un cluster eterogeneo, consulta il riferimento alle API. InstanceGroup
Il seguente esempio di codice mostra come impostare due gruppi di istanze composti da due istanze denominate solo CPU
ml.c5.18xlargedenominateinstance_group_1e un’istanza GPUml.p3dn.24xlargedenominatainstance_group_2, come illustrato nel diagramma seguente.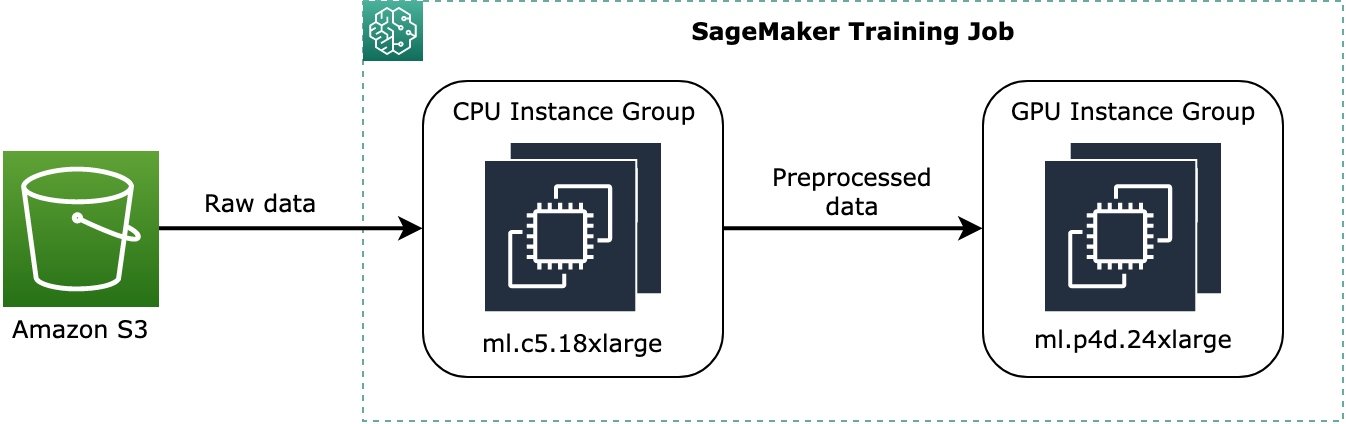
Il diagramma precedente mostra un esempio concettuale di come i processi di pre-addestramento, come la preelaborazione dei dati, possono essere assegnati al gruppo di istanze CPU e trasmettere i dati preelaborati al gruppo di istanze GPU.
from sagemaker.instance_group import InstanceGroup instance_group_1 = InstanceGroup( "instance_group_1", "ml.c5.18xlarge",2) instance_group_2 = InstanceGroup( "instance_group_2", "ml.p3dn.24xlarge",1) -
Utilizzando gli oggetti del gruppo di istanze, impostate i canali di input di addestramento e assegnate i gruppi di istanze ai canali tramite l'argomento di sagemaker.inputs.
instance_group_namesTrainingInputclasse. L'argomento instance_group_namesaccetta un elenco di stringhe di nomi di gruppi di istanze.L'esempio seguente mostra come impostare due canali di input di addestramento e assegnare i gruppi di istanze creati nell'esempio della fase precedente. Puoi anche specificare i percorsi dei bucket di Amazon S3 all'argomento
s3_dataaffinché i gruppi di istanze elaborino i dati per i tuoi scopi di utilizzo.from sagemaker.inputs import TrainingInput training_input_channel_1 = TrainingInput( s3_data_type='S3Prefix', # Available Options: S3Prefix | ManifestFile | AugmentedManifestFile s3_data='s3://your-training-data-storage/folder1', distribution='FullyReplicated', # Available Options: FullyReplicated | ShardedByS3Key input_mode='File', # Available Options: File | Pipe | FastFile instance_groups=["instance_group_1"] ) training_input_channel_2 = TrainingInput( s3_data_type='S3Prefix', s3_data='s3://your-training-data-storage/folder2', distribution='FullyReplicated', input_mode='File', instance_groups=["instance_group_2"] )Per ulteriori informazioni sugli argomenti di
TrainingInput, consulta i seguenti link.-
Il sagemaker.inputs. TrainingInput
classe nella documentazione di SageMaker Python SDK -
L'API S3 nell'AI DataSource API Reference SageMaker
-
-
Configura uno stimatore SageMaker AI con l'
instance_groupsargomento come mostrato nel seguente esempio di codice. L’argomentoinstance_groupsaccetta un elenco di oggettiInstanceGroup.Nota
La funzionalità di cluster eterogeneo è disponibile tramite le classi SageMaker AI PyTorch
e TensorFlow framework estimator. I framework supportati sono la versione PyTorch 1.10 o successiva e la versione 2.6 o successiva. TensorFlow Per trovare un elenco completo dei contenitori di framework disponibili, delle versioni del framework e delle versioni Python, consulta SageMaker AI Framework Containers nel repository AWS Deep Learning Container GitHub . Nota
La coppia
instance_typeeinstance_countargument e l'instance_groupsargomento della classe SageMaker AI estimator si escludono a vicenda. Per un addestramento omogeneo dei cluster, utilizza la coppia di argomentiinstance_typeeinstance_count. Per un addestramento eterogeneo su cluster, usainstance_groups.Nota
Per trovare un elenco completo dei contenitori di framework disponibili, delle versioni del framework e delle versioni Python, consulta SageMaker AI Framework Containers
nel repository AWS Deep Learning Container GitHub . -
Configura il metodo
estimator.fitcon i canali di input di addestramento configurati con i gruppi di istanze e avvia il processo di addestramento.estimator.fit( inputs={ 'training':training_input_channel_1, 'dummy-input-channel':training_input_channel_2} )
Opzione 2: utilizzo del livello basso SageMaker APIs
Se utilizzi AWS Command Line Interface o AWS SDK per Python (Boto3) e desideri utilizzare il livello basso SageMaker APIs per inviare una richiesta di lavoro di formazione con un cluster eterogeneo, consulta i seguenti riferimenti API.
