Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo dello stato della mappa in modalità Distribuita per carichi di lavoro paralleli su larga scala in Step Functions
Gestione dello stato e trasformazione dei dati
Scopri come passare dati tra stati con variabili e Trasformare dati con. JSONata
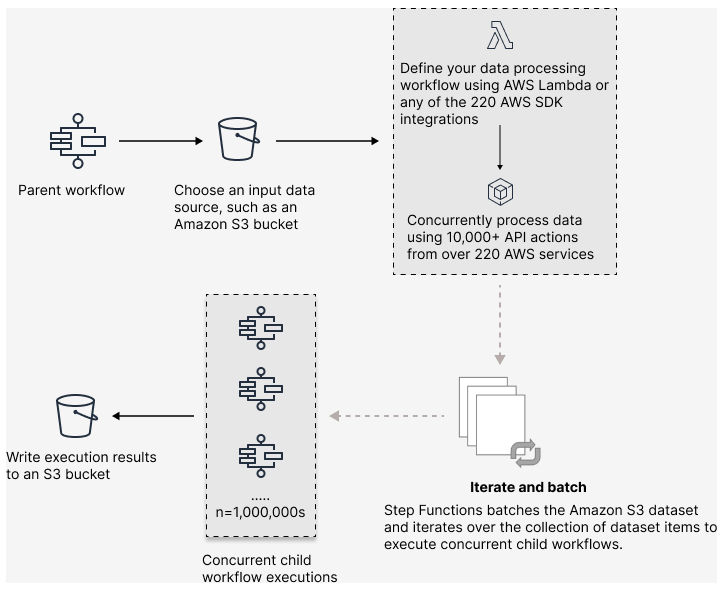
Con Step Functions, puoi orchestrare carichi di lavoro paralleli su larga scala per eseguire attività, come l'elaborazione su richiesta di dati semistrutturati. Questi carichi di lavoro paralleli consentono di elaborare contemporaneamente sorgenti di dati su larga scala archiviate in Amazon S3. Ad esempio, potresti elaborare un singolo file JSON o CSV che contiene grandi quantità di dati. Oppure potresti elaborare un ampio set di oggetti Amazon S3.
Per configurare un carico di lavoro parallelo su larga scala nei flussi di lavoro, includi uno Map stato in modalità Distribuita. Lo stato della mappa elabora gli elementi in un set di dati contemporaneamente. Uno Map stato impostato su Distributed è noto come stato Distributed Map. In modalità Distribuita, lo Map stato consente l'elaborazione ad alta concorrenza. In modalità distribuita, Map lo stato elabora gli elementi del set di dati in iterazioni denominate esecuzioni secondarie del flusso di lavoro. È possibile specificare il numero di esecuzioni di workflow secondarie che possono essere eseguite in parallelo. Ogni esecuzione del flusso di lavoro secondario ha una propria cronologia di esecuzione separata da quella del flusso di lavoro principale. Se non lo specifichi, Step Functions esegue 10.000 esecuzioni parallele di flussi di lavoro secondari in parallelo.
La seguente illustrazione spiega come configurare carichi di lavoro paralleli su larga scala nei flussi di lavoro.
Impara in un seminario
Scopri come le tecnologie serverless come Step Functions e Lambda possono semplificare la gestione e la scalabilità, ridurre il carico di attività indifferenziate e affrontare le sfide dell'elaborazione distribuita dei dati su larga scala. Lungo il percorso, utilizzerai mappe distribuite per l'elaborazione ad alta concorrenza. Il workshop presenta anche le migliori pratiche per l'ottimizzazione dei flussi di lavoro e casi d'uso pratici per l'elaborazione dei reclami, la scansione delle vulnerabilità e la simulazione Monte Carlo.
Workshop: Elaborazione di dati su larga scala con Step Functions
In questo argomento
Termini chiave
- Modalità distribuita
-
Una modalità di elaborazione dello stato della mappa. In questa modalità, ogni iterazione dello
Mapstato viene eseguita come un'esecuzione secondaria del flusso di lavoro che consente un'elevata concorrenza. Ogni esecuzione del flusso di lavoro secondario ha la propria cronologia di esecuzione, che è separata dalla cronologia di esecuzione del flusso di lavoro principale. Questa modalità supporta la lettura di input da fonti di dati Amazon S3 su larga scala. - Stato della mappa distribuita
-
Uno stato della mappa impostato sulla modalità di elaborazione distribuita.
- Workflow della mappa
Una serie di passaggi eseguiti da uno
Mapstato.- Flusso di lavoro principale
-
Un flusso di lavoro che contiene uno o più stati della mappa distribuita.
- Esecuzione del workflow secondario
-
Un'iterazione dello stato della mappa distribuita. L'esecuzione di un flusso di lavoro secondario ha una propria cronologia di esecuzione, che è separata dalla cronologia di esecuzione del flusso di lavoro principale.
- Esegui la mappa
-
Quando si esegue uno
Mapstato in modalità Distribuita, Step Functions crea una risorsa Map Run. Un Map Run si riferisce a un insieme di esecuzioni di workflow secondarie avviate da uno stato di Distributed Map e alle impostazioni di runtime che controllano queste esecuzioni. Step Functions assegna un Amazon Resource Name (ARN) a Map Run. È possibile esaminare un Map Run nella console Step Functions. Puoi anche richiamare l'azioneDescribeMapRunAPI.Map Run non emette metriche su. CloudWatch Tuttavia, le esecuzioni di workflow secondarie di un Map Run emettono metriche a. CloudWatch Queste metriche avranno un ARN etichettato State Machine con il seguente formato:
arn:partition:states:region:account:stateMachine:stateMachineName/MapRunLabel or UUIDPer ulteriori informazioni, consulta Visualizzazione delle corse delle mappe.
Esempio di definizione dello stato della mappa distribuita () JSONPath
Usa lo Map stato in modalità Distribuita quando devi orchestrare carichi di lavoro paralleli su larga scala che soddisfano qualsiasi combinazione delle seguenti condizioni:
La dimensione del set di dati supera i 256 KB.
La cronologia degli eventi di esecuzione del flusso di lavoro supererebbe le 25.000 voci.
È necessaria una concorrenza di più di 40 iterazioni simultanee.
Il seguente esempio di definizione dello stato di Distributed Map specifica il set di dati come file CSV archiviato in un bucket Amazon S3. Specifica inoltre una funzione Lambda che elabora i dati in ogni riga del file CSV. Poiché questo esempio utilizza un file CSV, specifica anche la posizione delle intestazioni delle colonne CSV. Per visualizzare la definizione completa di macchina a stati di questo esempio, consulta il tutorial Copiare dati CSV su larga scala utilizzando Distributed Map.
{
"Map": {
"Type": "Map",
"ItemReader": {
"ReaderConfig": {
"InputType": "CSV",
"CSVHeaderLocation": "FIRST_ROW"
},
"Resource": "arn:aws:states:::s3:getObject",
"Parameters": {
"Bucket": "amzn-s3-demo-bucket",
"Key": "csv-dataset/ratings.csv"
}
},
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "DISTRIBUTED",
"ExecutionType": "EXPRESS"
},
"StartAt": "LambdaTask",
"States": {
"LambdaTask": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:us-east-2:account-id:function:processCSVData"
},
"End": true
}
}
},
"Label": "Map",
"End": true,
"ResultWriter": {
"Resource": "arn:aws:states:::s3:putObject",
"Parameters": {
"Bucket": "amzn-s3-demo-destination-bucket",
"Prefix": "csvProcessJobs"
}
}
}
}Autorizzazioni per eseguire Distributed Map
Quando includi uno stato della mappa distribuita nei flussi di lavoro, Step Functions necessita delle autorizzazioni appropriate per consentire al ruolo della macchina a stati di richiamare l'azione StartExecution API per lo stato della mappa distribuita.
Il seguente esempio di policy IAM concede i privilegi minimi richiesti al ruolo della macchina a stati per l'esecuzione dello stato della mappa distribuita.
Nota
Assicurati di sostituirlo stateMachineNamearn:aws:states:.region:account-id:stateMachine:mystateMachine
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "states:StartExecution" ], "Resource": [ "arn:aws:states:us-east-1:123456789012:stateMachine:myStateMachineName" ] }, { "Effect": "Allow", "Action": [ "states:DescribeExecution" ], "Resource": "arn:aws:states:us-east-1:123456789012:execution:myStateMachineName:*" } ] }
Inoltre, devi assicurarti di disporre dei privilegi minimi necessari per accedere alle AWS risorse utilizzate nello stato della mappa distribuita, come i bucket Amazon S3. Per informazioni, consultare Politiche IAM per l'utilizzo degli stati della mappa distribuita.
Campi relativi allo stato della mappa distribuita
Per utilizzare lo stato della mappa distribuita nei flussi di lavoro, specifica uno o più di questi campi. È possibile specificare questi campi in aggiunta ai campi di stato comuni.
Type(Obbligatorio)-
Imposta il tipo di stato, ad esempio
Map. ItemProcessor(Obbligatorio)-
Contiene i seguenti oggetti JSON che specificano la modalità e la definizione di elaborazione
Mapdello stato.-
ProcessorConfig— Oggetto JSON che specifica la modalità di elaborazione degli elementi, con i seguenti sottocampi:-
Mode— Impostato perDISTRIBUTEDutilizzareMaplo stato in modalità Distribuita.avvertimento
La modalità distribuita è supportata nei flussi di lavoro Standard ma non è supportata nei flussi di lavoro Express.
-
ExecutionType— Speciifica il tipo di esecuzione per il flusso di lavoro Map come STANDARD o EXPRESS. È necessario fornire questo campo se è stato specificatoDISTRIBUTEDper ilModesottocampo. Per ulteriori informazioni sui tipi di flusso di lavoro, vedereScelta del tipo di flusso di lavoro in Step Functions.
-
StartAt— specifica una stringa che indica il primo stato di un flusso di lavoro. Questa stringa fa distinzione tra maiuscole e minuscole e deve corrispondere al nome di uno degli oggetti di stato. Questo stato viene eseguito per primo per ogni elemento del set di dati. Qualsiasi input di esecuzione fornito alloMapstato passa per primo alloStartAtstato.States— Un oggetto JSON contenente un set di stati delimitato da virgole. In questo oggetto, si definisce il. Map workflow
-
ItemReader-
Speciifica un set di dati e la sua posizione. Lo
Mapstato riceve i dati di input dal set di dati specificato.In modalità distribuita, puoi utilizzare un payload JSON passato da uno stato precedente o un'origine dati Amazon S3 su larga scala come set di dati. Per ulteriori informazioni, consulta ItemReader (Mappa).
Items(Solo facoltativo) JSONata-
Un array JSON o un' JSONata espressione che deve restituire un array.
ItemsPath( JSONPath Solo facoltativo)-
Specifica un percorso di riferimento utilizzando la JsonPath
sintassi per selezionare il nodo JSON che contiene una matrice di elementi all'interno dell'input di stato. In modalità distribuita, si specifica questo campo solo quando si utilizza un array JSON di un passaggio precedente come input di stato. Per ulteriori informazioni, consulta ItemsPath ( JSONPath Solo mappa).
ItemSelector( JSONPath Solo facoltativo)-
Sostituisce i valori dei singoli elementi del set di dati prima che vengano trasmessi a ciascuna
Mapiterazione di stato.In questo campo, specifichi un input JSON valido che contiene una raccolta di coppie chiave-valore. Queste coppie possono essere valori statici definiti nella definizione della macchina a stati, valori selezionati dall'input di stato utilizzando un percorso o valori a cui si accede dall'oggetto di contesto. Per ulteriori informazioni, consulta ItemSelector (Mappa).
ItemBatcher(facoltativo).-
Speciifica di elaborare gli elementi del set di dati in batch. Ogni esecuzione secondaria del flusso di lavoro riceve quindi un batch di questi elementi come input. Per ulteriori informazioni, consulta ItemBatcher (Mappa).
MaxConcurrency(facoltativo).-
Speciifica il numero di esecuzioni di workflow secondarie che possono essere eseguite in parallelo. L'interprete consente solo fino al numero specificato di esecuzioni parallele di flussi di lavoro secondari. Se non specificate un valore di concorrenza o lo impostate su zero, Step Functions non limita la concorrenza ed esegue 10.000 esecuzioni parallele di flussi di lavoro secondari. Negli JSONata stati, è possibile specificare un' JSONata espressione che restituisca un numero intero.
Nota
Sebbene sia possibile specificare un limite di concorrenza più elevato per le esecuzioni di flussi di lavoro secondari paralleli, si consiglia di non superare la capacità di un AWS servizio downstream, ad esempio. AWS Lambda
MaxConcurrencyPath(Solo facoltativo) JSONPath-
Se desideri fornire un valore di concorrenza massimo in modo dinamico dall'input dello stato utilizzando un percorso di riferimento, usa.
MaxConcurrencyPathUna volta risolto, il percorso di riferimento deve selezionare un campo il cui valore è un numero intero non negativo.Nota
Uno
Mapstato non può includere entrambiMaxConcurrencye.MaxConcurrencyPath ToleratedFailurePercentage(facoltativo).-
Definisce la percentuale di elementi non riusciti da tollerare in una Map Run. La Map Run fallisce automaticamente se supera questa percentuale. Step Functions calcola la percentuale di articoli non riusciti come risultato del numero totale di articoli non riusciti o scaduti diviso per il numero totale di articoli. È necessario specificare un valore compreso tra zero e 100. Per ulteriori informazioni, consulta Impostazione delle soglie di errore per gli stati della mappa distribuita in Step Functions.
Negli JSONata stati, è possibile specificare un' JSONata espressione che restituisca un numero intero.
ToleratedFailurePercentagePath(Solo facoltativo) JSONPath-
Se si desidera fornire dinamicamente un valore percentuale di errore tollerato in base allo stato immesso utilizzando un percorso di riferimento, utilizzare.
ToleratedFailurePercentagePathUna volta risolto, il percorso di riferimento deve selezionare un campo il cui valore è compreso tra zero e 100. ToleratedFailureCount(facoltativo).-
Definisce il numero di elementi non riusciti da tollerare in una Map Run. La Map Run fallisce automaticamente se supera questo numero. Per ulteriori informazioni, consulta Impostazione delle soglie di errore per gli stati della mappa distribuita in Step Functions.
Negli JSONata stati, è possibile specificare un' JSONata espressione che restituisca un numero intero.
ToleratedFailureCountPath(Solo facoltativo) JSONPath-
Se si desidera fornire un valore di conteggio degli errori tollerati in modo dinamico a partire dallo stato di input utilizzando un percorso di riferimento, utilizzare.
ToleratedFailureCountPathUna volta risolto, il percorso di riferimento deve selezionare un campo il cui valore è un numero intero non negativo. Label(facoltativo).-
Una stringa che identifica in modo univoco uno stato.
MapPer ogni Map Run, Step Functions aggiunge l'etichetta al Map Run ARN. Di seguito è riportato un esempio di Map Run ARN con un'etichetta personalizzata denominata:demoLabelarn:aws:states:region:account-id:mapRun:demoWorkflow/demoLabel:3c39a231-69bb-3d89-8607-9e124eddbb0bSe non specificate un'etichetta, Step Functions genera automaticamente un'etichetta univoca.
Nota
Le etichette non possono superare i 40 caratteri di lunghezza, devono essere univoche all'interno di una definizione di macchina a stati e non possono contenere nessuno dei seguenti caratteri:
-
Spazi bianchi
-
Caratteri jolly ()
? * -
Caratteri tra parentesi ()
< > { } [ ] -
Caratteri speciali ()
: ; , \ | ^ ~ $ # % & ` " -
Caratteri di controllo (
\\u0000-\\u001fo\\u007f-\\u009f).
Step Functions accetta nomi per macchine a stati, esecuzioni, attività ed etichette che contengono caratteri non ASCII. Poiché tali caratteri non funzionano con Amazon CloudWatch, ti consigliamo di utilizzare solo caratteri ASCII per tenere traccia delle metriche. CloudWatch
-
ResultWriter(facoltativo).-
Speciifica la posizione Amazon S3 in cui Step Functions scrive tutti i risultati di esecuzione dei flussi di lavoro secondari.
Step Functions consolida tutti i dati di esecuzione del workflow secondario, come input e output dell'esecuzione, ARN e stato di esecuzione. Quindi esporta le esecuzioni con lo stesso stato nei rispettivi file nella posizione Amazon S3 specificata. Per ulteriori informazioni, consulta ResultWriter (Mappa).
Se non esporti i risultati dello
Mapstato, restituisce una matrice di tutti i risultati di esecuzione del flusso di lavoro secondario. Per esempio:[1, 2, 3, 4, 5] ResultPath( JSONPath Solo facoltativo)-
Specifa in che punto dell'input inserire l'output delle iterazioni. L'input viene quindi filtrato come specificato dal OutputPathcampo, se presente, prima di essere passato come output dello stato. Per ulteriori informazioni, consultare Elaborazione di input e output.
ResultSelector(facoltativo).-
Passa una raccolta di coppie chiave-valore, in cui i valori sono statici o selezionati dal risultato. Per ulteriori informazioni, consulta ResultSelector.
Suggerimento
Se lo stato Parallel o Map che usi nelle tue macchine a stati restituisce un array di array, puoi trasformarli in un array flat con il campo. ResultSelector Per ulteriori informazioni, consulta Appiattimento di una serie di array.
Retry(facoltativo).-
Una serie di oggetti, denominati Retriers, che definiscono una politica di nuovi tentativi. Un'esecuzione utilizza la politica di riprova se lo stato rileva errori di runtime. Per ulteriori informazioni, consulta Esempi di macchine a stati che utilizzano Retry e Catch.
Nota
Se si definiscono Retriers per lo stato Distributed Map, la politica di nuovo tentativo si applica a tutte le esecuzioni di workflow secondarie avviate dallo stato.
MapAd esempio, immaginate che il vostroMapstato abbia avviato tre esecuzioni secondarie di workflow, di cui una fallisce. Quando si verifica l'errore, l'esecuzione utilizza ilRetrycampo, se definito, per loMapstato. La politica dei nuovi tentativi si applica a tutte le esecuzioni dei flussi di lavoro secondari e non solo a quelle non riuscite. Se una o più esecuzioni di workflow secondarie falliscono, Map Run non riesce.Quando si riprova uno
Mapstato, viene creata una nuova Map Run. Catch(facoltativo).-
Un array di oggetti, denominati catcher, che definiscono uno stato di fallback. Step Functions utilizza i Catcher definiti in
Catchse lo stato rileva errori di runtime. Quando si verifica un errore, l'esecuzione utilizza innanzitutto tutti i retrier definiti in.RetrySe la politica di riprova non è definita o è esaurita, l'esecuzione utilizza i relativi Catcher, se definiti. Per ulteriori informazioni, consulta Stati di fallback. Output(Solo facoltativo) JSONata-
Utilizzato per specificare e trasformare l'output dello stato. Quando specificato, il valore ha la precedenza sullo stato di output predefinito.
Il campo di output accetta qualsiasi valore JSON (oggetto, array, stringa, numero, booleano, null). Qualsiasi valore di stringa, inclusi quelli all'interno di oggetti o array, verrà valutato come JSONata se fosse circondato da {%%} caratteri.
Output accetta anche direttamente un' JSONata espressione, ad esempio: «Output»: «{% jsonata expression%}»
Per ulteriori informazioni, consulta Trasformazione dei dati con Step JSONata Functions.
-
Assign(facoltativo). -
Utilizzato per memorizzare variabili. Il
Assigncampo accetta un oggetto JSON con key/value coppie che definiscono i nomi delle variabili e i valori assegnati. Qualsiasi valore di stringa, compresi quelli all'interno di oggetti o matrici, verrà valutato come JSONata se fosse circondato da caratteri{% %}Per ulteriori informazioni, consulta Passaggio di dati tra stati con variabili.
Impostazione delle soglie di errore per gli stati della mappa distribuita in Step Functions
Quando orchestri carichi di lavoro paralleli su larga scala, puoi anche definire una soglia di errore tollerata. Questo valore consente di specificare il numero massimo o la percentuale di elementi non riusciti come soglia di errore per una Map Run. A seconda del valore specificato, Map Run fallisce automaticamente se supera la soglia. Se si specificano entrambi i valori, il flusso di lavoro fallisce quando supera uno dei due valori.
Specificare una soglia consente di fallire un numero specifico di elementi prima che l'intero Map Run abbia esito negativo. Step Functions restituisce un States.ExceedToleratedFailureThreshold errore quando Map Run fallisce perché viene superata la soglia specificata.
Nota
Step Functions può continuare a eseguire flussi di lavoro secondari in una Map Run anche dopo il superamento della soglia di errore tollerata, ma prima che Map Run fallisca.
Per specificare il valore di soglia in Workflow Studio, selezionare Imposta una soglia di errore tollerata in Configurazione aggiuntiva nel campo Impostazioni di runtime.
- Percentuale di fallimento tollerato
-
Definisce la percentuale di articoli non riusciti da tollerare. Il Map Run fallisce se questo valore viene superato. Step Functions calcola la percentuale di articoli non riusciti come risultato del numero totale di articoli non riusciti o scaduti diviso per il numero totale di articoli. È necessario specificare un valore compreso tra zero e 100. Il valore percentuale predefinito è zero, il che significa che il flusso di lavoro ha esito negativo se una delle sue esecuzioni secondarie del flusso di lavoro fallisce o scade. Se si specifica la percentuale come 100, il flusso di lavoro non avrà esito negativo anche se tutte le esecuzioni del flusso di lavoro secondario falliscono.
In alternativa, è possibile specificare la percentuale come percorso di riferimento per una coppia chiave-valore esistente nell'input di stato della Mappa distribuita. Questo percorso deve risolversi in un numero intero positivo compreso tra 0 e 100 in fase di esecuzione. Il percorso di riferimento viene specificato nel
ToleratedFailurePercentagePathsottocampo.Ad esempio, con il seguente input:
{"percentage":15}È possibile specificare la percentuale utilizzando un percorso di riferimento a tale input come segue:
{ ... "Map": { "Type": "Map", ..."ToleratedFailurePercentagePath":"$.percentage"... } }Importante
È possibile specificare uno
ToleratedFailurePercentageo entrambiToleratedFailurePercentagePath, ma non entrambi nella definizione dello stato della Mappa Distribuita. - Numero di fallimenti tollerati
-
Definisce il numero di elementi non riusciti da tollerare. Il Map Run fallisce se questo valore viene superato.
In alternativa, puoi specificare il conteggio come percorso di riferimento per una coppia chiave-valore esistente nell'input di stato della Mappa distribuita. Questo percorso deve risolversi in un numero intero positivo in fase di esecuzione. Il percorso di riferimento viene specificato nel
ToleratedFailureCountPathsottocampo.Ad esempio, con il seguente input:
{"count":10}È possibile specificare il numero utilizzando un percorso di riferimento a tale input come segue:
{ ... "Map": { "Type": "Map", ..."ToleratedFailureCountPath":"$.count"... } }Importante
È possibile specificare uno
ToleratedFailureCounto entrambiToleratedFailureCountPath, ma non entrambi nella definizione dello stato della Mappa Distribuita.
Scopri di più sulle mappe distribuite
Per continuare a saperne di più sullo stato delle mappe distribuite, consulta le seguenti risorse:
-
Elaborazione di input e output
Per configurare l'input ricevuto da uno stato della Mappa Distribuita e l'output che genera, Step Functions fornisce i seguenti campi:
Oltre a questi campi, Step Functions offre anche la possibilità di definire una soglia di errore tollerata per Distributed Map. Questo valore consente di specificare il numero massimo o la percentuale di elementi non riusciti come soglia di errore per una Map Run. Per ulteriori informazioni sulla configurazione della soglia di errore tollerata, vedere. Impostazione delle soglie di errore per gli stati della mappa distribuita in Step Functions
-
Utilizzo dello stato della mappa distribuita
Fai riferimento ai seguenti tutorial e progetti di esempio per iniziare a utilizzare Distributed Map state.
-
Esamina l'esecuzione dello stato della mappa distribuita
La console Step Functions fornisce una pagina Map Run Details, che mostra tutte le informazioni relative all'esecuzione dello stato di Distributed Map. Per informazioni su come esaminare le informazioni visualizzate in questa pagina, vedereVisualizzazione delle corse delle mappe.
