OPS10-BP01 Utilizzo di un processo per la gestione di eventi, incidenti e problemi
L'organizzazione dispone di processi per gestire eventi, incidenti e problemi. Gli eventi sono costituiti da quanto accade nel carico di lavoro che non necessita di un intervento umano. Gli incidenti sono invece eventi che richiedono un intervento. I problemi sono eventi ricorrenti che richiedono un intervento o che non possono essere risolti. È necessario disporre di processi per ridurre l'impatto degli eventi sull'azienda e accertarsi di reagire in modo tempestivo e appropriato.
Quando nel carico di lavoro si verificano problemi o incidenti, è necessario utilizzare i processi per gestirli. In che modo puoi comunicare lo stato dell'evento alle parti coinvolte? Chi supervisiona la gestione delle risposte? Quali sono gli strumenti da utilizzare per ridurre l'impatto dell'evento? Questi sono solo alcuni esempi delle domande a cui devi rispondere per creare un processo di risposta affidabile.
I processi devono essere documentati in una posizione centralizzata, nonché essere disponibili a chiunque sia coinvolto nel carico di lavoro. Se non è presente un wiki o un archivio di documenti centralizzato, è possibile utilizzare un repository per il controllo delle versioni. In questo modo sarà possibile mantenere aggiornati i piani in modo conforme all'evoluzione dei processi.
I problemi possono essere automatizzati. Il tempo richiesto per la gestione di questo tipo di eventi potrebbe essere altrimenti destinato all'innovazione. Comincia a creare un processo ripetibile per ridurre il più possibile l'impatto del problema. Gradualmente cerca di concentrarti sull'automazione della riduzione o risoluzione del problema sottostante. In questo modo il tempo risparmiato potrà essere dedicato a migliorare il carico di lavoro.
Risultato desiderato: l'organizzazione dispone di un processo per gestire eventi, incidenti e problemi. Questi processi sono documentati e archiviati in una posizione centralizzata e vengono aggiornati in base alle modifiche apportate.
Anti-pattern comuni:
-
Un incidente si verifica durante il fine settimana e il tecnico di turno non sa cosa fare.
-
Un cliente invia un messaggio e-mail indicando che l'applicazione non è disponibile. Riavvii il server per correggere il problema. Questo incidente si verifica di frequente.
-
Si verifica un incidente e più team si mettono a lavorare in modo indipendente per risolvere il problema.
-
Le implementazioni vengono eseguite nel carico di lavoro senza essere documentate.
Vantaggi dell'adozione di questa best practice:
-
Nel carico di lavoro è presente un itinerario di audit degli eventi.
-
Viene ridotto il tempo necessario per il ripristino in seguito a un incidente.
-
I membri dei team riescono a risolvere incidenti e problemi in modo coerente.
-
Durante l'analisi di un incidente, l'approccio è condiviso e più consolidato.
Livello di rischio associato se questa best practice non fosse adottata: alto
Guida all'implementazione
L'implementazione di questa best practice prevede la registrazione degli eventi dei carichi di lavoro. Per la gestione di incidenti e problemi, è necessario ricorrere ai processi. I processi sono documentati, condivisi e aggiornati con frequenza. I problemi vengono identificati, classificati in base alla priorità e corretti.
Esempio del cliente
AnyCompany Retail ha dedicato una parte del proprio wiki interno ai processi destinati alla gestione di eventi, incidenti e problemi. Tutti gli eventi vengono inviati ad Amazon EventBridge. I problemi vengono classificati come OpsItems (elementi di lavoro operativi) in AWS Systems Manager OpsCenter e classificati in base alla loro priorità al fine della loro risoluzione, in modo da ridurre eventuali attività indifferenziate. Quando i processi subiscono variazioni, vengono aggiornati nel wiki interno. Viene utilizzato Strumento di gestione degli incidenti AWS Systems Manager per gestire gli incidenti e coordinare le attività di riduzione dell'impatto.
Passaggi dell'implementazione
-
Eventi
-
Tieni traccia degli eventi che si verificano nel carico di lavoro, anche se non è richiesto alcun intervento umano.
-
Collabora con le parti coinvolte a livello di piano di lavoro per redigere un elenco di eventi di cui tenere traccia, ad esempio implementazioni completate o applicazioni di patch riuscite.
-
Puoi utilizzare servizi come Amazon EventBridge oppure Amazon Simple Notification Service per generare eventi personalizzati per il monitoraggio.
-
-
Incidenti
-
Per prima cosa, definisci il piano di comunicazione per gli incidenti. Quali parti coinvolte devono essere informate? In che modo le tieni costantemente aggiornate? Chi supervisiona il coordinamento di tutte queste attività? È consigliabile creare un canale di chat per le comunicazioni e il coordinamento.
-
Definisci un percorso di escalation per i team di supporto del carico di lavoro, soprattutto se il team non dispone di turni di rotazione della disponibilità. A seconda del livello di supporto, è possibile segnalare un caso anche mediante il Supporto.
-
Crea un playbook per l'analisi dell'incidente. È necessario includere il piano di comunicazione e, in dettaglio, i passaggi del processo di indagine. Includi il controllo del AWS Health Dashboard nel processo di indagine.
-
Documenta il piano di risposta agli incidenti. Comunica il piano di gestione degli incidenti in modo che i clienti esterni siano consapevoli delle regole da seguire e dei comportamenti richiesti previsti. Fornisci formazione ai membri dei team su come utilizzare tale piano di gestione.
-
I clienti possono utilizzare Incident Manager per configurare e gestire il piano di risposta agli incidenti.
-
I clienti del supporto Enterprise possono richiedere di seguire il workshop relativo alla gestione degli incidenti
al proprio Technical Account Manager (TAM). Questo workshop guidato consente di verificare il piano di risposta agli incidenti esistente e ti aiuta a individuare eventuali aree da migliorare.
-
-
Problemi
-
I problemi devono essere identificati e registrati nel sistema ITSM in uso.
-
Identifica tutti i problemi noti ed eseguine una catalogazione in base all'impegno necessario per correggerli e al relativo impatto sul carico di lavoro.
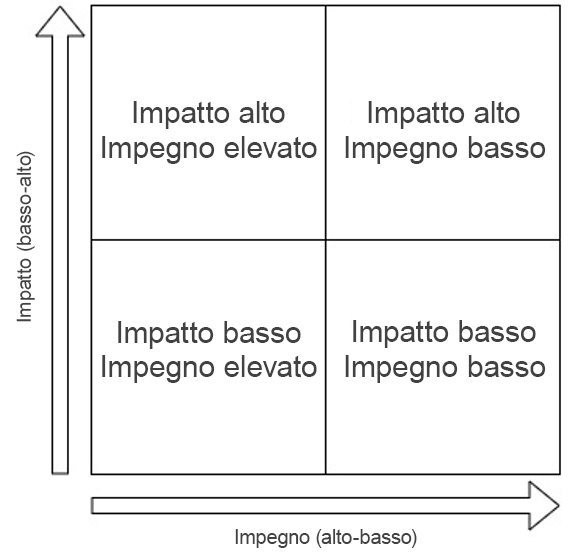
-
Per prima cosa risolvi i problemi caratterizzati dall'impatto più alto e dal minore impegno. Dopodiché, passa alla risoluzione dei problemi che rientrano nel quadrante basso impatto/basso impegno.
-
Puoi utilizzare Systems Manager OpsCenter per identificare i problemi, associarvi runbook e tenerne traccia.
-
Livello di impegno per il piano di implementazione: medio. Devi disporre sia di un processo che degli strumenti per implementare questa best practice. Documenta i processi e rendili disponibili a chiunque sia coinvolto nel carico di lavoro. Aggiornali con frequenza. È disponibile un processo per la gestione e la migrazione o la risoluzione dei problemi.
Risorse
Best practice correlate:
-
OPS07-BP03 Utilizzo di runbook per eseguire le procedure: i problemi noti necessitano di un runbook associato in modo tale che le attività di attenuazione dell'impatto siano coerenti.
-
OPS07-BP04 Utilizzo dei playbook per analizzare i problemi: gli incidenti devono essere analizzati con il supporto di playbook.
-
OPS11-BP02 Esecuzione di analisi post-incidente: esegui sempre un post-mortem dopo aver eseguito un ripristino in seguito a un incidente.
Documenti correlati:
Video correlati:
Esempi correlati:
Servizi correlati:
