Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Evacuazione controllata dal piano dati
Esistono diverse soluzioni che è possibile implementare per eseguire l'evacuazione di una zona di disponibilità utilizzando solo azioni sul piano dati. Questa sezione ne descriverà tre e i casi d'uso in cui potresti preferire l'uno rispetto all'altro.
Quando si utilizza una di queste soluzioni, è necessario assicurarsi di disporre di una capacità sufficiente nelle zone di disponibilità rimanenti per gestire il carico della zona di disponibilità da cui si sta allontanando. Il modo più resiliente per farlo è predisporre la capacità richiesta in ciascuna zona di disponibilità. Se utilizzi tre zone di disponibilità, in ognuna di esse disporrai del 50% della capacità richiesta per gestire il carico di picco, in modo che la perdita di una singola zona di disponibilità lasci comunque il 100% della capacità richiesta senza dover fare affidamento su un piano di controllo per fornirne di più.
Inoltre, se utilizzi EC2 Auto Scaling, assicurati che il tuo gruppo Auto Scaling (ASG) non effettui la scalabilità durante il turno, in modo che, al termine del turno, tu abbia ancora una capacità sufficiente nel gruppo per gestire il traffico dei tuoi clienti. Puoi farlo assicurandoti che la capacità minima desiderata del tuo ASG sia in grado di gestire il carico attuale di clienti. Puoi anche contribuire a garantire che il tuo ASG non venga ridimensionato inavvertitamente utilizzando medie nelle tue metriche anziché metriche percentili anomale come P90 o P99.
Durante un turno, le risorse che non servono più il traffico dovrebbero avere un utilizzo molto basso, ma le altre risorse aumenteranno il loro utilizzo con il nuovo traffico, mantenendo la media abbastanza costante, il che impedirebbe un'azione di scalabilità. Infine, puoi anche utilizzare le impostazioni sanitarie del gruppo target perCAMICEeNLBper specificare il failover DNS con una percentuale o un numero di host sani. Questo impedisce che il traffico venga indirizzato verso una zona di disponibilità che non dispone di un numero sufficiente di host sani.
Cambio di zona in Route 53 Application Recovery Controller (ARC)
La prima soluzione per gli usi di evacuazione delle zone di disponibilitàspostamento zonale nella Route 53 ARC. Questa soluzione può essere utilizzata per carichi di lavoro di richiesta/risposta che utilizzano un NLB o ALB come punto di ingresso per il traffico dei clienti.
Quando rilevi che una zona di disponibilità è compromessa, puoi avviare un cambio di zona con Route 53 ARC. Una volta completata questa operazione e scadute le risposte DNS memorizzate nella cache esistenti, tutte le nuove richieste vengono indirizzate solo alle risorse nelle restanti zone di disponibilità. La figura seguente mostra come funziona lo spostamento zonale. Nella figura seguente abbiamo un record di alias Route 53 perwww.example.comche indicamy-example-nlb-4e2d1f8bb2751e6a.elb.us-east-1.amazonaws.com. Lo spostamento zonale viene eseguito per la zona di disponibilità 3.

Spostamento zonale
Nell'esempio, se l'istanza del database principale non si trova nella zona di disponibilità 3, l'esecuzione dello spostamento zonale è l'unica azione richiesta per ottenere il primo risultato dell'evacuazione, impedendo l'elaborazione del lavoro nella zona di disponibilità interessata. Se il nodo principale si trovava nella zona di disponibilità 3, puoi eseguire un failover avviato manualmente (che si basa sul piano di controllo di Amazon RDS) in coordinamento con il cambio di zona, se Amazon RDS non ha già eseguito il failover automaticamente. Questo sarà vero per tutte le soluzioni controllate dal piano dati in questa sezione.
È necessario avviare lo spostamento zonale utilizzando i comandi CLI o l'API per ridurre al minimo le dipendenze necessarie per avviare l'evacuazione. Più semplice è il processo di evacuazione, più affidabile sarà. I comandi specifici possono essere memorizzati in un runbook locale a cui i tecnici di guardia possono accedere facilmente. Lo spostamento zonale è la soluzione più preferita e più semplice per evacuare una zona di disponibilità.
Route 53 ARC
La seconda soluzione utilizza le funzionalità di Route 53 ARC per specificare manualmente lo stato di salute di record DNS specifici. Questa soluzione ha il vantaggio di utilizzare il piano dati del cluster Route 53 ARC ad alta disponibilità, rendendola resiliente alla compromissione di un massimo di due diversiRegioni AWS. Ha il compromesso di costi aggiuntivi e richiede una configurazione aggiuntiva dei record DNS. Per implementare questo modello, è necessario creare record di alias perNomi DNS specifici della zona di disponibilitàfornito dal sistema di bilanciamento del carico (ALB o NLB). Questo è illustrato nella tabella seguente.
Tabella 3: record di alias Route 53 configurati per i nomi DNS zonali del load balancer
|
Politica di routing: ponderato Nome: Tipo: Value (Valore): Peso: Valuta la salute di Target: vero |
Politica di routing:ponderata Nome: Tipo: Valore: Peso: Valuta la salute di Target: |
Politica di routing:ponderata Nome: Tipo: Valore: Peso: Valuta la salute di Target: |
Per ognuno di questi record DNS, è necessario configurare un controllo dello stato di Route 53 associato a un Route 53 ARCcontrollo del routing. Quando desideri avviare un'evacuazione della zona di disponibilità, imposta lo stato di controllo del routing suOff.AWSconsiglia di eseguire questa operazione utilizzando la CLI o l'API per ridurre al minimo le dipendenze necessarie per avviare l'evacuazione della zona di disponibilità. Come unbest practice, è necessario conservare una copia locale degli endpoint del cluster Route 53 ARC in modo da non doverli recuperare dal piano di controllo ARC quando è necessario eseguire un'evacuazione.
Per ridurre al minimo i costi quando si utilizza questo approccio, è possibile creare un singolo cluster Route 53 ARC e controllare lo stato di salute in un'unica soluzioneAccount AWSecondividere i controlli sanitari con altriAccount AWSuse1-az1) anziché il nome della zona di disponibilità (ad esempio,us-east-1a) per i controlli di routing. PerchéAWSassocia la zona di disponibilità fisica in modo casuale ai nomi delle zone di disponibilità per ciascunaAccount AWS, l'utilizzo dell'AZ-ID fornisce un modo coerente per fare riferimento alle stesse posizioni fisiche. Quando avviate l'evacuazione di una zona di disponibilità, diteuse1-az2, i record della Route 53 in ciascunoAccount AWSdovrebbero assicurarsi di utilizzare la mappatura AZ-ID per configurare il corretto controllo dello stato di salute per ogni record NLB.
Ad esempio, supponiamo di avere un controllo di integrità della Route 53 associato a un controllo di routing Route 53 ARC peruse1-az2, con un ID di0385ed2d-d65c-4f63-a19b-2412a31ef431. Se in un altroAccount AWSche desidera utilizzare questo controllo sanitario,us-east-1cè stato mappato suuse1-az2, dovresti usare iluse1-az2controllo sanitario per la registrazioneus-east-1c.load-balancer-name.elb.us-east-1.amazonaws.com. Utilizzeresti l'ID del controllo sanitario0385ed2d-d65c-4f63-a19b-2412a31ef431con quel set di record di risorse.
Utilizzo di un endpoint HTTP autogestito
È inoltre possibile implementare questa soluzione gestendo il proprio endpoint HTTP che indica lo stato di una particolare zona di disponibilità. Consente di specificare manualmente quando una zona di disponibilità non è integra in base alla risposta dell'endpoint HTTP. Questa soluzione costa meno rispetto all'utilizzo di Route 53 ARC, ma è più costosa del trasferimento zonale e richiede la gestione di un'infrastruttura aggiuntiva. Ha il vantaggio di essere molto più flessibile per diversi scenari.
Il pattern può essere utilizzato con architetture NLB o ALB e controlli di integrità della Route 53. Può essere utilizzato anche in architetture non bilanciate dal carico, come i sistemi di rilevamento dei servizi o di elaborazione delle code in cui i nodi di lavoro eseguono i propri controlli di integrità. In questi scenari, gli host possono utilizzare un thread in background in cui effettuano periodicamente una richiesta all'endpoint HTTP con il proprio AZ-ID (fare riferimento aAppendice A — Ottenere l'ID della zona di disponibilità per dettagli su come trovarlo) e ricevere una risposta sullo stato della zona di disponibilità.
Se la zona di disponibilità è stata dichiarata non integra, hanno diverse opzioni su come rispondere. Possono scegliere di non superare un controllo dello stato esterno proveniente da fonti come ELB, Route 53 o controlli di integrità personalizzati nelle architetture di Service Discovery, in modo da apparire non integri a tali servizi. Possono anche rispondere immediatamente con un errore se ricevono una richiesta, consentendo al client di fare marcia indietro e riprovare. Nelle architetture basate su eventi, i nodi possono intenzionalmente non riuscire a elaborare il lavoro, ad esempio restituendo intenzionalmente un messaggio SQS alla coda. Nelle architetture di router di lavoro in cui un servizio centrale pianifica il lavoro su host specifici, è possibile utilizzare anche questo modello. Il router può verificare lo stato di una zona di disponibilità prima di selezionare un worker, un endpoint o una cella. Architetture di ricerca dei servizi che utilizzanoAWS Cloud Map, puoiscopri gli endpoint fornendo un filtro nella tua richiesta
La figura seguente mostra come questo approccio può essere utilizzato per più tipi di carichi di lavoro.
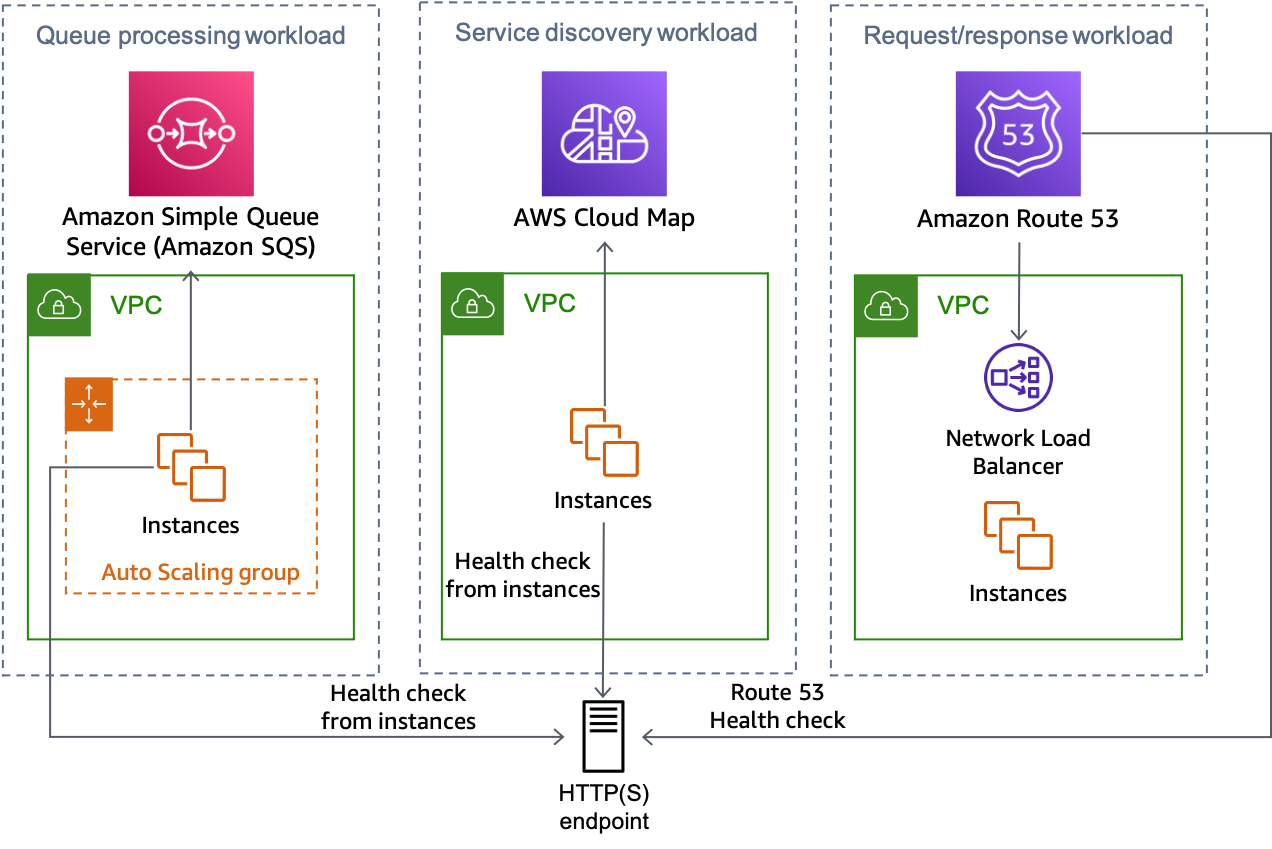
La soluzione endpoint HTTP può essere utilizzata da più tipi di carico di lavoro
Esistono diversi modi per implementare l'approccio degli endpoint HTTP, due dei quali sono descritti di seguito.
Uso di Amazon S3
Questo modello è stato originariamente presentato in questopost sul blog
In questo scenario, creeresti set di record di risorse DNS Route 53 per ogni record DNS zonale proprio comePercorso 53 ARCscenario precedente e relativi controlli sanitari. Tuttavia, per questa implementazione, invece di associare i controlli di integrità ai controlli di routing ARC della Route 53, sono configurati per utilizzare unEndpoint HTTPe sono invertiti per evitare che un guasto in Amazon S3 provochi accidentalmente un'evacuazione. Il controllo sanitario è consideratosalutarequando l'oggetto è assente emalsanoquando l'oggetto è presente. Questa configurazione è mostrata nella tabella seguente.
Tabella 4: Configurazione dei record DNS per l'utilizzo dei controlli di integrità della Route 53 per zona di disponibilità
|
Tipo di controllo sanitario: monitorare un endpoint Protocol (Protocollo): ID: URL: |
Tipo di controllo sanitario: monitorare un endpoint Protocol (Protocollo): ID: URL: |
Tipo di controllo sanitario: monitorare un endpoint Protocol (Protocollo): ID: URL: |
← | Controlli sanitari |
| ↑ | ↑ | ↑ | ||
|
Politica di routing: ponderato Nome: Tipo: Value (Valore): Peso: Valuta la salute di Target: |
Politica di routing:ponderata Nome: Tipo: Value (Valore): Peso: Valuta la salute di Target: |
Politica di routing:ponderata Nome: Tipo: Value (Valore): Peso: Valuta la salute di Target: |
← | I record di alias A di livello superiore con ponderazione uniforme puntano a endpoint specifici di NLB AZ |
Supponiamo che la zona di disponibilitàus-east-1aè mappato suuse1-az3nell'account in cui abbiamo un carico di lavoro in cui vogliamo eseguire un'evacuazione della zona di disponibilità. Per il set di record di risorse creato perus-east-1a.load-balancer-name.elb.us-east-1.amazonaws.comassocerebbe un controllo dello stato di salute che verifica l'URLhttps://. Quando si desidera avviare un'evacuazione della zona di disponibilità perbucket-name.s3.us-east-1.amazonaws.com/use1-az3.txtuse1-az3, carica un file denominatouse1-az3.txtal bucket utilizzando la CLI o l'API. Il file non deve contenere alcun contenuto, ma deve essere pubblico in modo che il controllo sanitario di Route 53 possa accedervi. La figura seguente mostra che questa implementazione viene utilizzata per evacuareuse1-az3.
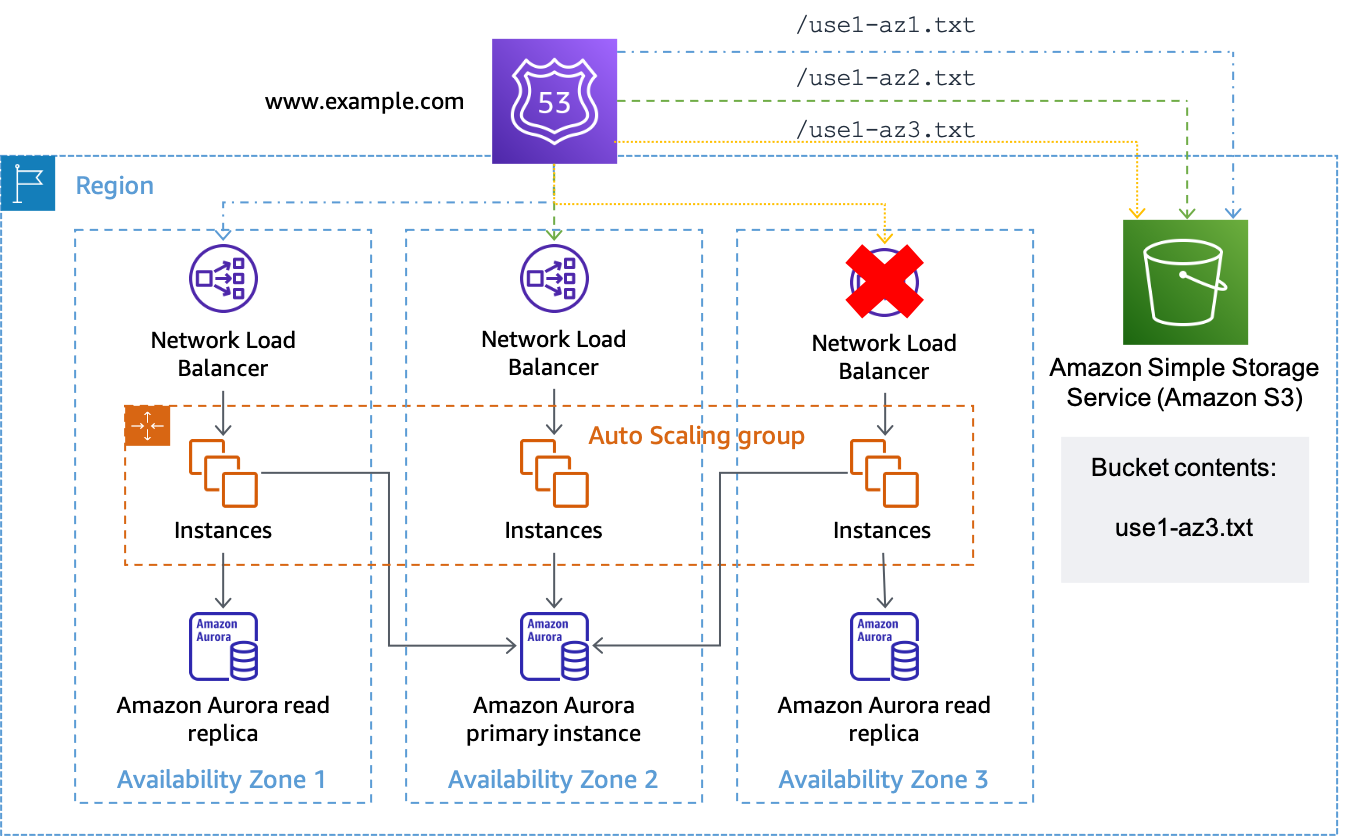
Utilizzo di Amazon S3 come obiettivo per un controllo dello stato della Route 53
Utilizzo di API Gateway e DynamoDB
La seconda implementazione di questo modello utilizza unGateway API Amazon
Se utilizzi questa soluzione con un'architettura NLB o ALB, configura i tuoi record DNS nello stesso modo dell'esempio di Amazon S3 sopra riportato, tranne modificare il percorso di controllo dello stato per utilizzare l'endpoint API Gateway e fornire ilAZ-IDnel percorso dell'URL. Ad esempio, se l'API Gateway è configurato con un dominio personalizzato diaz-status.example.com, la richiesta completa diuse1-az1assomiglierebbehttps://az-status.example.com/status/use1-az1. Quando desideri avviare un'evacuazione della zona di disponibilità, puoi creare o aggiornare un elemento DynamoDB utilizzando l'interfaccia a riga di comando o l'API. L'articolo utilizza ilAZ-IDcome chiave primaria e quindi ha un attributo booleano chiamatoHealthyche viene utilizzato indica come risponde API Gateway. Di seguito è riportato un esempio di codice utilizzato nella configurazione di API Gateway per effettuare questa determinazione.
#set($inputRoot = $input.path('$')) #if ($inputRoot.Item.Healthy['BOOL'] == (false)) #set($context.responseOverride.status = 500) #end
Se l'attributo ètrue(o non è presente), API Gateway risponde al controllo dello stato con un HTTP 200, se è falso, risponde con un HTTP 500. Questa implementazione è illustrata nella figura seguente.
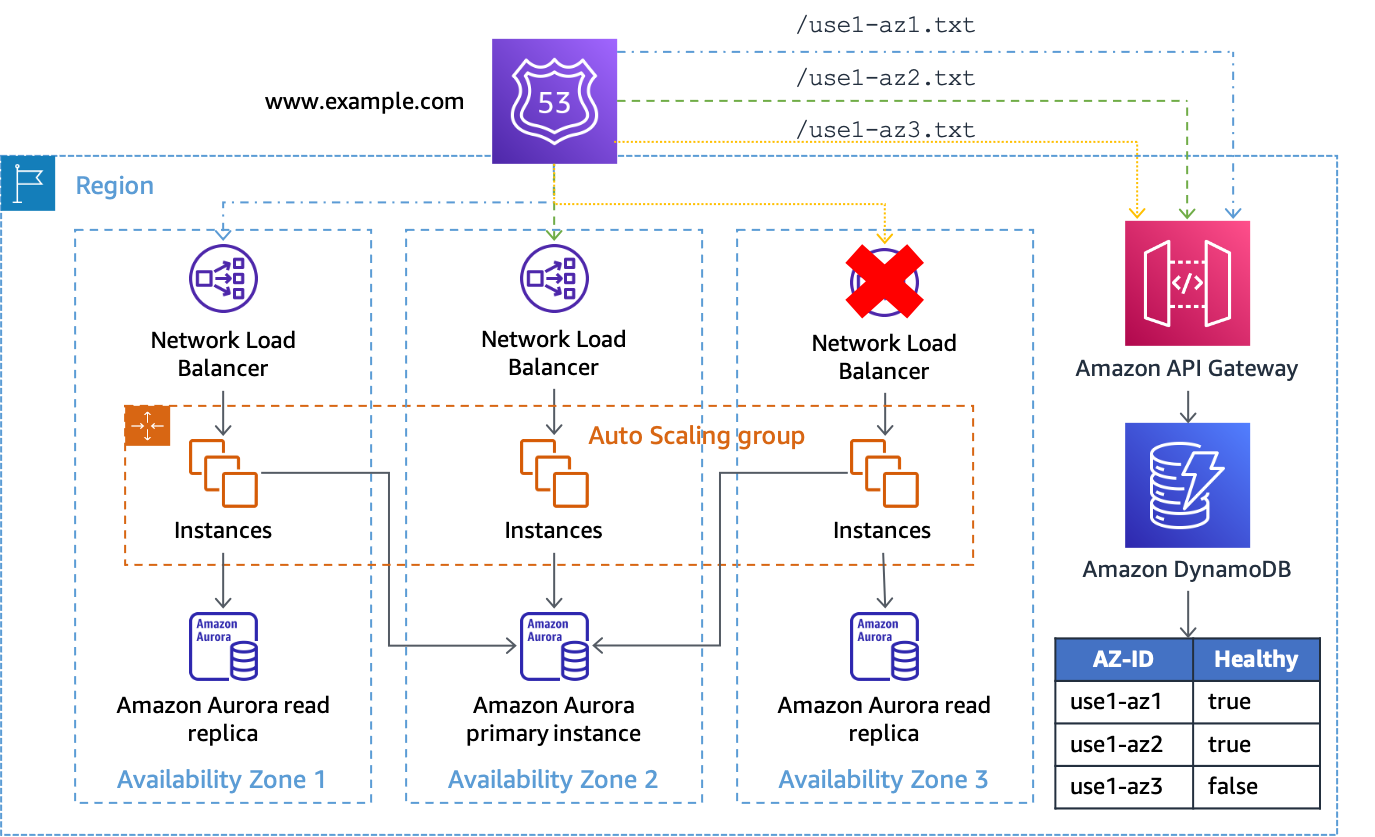
Utilizzo di API Gateway e DynamoDB come obiettivo dei controlli di integrità della Route 53
In questa soluzione è necessario utilizzare API Gateway davanti a DynamoDB in modo da poter rendere l'endpoint accessibile al pubblico e manipolare l'URL della richiesta in unGetItemrichiesta per DynamoDB. La soluzione offre anche flessibilità se si desidera includere dati aggiuntivi nella richiesta. Ad esempio, se desideri creare stati più granulari, ad esempio per applicazione, puoi configurare l'URL del controllo dello stato per fornire un ID dell'applicazione nel percorso o nella stringa di query che sia anche confrontato con l'elemento DynamoDB.
L'endpoint di stato della zona di disponibilità può essere distribuito centralmente in modo che più risorse di controllo dello stato di salute siano distribuite su tutto il territorioAccount AWSpossono tutti utilizzare la stessa visione coerente dello stato della zona di disponibilità (assicurando che l'API REST di API Gateway e la tabella DynamoDB siano scalate per gestire il carico) ed elimina la necessità di condividere i controlli di integrità della Route 53.
La soluzione può anche essere scalata su più livelliRegioni AWSutilizzando unTabella globale Amazon DynamoDB
Se stavi creando una soluzione per i singoli host da utilizzare come meccanismo per determinare lo stato della loro AZ, in alternativa, invece di fornire un meccanismo di richiamo per i controlli dello stato, puoi utilizzare le notifiche push. Un modo per farlo è utilizzare un argomento SNS a cui i tuoi consumatori sono abbonati. Quando desideri attivare l'interruttore automatico, pubblica un messaggio nell'argomento SNS indicando quale zona di disponibilità è compromessa. Questo approccio fa dei compromessi con il primo. Elimina la necessità di creare e gestire l'infrastruttura API Gateway ed eseguire la gestione della capacità. Può anche fornire una convergenza più rapida dello stato della zona di disponibilità. Tuttavia, elimina la possibilità di eseguire interrogazioni ad hoc e si basa suPolitica dei tentativi di consegna SNSper garantire che ogni endpoint riceva la notifica. Richiede inoltre che ogni carico di lavoro o servizio crei un modo per ricevere la notifica SNS e intervenire in merito.
Ad esempio, ogni nuova istanza o contenitore EC2 che viene lanciato dovrà sottoscrivere l'argomento con un endpoint HTTP durante il bootstrap. Quindi, ogni istanza deve implementare un software che ascolti l'endpoint da cui viene recapitata la notifica. Inoltre, se l'istanza è interessata dall'evento, potrebbe non ricevere la notifica push e continuare a funzionare. Invece, con una notifica pull, l'istanza saprà se la sua richiesta di pull fallisce e potrà scegliere quale azione intraprendere in risposta.
Un secondo modo per inviare notifiche push è quello di lunga durataWebSocketconnessioni. Amazon API Gateway può essere utilizzato per fornire unWebSocketAPIa cui i consumatori possono connettersi e ricevere un messaggio quandoinviato dal backend. Con unWebSocket, le istanze possono sia eseguire interruzioni periodiche per garantire che la connessione sia funzionante sia ricevere notifiche push a bassa latenza.
