Scenario 5: monitoraggio dei dati di telemetria in tempo reale con Apache Kafka
ABC1cabs è una società di servizi di prenotazione di taxi online. Tutti taxi dispongono di dispositivi IoT che raccolgono dati di telemetria dai veicoli. Attualmente, ABC1Cabs esegue cluster Apache Kafka progettati per il consumo di eventi in tempo reale, la raccolta di parametri di integrità del sistema, il monitoraggio delle attività e l'inserimento dei dati nella piattaforma Apache Spark Streaming basata su un cluster Hadoop On-Premise.
ABC1Cabs utilizza OpenSearch Dashboards per parametri aziendali, debug, avvisi e creazione di altri pannelli di controllo. Sono interessati ad Amazon MSK, Amazon EMR con Spark Streaming e a OpenSearch Service con OpenSearch Dashboards. Il requisito è ridurre il sovraccarico amministrativo per la gestione dei cluster Apache Kafka e Hadoop, utilizzando al contempo software open source e API note per orchestrare la pipeline dei dati. Il seguente diagramma di architettura mostra la soluzione su AWS.
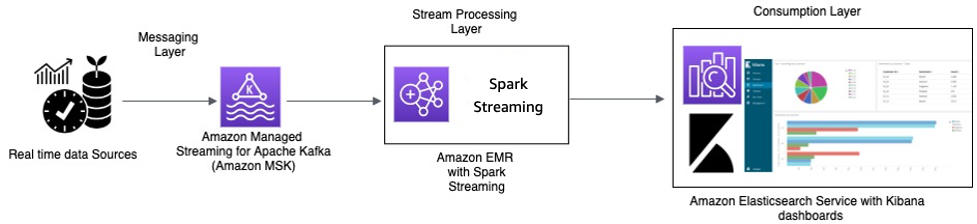
Elaborazione in tempo reale con Amazon MSK ed elaborazione Stream mediante Apache Spark Streaming su Amazon EMR e Amazon OpenSearch Service con OpenSearch Dashboards
I dispositivi IoT dei taxi raccolgono dati di telemetria e li inviano a un hub di origine. L'hub di origine è configurato per inviare dati in tempo reale ad Amazon MSK. Utilizzando le API della libreria producer Apache Kafka, Amazon MSK è configurato per la trasmissione dei dati in un cluster Amazon EMR. Il cluster Amazon EMR ha un client Kafka e Spark Streaming installati per poter utilizzare ed elaborare i flussi di dati.
Spark Streaming ha connettori sink che possono scrivere dati direttamente su indici definiti di Elasticsearch. I cluster Elasticsearch con OpenSearch Dashboards possono essere utilizzati per parametri e pannelli di controllo. Amazon MSK, Amazon EMR con Spark Streaming e OpenSearch Service con OpenSearch Dashboards sono tutti servizi gestiti, in cui AWS gestisce il pesante carico indifferenziato della gestione dell'infrastruttura di diversi cluster, che ti consente di costruire la tua applicazione utilizzando un software open source noto con pochi clic. La sezione successiva esamina più da vicino questi servizi.
Amazon Managed Streaming for Apache Kafka (Amazon MSK)
Apache Kafka è una piattaforma open source che consente ai clienti di acquisire dati di streaming come eventi di flussi di clic, transazioni, eventi IoT e registri di applicazioni e computer. Con queste informazioni, è possibile sviluppare applicazioni che eseguono analisi dei dati in tempo reale, eseguono trasformazioni continue e distribuiscono questi dati a data lake e database in tempo reale.
È possibile utilizzare Kafka come archivio dati di streaming per disaccoppiare le applicazioni producer e consumer e consentire un trasferimento affidabile dei dati tra i due componenti. Sebbene Kafka sia una popolare piattaforma aziendale di streaming dei dati e messaggistica, può essere difficile da configurare, dimensionare e gestire in produzione.
Amazon MSK si occupa di queste attività di gestione e semplifica l'impostazione, la configurazione e l'esecuzione di Kafka, insieme ad Apache Zookeeper, in un ambiente che segue le best practice per la disponibilità e la sicurezza elevate. È ancora possibile utilizzare le operazioni del piano di controllo e le operazioni del piano dati di Kafka per gestire la produzione e il consumo di dati.
Poiché Amazon MSK esegue e gestisce Apache Kafka open source, semplifica la migrazione e l'esecuzione delle applicazioni Apache Kafka esistenti in AWS senza dover apportare modifiche al codice dell'applicazione.
Dimensionamento
Amazon MSK offre operazioni di dimensionamento in modo che l'utente possa dimensionare attivamente il cluster durante l'esecuzione. Quando crei un cluster Amazon MSK, puoi specificare il tipo di istanza dei broker al momento dell'avvio del cluster. Puoi iniziare con alcuni broker all'interno di un cluster Amazon MSK. Quindi, utilizzando la AWS Management Console o AWS CLI, puoi aumentare fino a centinaia di broker per cluster.
In alternativa, puoi dimensionare i tuoi cluster cambiando le dimensioni o la famiglia dei tuoi broker Apache Kafka. Cambiando le dimensioni o la famiglia dei tuoi broker, otterrai la flessibilità necessaria per adattare la capacità di elaborazione nel cluster Amazon MSK ed effettuare delle modifiche ai carichi di lavoro. Utilizza il foglio di calcolo Dimensionamento e prezzi di Amazon MSK
Dopo aver creato il cluster Amazon MSK, puoi aumentare la quantità di archiviazione EBS per broker, ad eccezione della riduzione dello spazio di archiviazione. I volumi di archiviazione rimangono disponibili durante questa operazione di dimensionamento. Offre due tipi di operazioni di dimensionamento: scalabilità automatica e manuale.
Amazon MSK supporta l'espansione automatica dell'archiviazione del cluster in risposta a un maggiore utilizzo utilizzando le policy di scalabilità automatica delle applicazioni. La policy di scalabilità automatica imposta l'utilizzo del disco di destinazione e la capacità di dimensionamento massimo.
La soglia di utilizzo dell'archiviazione aiuta Amazon MSK ad attivare un'operazione di scalabilità automatica. Per aumentare lo spazio di archiviazione utilizzando il dimensionamento manuale, attendi che il cluster si trovi nello stato ACTIVE. Il dimensionamento dell'archiviazione ha un tempo di raffreddamento di almeno sei ore tra un evento e l'altro. Anche se l'operazione rende immediatamente disponibile archiviazione aggiuntiva, il servizio esegue ottimizzazioni sul cluster che possono richiedere fino a 24 ore o più.
La durata di queste ottimizzazioni è proporzionale alle dimensioni dell'archiviazione. Inoltre, offre anche la replica di zone di disponibilità multipla all'interno di una regione AWS per fornire elevata disponibilità.
Configurazione
Amazon MSK fornisce una configurazione di default per broker, argomenti e nodi Apache ZooKeeper. Puoi inoltre creare configurazioni personalizzate e utilizzarle per creare nuovi cluster Amazon MSK o per aggiornare cluster esistenti. Quando crei un cluster MSK senza specificare una configurazione Amazon MSK personalizzata, Amazon MSK crea e utilizza una configurazione di default. Per un elenco dei valori di default, consulta la pagina relativa alla configurazione di Apache Kafka.
Per scopi di monitoraggio, Amazon MSK raccoglie i parametri di Apache Kafka e li invia ad Amazon CloudWatch, dove è possibile visualizzarli. I parametri configurati per i cluster MSK sono automaticamente raccolti e inviati a CloudWatch. Il monitoraggio del ritardo dei consumer consente di identificare quelli lenti o bloccati che non sono al passo con i dati più recenti disponibili in un argomento. Se necessario, è quindi possibile intraprendere operazioni correttive, come il dimensionamento o il riavvio di tali consumer.
Migrazione ad Amazon MSK
La migrazione dall'ambiente on-premise ad Amazon MSK può essere effettuata con uno dei seguenti metodi.
-
MirrorMaker2.0: MirrorMaker2.0 (MM2) MM2 è un motore di replica di dati multi-cluster basato sul framework Apache Kafka Connect. MM2 è una combinazione di un connettore origine Apache Kafka e un connettore sink. È possibile utilizzare un singolo cluster MM2 per migrare i dati tra più cluster. MM2 rileva automaticamente nuovi argomenti e partizioni, garantendo allo stesso tempo che le configurazioni degli argomenti siano sincronizzate tra i cluster. MM2 supporta ACL di migrazioni, configurazioni di argomenti e conversione di offset. Per ulteriori dettagli sulla migrazione, consulta Migrazione di cluster utilizzando MirrorMaker di Apache Kafka. MM2 viene utilizzato per casi d'uso relativi alla replica di configurazioni di argomenti e conversione automatica di offset.
-
Apache Flink: MM2 supporta la semantica "exactly-once". I record possono essere duplicati nella destinazione ed è previsto che i consumer siano idempotenti per gestire i record duplicati. In scenari "exactly-once", la semantica è richiesta ai clienti che possono utilizzare Apache Flink. Fornisce un'alternativa per la semantica "exactly-once".
Apache Flink può essere utilizzato anche per scenari in cui i dati richiedono operazioni di mappatura o trasformazione prima dell'invio al cluster di destinazione. Apache Flink fornisce connettori per Apache Kafka con origini e sink in grado di leggere i dati da un cluster Apache Kafka e scrivere su un altro. Apache Flink può essere eseguito su AWS avviando un cluster Amazon EMR o eseguendo Apache Flink come applicazione utilizzando Amazon Kinesis Data Analytics.
-
AWS Lambda: con il supporto per Apache Kafka come origine di eventi per AWS Lambda
, i clienti possono ora utilizzare messaggi da un argomento tramite una funzione Lambda. Il servizio AWS Lambda esegue internamente il polling per nuovi record o messaggi dall'origine eventi, quindi richiama in modo sincrono la funzione Lambda di destinazione per consumare i messaggi. Lambda legge i messaggi in batch e fornisce i batch di messaggi alla funzione nel payload dell'evento per l'elaborazione. I messaggi consumati possono quindi essere trasformati e/o scritti direttamente nel cluster Amazon MSK di destinazione.
Amazon EMR con Spark Streaming
Amazon EMR
Amazon EMR offre le funzionalità di Spark e può essere utilizzato per avviare Spark Streaming Spark per consumare dati da Kafka. Spark Streaming è un'estensione dell'API Spark principale che consente l'elaborazione di flussi dei dati in tempo reale scalabile, a velocità effettiva elevata e tollerante ai guasti.
Puoi creare un cluster Amazon EMR utilizzando AWS Command Line Interface
I dati elaborati possono essere inviati a file system, database e pannelli di controllo.
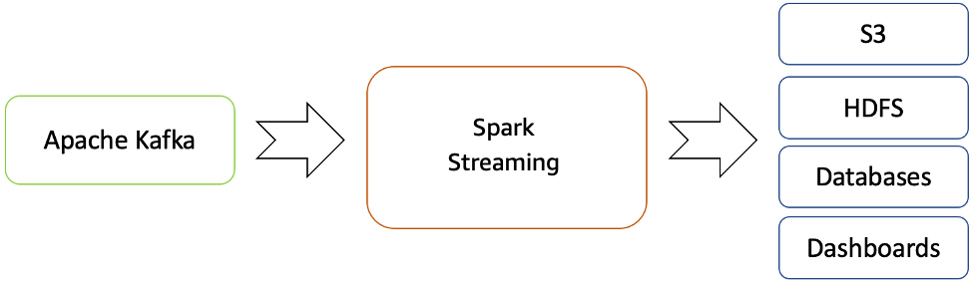
Flusso di streaming in tempo reale da Apache Kafka all'ecosistema Hadoop
Di default, Apache Spark Streaming ha un modello di esecuzione in micro-batch. Tuttavia, a partire da Spark 2.3, Apache ha introdotto una nuova modalità di elaborazione a bassa latenza chiamata Continuous Processing, che può raggiungere latenze end-to-end fino a un millisecondo con garanzie "at-least-once".
Senza modificare le operazioni DataSet/DataFrames nelle query, è possibile scegliere la modalità in base ai requisiti dell'applicazione. Alcuni dei vantaggi di Spark Streaming sono:
-
Utilizza l'API integrata nel linguaggio
di Apache Spark per l'elaborazione dello streaming, consentendoti di scrivere processi di streaming nello stesso modo in cui scrivi processi batch. -
Supporta Java, Scala e Python.
-
Può recuperare sia il lavoro perso che lo stato dell'operatore (come finestre scorrevoli) immediatamente, senza alcun codice aggiuntivo da parte dell'utente.
-
In esecuzione su Spark, Spark Streaming consente di riutilizzare lo stesso codice per l'elaborazione batch, unire i flussi con dati cronologici o eseguire query ad hoc sullo stato del flusso e costruire potenti applicazioni interattive, non solamente l'analisi dei dati.
-
Dopo che il flusso di dati è stato elaborato con Spark Streaming, OpenSearch Sink Connector può essere utilizzato per scrivere dati nel cluster OpenSearch Service e, a sua volta, OpenSearch Service con OpenSearch Dashboards può essere utilizzato come livello di consumo.
Amazon OpenSearch Service con OpenSearch Dashboards
OpenSearch Service è un servizio gestito che semplifica implementazione, funzionamento e dimensionamento di cluster OpenSearch in AWS Cloud. OpenSearch è un diffuso motore di ricerca e analisi dei dati open source per casi d'uso come analisi dei dati dei registri, monitoraggio delle applicazioni in tempo reale e analisi dei clickstream.
OpenSearch Dashboards
OpenSearch Dashboards fornisce una perfetta integrazione con OpenSearch
Riepilogo
Con Apache Kafka offerto come servizio gestito su AWS, puoi concentrarti sul consumo piuttosto che sulla gestione del coordinamento tra i broker, che di solito richiede una conoscenza approfondita di Apache Kafka. Caratteristiche come l'elevata disponibilità, la scalabilità dei broker e il controllo granulare degli accessi sono gestite dalla piattaforma Amazon MSK.
ABC1CAB ha utilizzato questi servizi per costruire applicazioni di produzione senza bisogno di competenze nella gestione dell'infrastruttura. È stato possibile concentrarsi sul livello di elaborazione per consumare dati da Amazon MSK e propagare ulteriormente al livello di visualizzazione.
Spark Streaming su Amazon EMR può aiutare l'analisi dei dati di streaming in tempo reale e la pubblicazione su OpenSearch Dashboards
