Fase 1: raccolta e aggregazione dei dati
La figura seguente mostra un modello mentale per il problema di previsione. L'obiettivo è prevedere la serie temporale z_t nel futuro, usando quante più informazioni pertinenti per rendere la previsione il più accurata possibile. Di conseguenza, la prima e più importante fase consiste nel raccogliere quanti più dati corretti possibile.
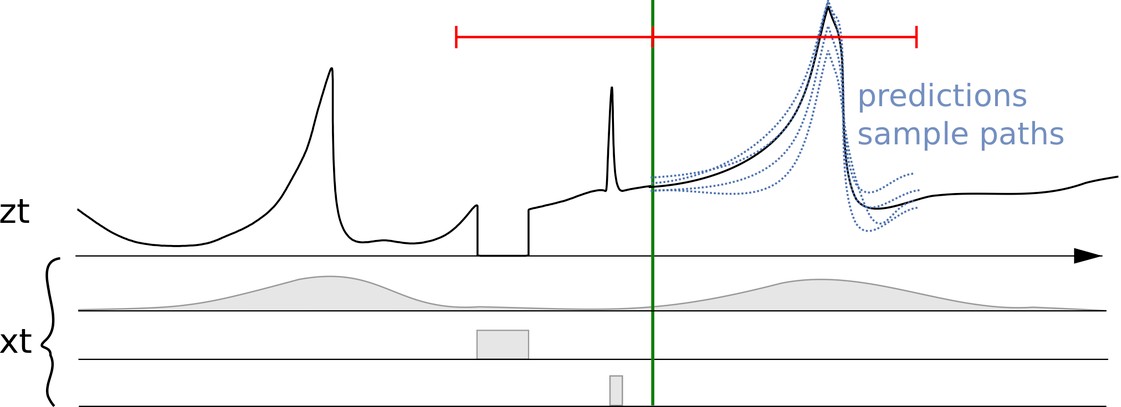
Serie temporale z_t insieme a caratteristiche o covariate (x_t) associate e previsioni multiple
La figura precedente mostra previsioni multiple a destra della linea verticale. Queste previsioni sono esempi della distribuzione della previsione probabilistica o, viceversa, possono essere usate per rappresentare la previsione probabilistica.
Le informazioni principali che un'azienda di vendita al dettaglio deve registrare sono le seguenti:
-
Dati sulle vendite transazionali: ad esempio, SKU (codice di riferimento del prodotto), ubicazione, timestamp e unità vendute.
-
Dati relativi ai dettagli degli articoli degli SKU: metadati di un articolo. Alcuni esempi includono colore, reparto, dimensioni e così via.
-
Dati sui prezzi: serie temporale dei prezzi di ogni articolo con timestamp.
-
Dati informativi sulle promozioni: diversi tipi di promozioni, su una raccolta di articoli (categoria) o su singoli articoli con timestamp.
-
Dati informativi sulla disponibilità in magazzino: per ogni unità di tempo, informazioni relative alla disponibilità in magazzino o alla possibilità di acquisto di uno SKU rispetto alla non disponibilità.
-
Dati sull'ubicazione: l'ubicazione di un articolo o la vendita in un momento specifico può essere rappresentata come stringa
location_idstore_ido come effettiva geolocalizzazione. Le geolocalizzazioni possono essere costituite dal codice del paese più il codice postale o da coordinatelatitude_longitude. L'ubicazione è considerata una "dimensione" delle vendite transazionali.
In Amazon Forecast
Le informazioni sulla disponibilità in magazzino sono importanti perché questo problema è incentrato sulla previsione della domanda e non delle vendite, ma l'azienda registra solo le vendite. Quando uno SKU non è più disponibile, il numero di vendite è inferiore alla potenziale domanda ed è quindi importante identificare e registrare quando si verificano questi eventi di esaurimento delle scorte.
Altri set di dati da considerare includono il numero di visite nelle pagine Web, i dettagli sui termini di ricerca, attività nei social media e le informazioni sul meteo. Spesso è importante avere a disposizione dati per il passato e per il futuro da usare nei modelli. Questo è un requisito di molti modelli di previsione e per il backtesting (descritto nella sezione Fase 4: valutazione delle previsioni).
Per alcuni problemi di previsione, la frequenza dei dati non elaborati corrisponde naturalmente a quella del problema di previsione. Tra gli esempi è inclusa la richiesta del volume di server, campionata al minuto, per eseguire previsioni alla frequenza di un minuto.
I dati vengono spesso registrati a una frequenza maggiore o semplicemente con timestamp arbitrari all'interno di un intervallo di tempo, ma il problema di previsione avviene a un livello di dettaglio più grossolano. Si tratta di un evento comune nel caso di studio per la vendita al dettaglio, in cui i dati di vendita vengono registrati in genere come dati transazionali. Ad esempio, il formato è costituito da un timestamp con un livello di dettaglio elevato relativamente a quando hanno avuto luogo le vendite. Nel caso d'uso delle previsioni, questo basso livello di dettaglio può non essere necessario e può essere più appropriato aggregare i dati in vendite orarie o giornaliere. Qui il livello di aggregazione corrisponde al problema a valle, ad esempio la gestione dell'inventario o la pianificazione delle risorse.
Esempio
Il grafico a sinistra nella figura seguente mostra un esempio dei dati non elaborati sulle vendite ai clienti, che possono essere immessi in Amazon Forecast come file con valori separati da virgole (CSV). In questo esempio i dati di vendita sono definiti su una griglia temporale giornaliera più precisa e il problema consiste nel prevedere la domanda settimanale in futuro sulla griglia temporale più grossolana. Amazon Forecast esegue l'aggregazione dei valori giornalieri in una determinata settimana nella chiamata API create_predictor.
Il risultato trasforma i dati non elaborati in una raccolta di serie temporali dal formato corretto con una frequenza settimanale fissa. Il grafico a destra mostra questa aggregazione nella serie temporale di destinazione usando il metodo di aggregazione sommatoria predefinito. Altri metodi di aggregazione includono media, massimo, minimo o la scelta di un singolo punto, ad esempio il primo. Il livello di dettaglio e il metodo di aggregazione devono essere scelti in modo che corrispondano al meglio ai dati del caso d'uso aziendale. In questo esempio il valore aggregato è allineato all'aggregazione settimanale. Altri metodi di aggregazione possono essere impostati dall'utente usando la chiave FeaturizationMethodParameters del parametro FeaturizationConfig dell'API create_predictor.
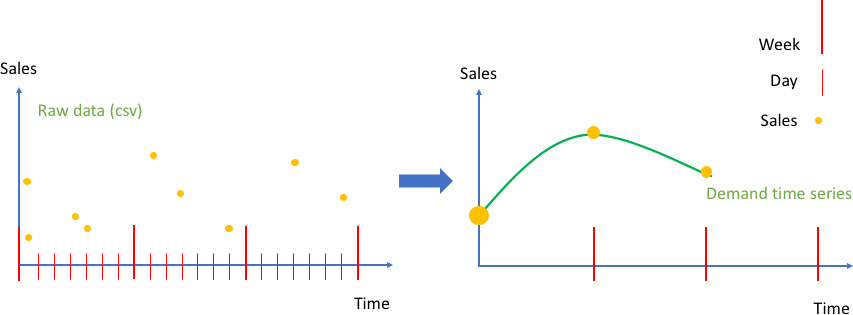
Aggregazione di dati di vendita non elaborati come eventi (a sinistra), in una serie temporale equidistante (a destra)
