例: Application Signals を使用して、運用状態の問題を解決する
以下のシナリオは、Application Signals を使用して、サービスをモニタリングし、サービス品質の問題を特定する方法の例を示しています。ドリルダウンして潜在的な根本原因を特定し、問題を解決するための対策を講じます。この例は、DynamoDB といった AWS のサービスを呼び出す複数のマイクロサービスで構成されるペットクリニックアプリケーションに焦点を当てています。
Jane は、ペットクリニックアプリケーションの運用状態を監督する DevOps チームの一員です。Jane のチームは、アプリケーションの可用性と応答性が高いことを確認することに全力を注いでいます。チームは、サービスレベル目標 (SLO) を使用して、これらのビジネス上のコミットメントに対するアプリケーションのパフォーマンスを測定します。彼女は、複数のサービスレベル指標 (SLI) が異常であるという警告を受け取ります。CloudWatch コンソールを開いてサービスページに移動すると、いくつかのサービスが異常な状態であることがわかりました。

Jane は、ページの上部を見て、障害率で最上位のサービスが visits-service であることを知りました。彼女がグラフ内のリンクを選択すると、そのサービスのサービス詳細ページが開きました。サービスのオペレーションテーブルには、異常なオペレーションがありました。このオペレーションを選択すると、[量と可用性] グラフが表示されました。そのグラフから、定期的な呼び出し量の急増と可用性の一時的低下には相関関係があるらしいことがわかりました。
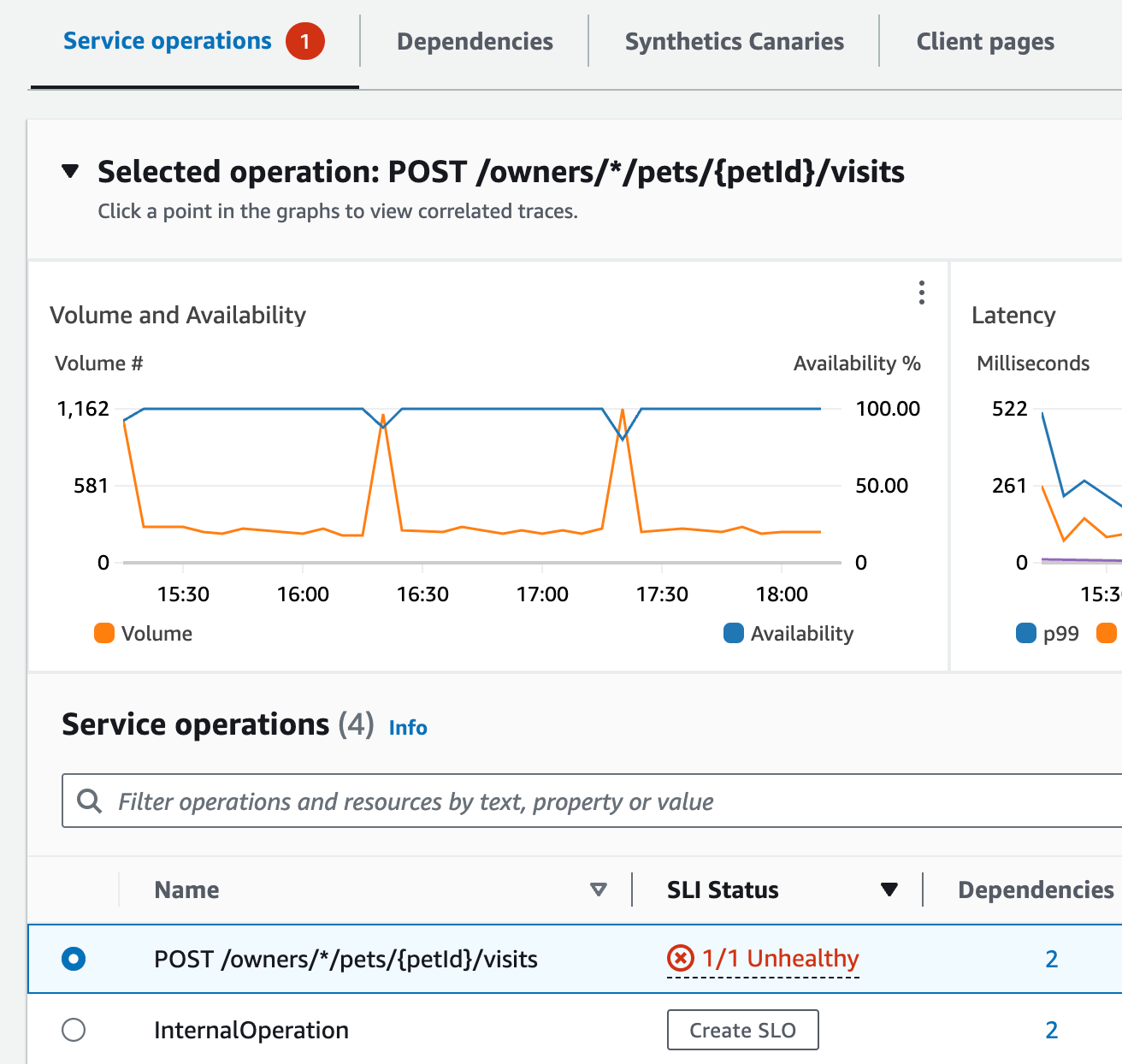
Jane は、サービスの可用性の一時的低下を詳しく調べるために、グラフ内の可用性データポイントの 1 つを選択しました。ドロワーが開き、選択したデータポイントと相関関係がある X-Ray トレースが表示されました。彼女は、障害を含むトレースが複数あることに気付きました。

Jane が障害ステータスと相関関係があるトレースの 1 つを選択すると、選択したトレースの X-Ray トレース詳細ページが開きました。Jane は、[セグメントのタイムライン] セクションまでスクロールし、DynamoDB テーブルへの呼び出しがエラーを返していることがわかるまで呼び出しパスをたどりました。DynamoDB セグメントを選択し、右側のドロワーの [例外] タブに移動しました。

Jane は、DynamoDB リソースの設定に誤りがあるため、顧客のリクエストが急増するとエラーが発生することに気付きました。DynamoDB テーブルのプロビジョニングされたスループットのレベルが定期的に超過していたため、サービスの可用性に問題が生じ、SLI に異常が発生していたのです。この情報に基づいて、彼女のチームはプロビジョニングされたスループットをより高いレベルに設定し、アプリケーションの高可用性を確保できるようになりました。
