論理レプリケーションを使用して Aurora PostgreSQL のメジャーバージョンアップグレードを実行する
論理レプリケーションと Aurora 高速クローニングを使用すると、変更するデータを新しいメジャーバージョンデータベースに徐々に移行しながら、Aurora PostgreSQL データベースの現行バージョンを使用するメジャーバージョンアップグレードを実行できます。このダウンタイムの少ないアップグレードプロセスは、ブルー/グリーンアップグレードと呼ばれます。データベースの現在のバージョンは「ブルー」環境、新しいデータベースバージョンは「グリーン」環境と呼ばれます。
Aurora 高速クローニングでは、ソースデータベースのスナップショットを取得して既存のデータをすべてロードします。高速クローニングでは、Aurora ストレージレイヤー上に構築された Copy-on-Write を使用します。これにより、データベースのクローンを短時間で作成できます。この方法は、大規模なデータベースにアップグレードする場合に非常に効果的です。
PostgreSQL の論理レプリケーションでは、新しいバージョンの PostgreSQL に移行するまで、最初のインスタンスから同時実行される新しいインスタンスへのデータ変更が追跡され、転送されます。論理的なレプリケーションは、発行およびサブスクライブモデルを使用します。Aurora PostgreSQL の論理レプリケーションの詳細については、「Amazon Aurora PostgreSQL でのレプリケーション」を参照してください。
ヒント
マネージド Amazon RDS ブルー/グリーンデプロイ機能を使用することで、メジャーバージョンのアップグレードに必要なダウンタイムを最小限に抑えることができます。詳細については、「データベース更新のために Amazon Aurora ブルー/グリーンデプロイを使用する」を参照してください。
要件
このダウンタイムの少ないアップグレードプロセスを実行するには、次の要件を満たす必要があります。
-
rds_superuser 権限が付与されている必要があります。
-
アップグレードする Aurora PostgreSQL DB クラスターは、論理レプリケーションを使用してメジャーバージョンアップグレードを実行できるサポートバージョンを実行している必要があります。マイナーバージョンの更新とパッチを DB クラスターに適用してください。この方法で使用される
aurora_volume_logical_start_lsn関数は、以下のバージョンの Aurora PostgreSQL でサポートされています。バージョン 15 の 15.2 以降
バージョン 14 の中の 14.3 以降
バージョン 13 の 13.6 以降
バージョン 12 の 12.10 以降
11.15 以上の 11 バージョン
10.20 以上の 10 バージョン
aurora_volume_logical_start_lsn関数の詳細については、「aurora_volume_logical_start_lsn」を参照してください。 -
すべてのテーブルにプライマリキーがあるか、PostgreSQL の IDENTITY 列
が含まれている必要があります。 -
新旧両方の 2 つの Aurora PostgreSQL DB クラスター間でインバウンドおよびアウトバウンドのアクセスを許可するように VPC のセキュリティグループを設定します。特定の Classless Inter-Domain Routing (CIDR) 範囲、または VPC あるいはピア VPC (VPC ピアリング接続が必要) の別のセキュリティグループにアクセス権を付与できます。
注記
実行中の論理レプリケーションシナリオの設定と管理に必要な権限の詳細については、「PostgreSQL core documentation
制約事項
Aurora PostgreSQL DB クラスターでダウンタイムの少ないアップグレードを実行して新しいメジャーバージョンにアップグレードする場合、ネイティブの PostgreSQL 論理レプリケーション機能を使用します。機能と制限は PostgreSQL 論理的レプリケーションと同じです。詳細については、「PostgreSQL 論理的レプリケーション
-
データ定義言語 (DDL) コマンドはレプリケートされません。
-
レプリケーションは、ライブデータベースのスキーマの変更をサポートしていません。スキーマは、クローニング処理中に元の形式で再作成されます。クローニング後にスキーマを変更しても、アップグレードを完了する前は、アップグレードされたインスタンスに反映されません。
-
ラージオブジェクトはレプリケートされませんが、通常のテーブルにデータを保存できます。
-
レプリケーションは、パーティションテーブルなどのテーブルでのみサポートされます。ビュー、マテリアライズドビュー、外部テーブルなどの他の種類のリレーションへのレプリケーションは、サポートされていません。
-
シーケンスデータはレプリケートされないため、フェイルオーバー後に手動で更新する必要があります。
注記
このアップグレードでは、自動スクリプトはサポートされていません。すべての手順は手動で実行する必要があります。
パラメータ値の設定と確認
アップグレード前に、Aurora PostgreSQL DB クラスターのライターインスタンスをパブリケーションサーバーとして機能するように設定します。インスタンスは、次の設定のカスタム DB クラスターパラメータグループを使用する必要があります。
-
rds.logical_replication– このパラメータは 1 に設定します。rds.logical_replicationパラメータは、スタンドアロンの PostgreSQL サーバーのwal_levelパラメータや、ログ先行書き込みファイル管理を制御するその他のパラメータと同じ目的を果たします。 -
max_replication_slots– このパラメータの値を、作成する予定のサブスクリプションの総数に設定します。AWS DMS を使用している場合、このパラメータを、この DB クラスターからの変更データキャプチャに使用する予定の AWS DMS タスクの数に設定します。 -
max_wal_senders— 同時接続数に加えて、いくつかの追加接続数を設定して、管理タスクや新しいセッションに使用できるようにします。AWS DMS を使用する場合、max_wal_senders の数は、同時セッション数と、任意の時点で動作している可能性のある AWS DMS に タスクの数の合計に等しい必要があります。 -
max_logical_replication_workers— 予想される論理レプリケーションワーカーとテーブル同期ワーカーの数に設定します。通常、レプリケーションワーカーの数は max_wal_senders に使用するのと同じ値に設定すると、安全です。ワーカーは、サーバーに割り当てられたバックグラウンドプロセス (max_worker_processes) のプールから取得されます。 -
max_worker_processes— サーバーのバックグラウンドプロセス数に設定します。この数は、レプリケーション、自動バキュームプロセス、および同時に行われる可能性があるその他のメンテナンスプロセスにワーカーを割り当てるのに十分な大きさである必要があります。
Aurora PostgreSQL の新しいバージョンにアップグレードする場合、以前のバージョンのパラメータグループで変更したパラメータを複製する必要があります。このようなパラメータは、アップグレードされたバージョンに適用されます。pg_settings テーブルをクエリしてパラメータ設定のリストを取得し、新しい Aurora PostgreSQL DB クラスターで再作成できます。
例えば、レプリケーションパラメータの設定を取得するには、次のクエリを実行します。
SELECT name, setting FROM pg_settings WHERE name in ('rds.logical_replication','max_replication_slots','max_wal_senders','max_logical_replication_workers','max_worker_processes');
Aurora PostgreSQL を新しいメジャーバージョンにアップグレードする
パブリッシャーを準備するには (ブルー)
-
以下の例では、ソースライターインスタンス (ブルー) は、PostgreSQL バージョン 11.15 が実行中の Aurora PostgreSQL DB クラスターです。これは、レプリケーションシナリオのパブリケーションノードです。このデモンストレーションでは、一連の値を保持しているサンプルテーブルをソースライターインスタンスがホストします。
CREATE TABLEmy_table(a int PRIMARY KEY); INSERT INTOmy_tableVALUES (generate_series(1,100)); -
ソースインスタンス上にパブリケーションを作成するには、psql (PostgreSQL の CLI) または任意のクライアントを使用してインスタンスのライターノードに接続します。各データベースに次のコマンドを入力します。
CREATE PUBLICATIONpublication_nameFOR ALL TABLES;publication_name には、パブリケーションの名前を指定します。
-
また、インスタンス上にレプリケーションスロットも作成する必要があります。次のコマンドを実行すると、レプリケーションスロットが作成され、
pgoutput論理デコーディングプラグインがロードされます。プラグインがロードされると、先行書き込みロギング (WAL) から読み込まれたコンテンツが論理レプリケーションプロトコルに変更され、パブリケーション仕様に従ってデータがフィルタリングされます。 SELECT pg_create_logical_replication_slot('replication_slot_name','pgoutput');
パブリッシャーのクローンを作成するには
-
Amazon RDS コンソールを使用して、ソースインスタンスのクローンを作成します。Amazon RDS コンソールでインスタンス名をハイライトし、[Actions] (アクション) メニューで [Create clone] (クローンの作成) を選択します。
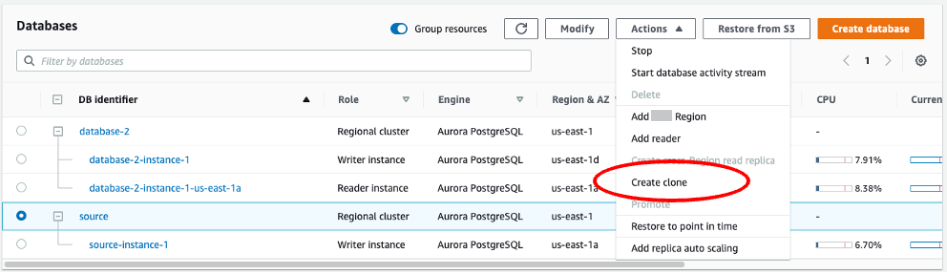
-
インスタンスの一意の名前を指定します。設定のほとんどはソースインスタンスのデフォルトです。新しいインスタンスに必要な変更を加えたら、[Create clone] (クローンの作成) を選択します。

-
ターゲットインスタンスの起動中、ライターノードの [Status] (ステータス) 列には、[Creating] (作成中) と表示されます。インスタンスが使用可能になると、ステータスは [Available] (使用可能) に変わります。
クローンをアップグレード用に準備するには
-
クローンはデプロイモデルの「グリーン」インスタンスです。このクローンが、レプリケーションサブスクリプションノードのホストになります。ノードが使用可能になったら、psql に接続し、新しいライターノードにクエリを実行してログシーケンス番号 (LSN) を取得します。LSN は WAL ストリーム内のレコードの先頭を識別します。
SELECT aurora_volume_logical_start_lsn(); -
クエリからの応答には、LSN 番号が含まれています。この番号はプロセスの後半で必要となるため、書き留めておいてください。
postgres=>SELECT aurora_volume_logical_start_lsn();aurora_volume_logical_start_lsn --------------- 0/402E2F0 (1 row) -
クローンをアップグレードする前に、クローンのレプリケーションスロットを削除してください。
SELECT pg_drop_replication_slot('replication_slot_name');
クラスターを新しいメジャーバージョンにアップグレードするには
-
プロバイダーノードのクローンを作成した後、Amazon RDS コンソールを使用して、サブスクリプションノードのメジャーバージョンアップグレードを開始します。RDS コンソールでインスタンス名をハイライトし、[Modify] (変更) ボタンを選択します。更新されたバージョンと更新されたパラメータグループを選択し、すぐに設定を適用してターゲットインスタンスをアップグレードします。
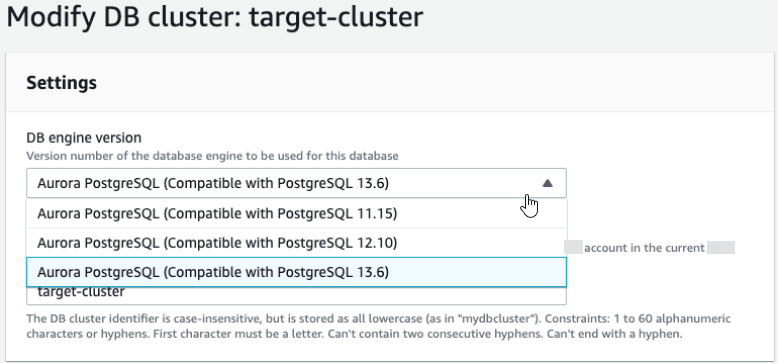
-
CLI を使用してアップグレードを実行することもできます。
aws rds modify-db-cluster —db-cluster-identifier $TARGET_Aurora_ID —engine-version 13.6 —allow-major-version-upgrade —apply-immediately
サブスクライバーを準備するには (グリーン)
-
アップグレード後にクローンが使用可能になったら、psql に接続して、サブスクリプションを定義します。これを行うには、
CREATE SUBSCRIPTIONコマンドで次のオプションを指定する必要があります。-
subscription_name– サブスクリプションの名前。 -
admin_user_name— rds_superuser 権限を持つ管理ユーザーの名前。 -
admin_user_password– 管理ユーザーに関連付けられているパスワード。 -
source_instance_URL— パブリケーションサーバーインスタンスの URL。 -
database— サブスクリプションサーバーが接続するデータベース。 -
publication_name— パブリケーションサーバーの名前。 -
replication_slot_name– レプリケーションスロットの名前。
CREATE SUBSCRIPTIONsubscription_nameCONNECTION'postgres://admin_user_name:admin_user_password@source_instance_URL/database'PUBLICATIONpublication_nameWITH (copy_data = false, create_slot = false, enabled = false, connect = true, slot_name ='replication_slot_name'); -
-
サブスクリプションを作成したら、pg_replication_origin
ビューにクエリして、レプリケーションオリジンの識別子である roname 値を取得します。各インスタンスには、 ronameが 1 つあります。SELECT * FROM pg_replication_origin;例:
postgres=>SELECT * FROM pg_replication_origin;roident | roname ---------+---------- 1 | pg_24586 -
パブリケーションノードの以前のクエリで保存した LSN と、サブスクリプションノード [INSTANCE] から返された
ronameをコマンドに入力します。このコマンドは、pg_replication_origin_advance関数を使用してレプリケーションのログシーケンスの開始点を指定します。SELECT pg_replication_origin_advance('roname','log_sequence_number');ronameは、pg_replication_origin ビューによって返される識別子です。log_sequence_numberは、aurora_volume_logical_start_lsn関数の以前のクエリによって返された値です。 -
次に、
ALTER SUBSCRIPTION... ENABLE句を使用して論理レプリケーションをオンにします。ALTER SUBSCRIPTIONsubscription_nameENABLE; -
この時点で、レプリケーションが機能していることを確認できます。パブリケーションインスタンスに値を追加して、その値がサブスクリプションノードにレプリケートされることを確認します。
次に、次のコマンドを使用して、パブリケーションノードのレプリケーションラグをモニタリングします。
SELECT now() AS CURRENT_TIME, slot_name, active, active_pid, pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), confirmed_flush_lsn)) AS diff_size, pg_wal_lsn_diff(pg_current_wal_lsn(), confirmed_flush_lsn) AS diff_bytes FROM pg_replication_slots WHERE slot_type = 'logical';例:
postgres=>SELECT now() AS CURRENT_TIME, slot_name, active, active_pid, pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), confirmed_flush_lsn)) AS diff_size, pg_wal_lsn_diff(pg_current_wal_lsn(), confirmed_flush_lsn) AS diff_bytes FROM pg_replication_slots WHERE slot_type = 'logical';current_time | slot_name | active | active_pid | diff_size | diff_bytes -------------------------------+-----------------------+--------+------------+-----------+------------ 2022-04-13 15:11:00.243401+00 | replication_slot_name | t | 21854 | 136 bytes | 136 (1 row)diff_sizeおよびdiff_bytes値を使用して、レプリケーションラグをモニタリングできます。これらの値が 0 に達すると、レプリカがソース DB インスタンスに追いついています。
アップグレード後のタスクの実行
アップグレードが完了すると、コンソールのダッシュボードの [Status] (ステータス) 列にインスタンスのステータスが [Available] (使用可能) と表示されます。新しいインスタンスで、次の操作を実行することをお勧めします。
-
ライターノードを指すようにアプリケーションをリダイレクトします。
-
リーダーノードを追加してケースロードを管理し、ライターノードで問題が発生した場合に備えて高可用性を持たせます。
-
Aurora PostgreSQL DB クラスターでは、オペレーティングシステムの更新が必要になる場合があります。これらのアップデートには glibc ライブラリの新しいバージョンが含まれることがあります。このような更新の際は、「Aurora PostgreSQL でサポートされる照合」で説明されているガイドラインに従うことをお勧めします。
-
新しいインスタンスのユーザー権限を更新して、アクセスを確実にします。
新しいインスタンスでアプリケーションとデータをテストしたら、最初のインスタンスを削除する前に最終バックアップを作成することをお勧めします。Aurora ホストにおける論理レプリケーションの使用の詳細については、「Aurora PostgreSQL DB クラスターの論理レプリケーションの設定」を参照してください。
