DynamoDB テーブルで適切なサイズのプロビジョニングを行うために、プロビジョンドキャパシティを評価する
このセクションでは、DynamoDB テーブルのプロビジョニングが適切なサイズであるかどうかを評価する方法の概要を説明します。ワークロードの変化に応じて、運用手順を適切に変更する必要があります。特に DynamoDB テーブルがプロビジョニングモードで設定されていて、テーブルを過剰にプロビジョニングしたり、プロビジョニング不足になったりするリスクがある場合はそうです。
以下に説明する手順では、本稼働アプリケーションをサポートしている DynamoDB テーブルから取得する必要がある統計情報が必要です。アプリケーションの動作を理解するには、アプリケーションからのデータの季節性を把握するのに十分な期間を定義する必要があります。たとえば、アプリケーションに週単位のパターンが見られる場合は、3 週間の期間を使用することで、アプリケーションのスループットニーズを分析するための十分な余裕が得られます。
何から始めればよいかわからない場合は、以下の計算に少なくとも 1 か月分のデータ使用量を使用してください。
容量を評価する際、DynamoDB テーブルでは、読み込みキャパシティユニット (RCU) と書き込みキャパシティユニット (WCU) を個別に設定できます。テーブルにグローバルセカンダリインデックス (GSI) が設定されている場合は、そのテーブルが消費するスループットを指定する必要があります。これもベーステーブルの RCU や WCU から独立しています。
注記
ローカルセカンダリインデックス (LSI) はベーステーブルの容量を消費します。
DynamoDB テーブルの消費メトリクスを取得する方法
テーブルと GSI の容量を評価するには、次の CloudWatch メトリクスをモニタリングし、適切なディメンションを選択してテーブルまたは GSI 情報を取得します。
| 読み込みキャパシティユニット | 書き込みキャパシティユニット |
|---|---|
|
|
|
|
|
|
|
|
|
この操作は、AWS CLI または AWS Management Console で実行できます。
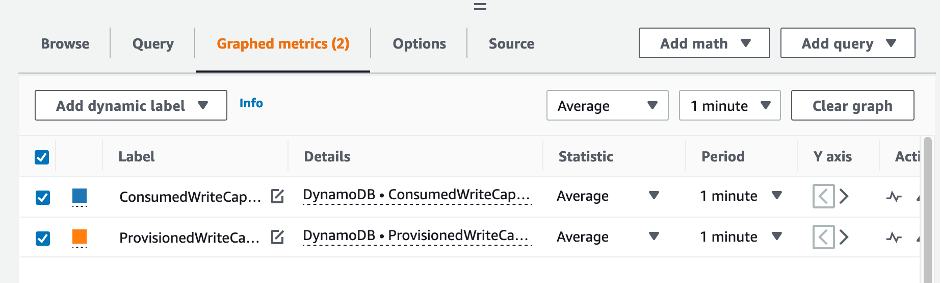
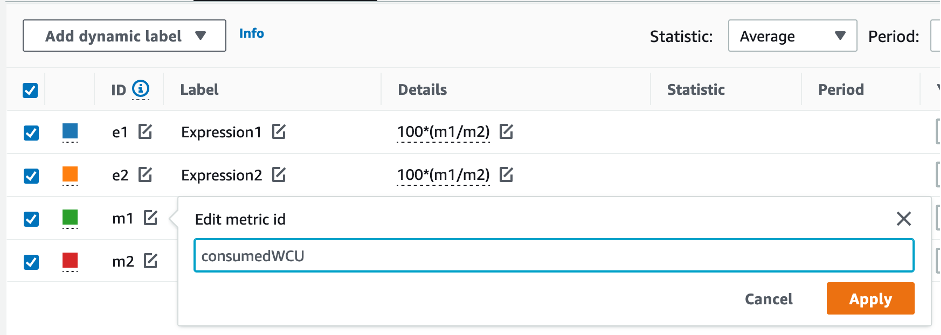
![CloudWatch コンソール。グラフ化されたメトリクスに対して [パーセンテージ] 関数を選択します。](images/CostOptimization/RightSizedProvisioning2.png)
![CloudWatch コンソール。グラフ化されたメトリクスに対して [パーセンテージ] 関数を 2 回目に選択します。](images/CostOptimization/RightSizedProvisioning3.png)

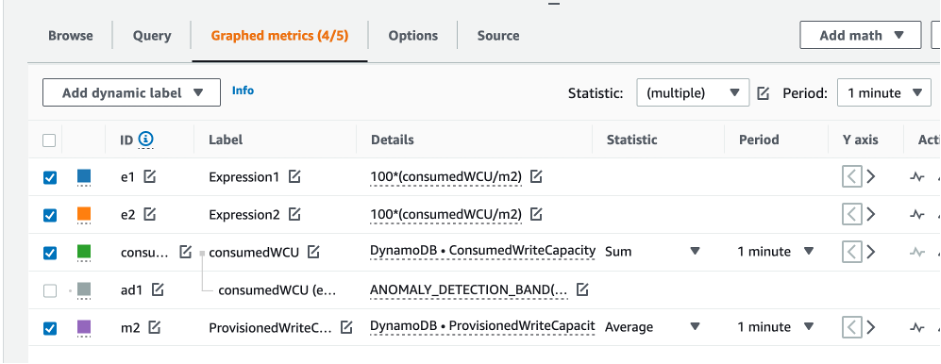
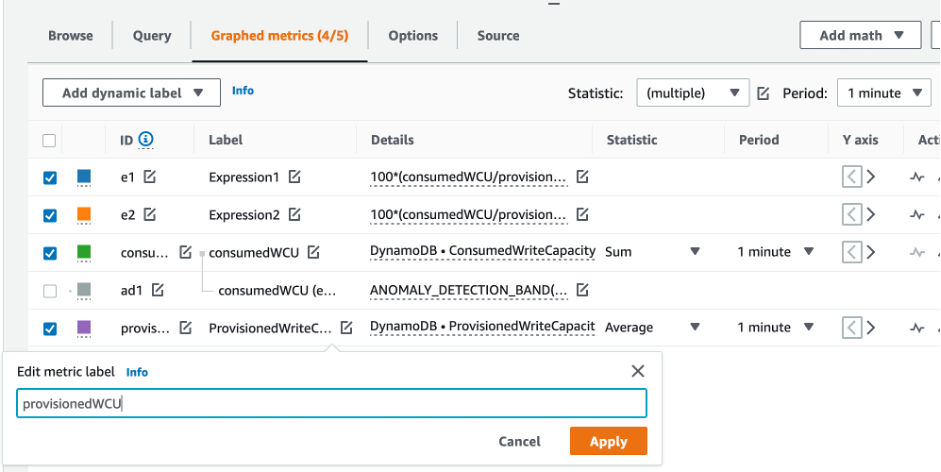
![CloudWatch コンソール。グラフ化されたメトリクスのドロップダウンリストで統計として [合計] を選択します。](images/CostOptimization/RightSizedProvisioning6.png)





プロビジョニング不足の DynamoDB テーブルを識別する方法
ほとんどのワークロードでは、テーブルがプロビジョンドキャパシティの 80% 以上を絶えず消費している場合、そのテーブルはプロビジョニング不足と見なされます。
バーストキャパシティは DynamoDB の機能の 1 つで、お客様が当初のプロビジョニング量よりも多くの (表で定義されている 1 秒あたりのプロビジョニングスループットを超える) RCU/WCU を一時的に消費できるようにするものです。バーストキャパシティは、特別なイベントや使用量の急増によるトラフィックの急激な増加を吸収するために作成されました。このバーストキャパシティはいつまでも続くわけではありません。未使用の RCU と WCU がなくなると同時に、プロビジョニングされた容量よりも多くの容量を消費しようとすると、スロットリング状態になります。アプリケーショントラフィックの使用率が 80% に近づくと、スロットリングのリスクが大幅に高まります。
80% 使用率ルールは、データの季節性やトラフィックの増加によって異なります。次のシナリオを考えてみます。
-
過去 12 か月間、トラフィックの使用率が約 90% で安定していれば、テーブルのキャパシティは適切であると言えます
-
アプリケーショントラフィックが 3 か月以内に毎月 8% の割合で増加した場合、100% に到達します
-
アプリケーショントラフィックが 4 か月余りで 5% の割合で増加している場合でも、100% に到達します
上記のクエリの結果から、使用率の全体像がわかります。これらを参考にして、必要に応じてテーブルのキャパシティを増やす方法を選択するのに役立つ他のメトリクス (月間または毎週の増加率など) をさらに評価してください。運用チームと協力して、ワークロードとテーブルに適したパーセンテージを定義してください。
データを毎日または毎週分析すると、データが歪んでしまう特別なシナリオがあります。例えば、季節性のアプリケーションで、勤務時間中に使用量が急増する (ただし、勤務時間外はほぼゼロになる) 場合は、自動スケーリングをスケジュールして時間帯 (および曜日) を指定してプロビジョンドキャパシティを増やすと効果的です。繁忙期に対応できるように容量を増やすかわりに、季節性がそれほどない場合には、DynamoDB テーブルの自動スケーリング設定を利用することもできます。
注記
ベーステーブルに DynamoDB Auto Scaling 設定を作成するときは、そのテーブルに関連付けられている GSI にも別の設定を含めることを忘れないでください。
過剰にプロビジョニングされた DynamoDB テーブルを識別する方法
上記のスクリプトから取得したクエリ結果から、初期分析を実行するために必要なデータポイントが得られます。データセットの使用率が複数の間隔で 20% 未満の値を示す場合は、テーブルが過剰にプロビジョニングされている可能性があります。WCU と RCU の数を減らす必要があるかどうかをさらに明確にするには、その間隔で他の測定値を見直す必要があります。
テーブルに使用頻度の低い間隔が複数ある場合は、自動スケーリングをスケジュールするか、使用率に基づくテーブルのデフォルトの自動スケーリングポリシーを設定することで、自動スケーリングポリシーの使用から大きなメリットが得られます。
使用率が低いのにスロットリング率 (間隔内の Max(ThrottleEvents)/Min(ThrottleEvents)) が高いワークロードがある場合、この現象は、ある日 (または時間) にトラフィックが大幅に増加するが一般的にトラフィックは常に少ない、非常にスパイクの多いワークロードがある場合に発生する可能性があります。このようなシナリオでは、スケジュールされた自動スケーリングを使用すると有益な場合があります。
