DynamoDB のグローバルセカンダリインデックスの使用
アプリケーションによっては、さまざまな属性をクエリ基準に使用して、いろいろな種類のクエリを実行する必要があります。このような要件に対応するために、1 つまたは複数のグローバルセカンダリインデックスを作成して、Amazon DynamoDB でこれらのインデックスに対して Query リクエストを発行できます。
トピック
シナリオ: グローバルセカンダリインデックスの使用
たとえば、GameScores という名前のテーブルがあり、モバイルゲームアプリケーションのユーザーとスコアを記録しているとします。GameScores の各項目は、パーティションキー (UserId) およびソートキー (GameTitle) で特定されます。次の図は、テーブル内の項目の構成を示しています。一部表示されていない属性もあります。
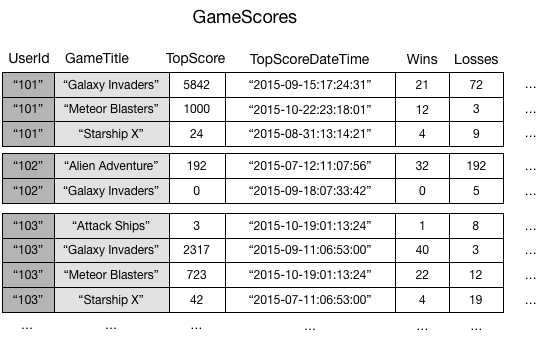
ここで、各ゲームの最高スコアを表示する順位表アプリケーションを作成すると仮定します。キー属性 (UserId と GameTitle) を指定したクエリは非常に効率的です。ただし、アプリケーションが GameScores だけに基づいて GameTitle からデータを取り出す必要がある場合、Scan オペレーションを使用する必要があります。テーブルに追加される項目が増えるにつれ、すべてのデータのスキャンは低速で非効率的になります。このため、次のような質問に答えることが難しくなります。
-
ゲーム Meteor Blasters で記録された最高スコアはいくつですか?
-
Galaxy Invaders で最高スコアを獲得したユーザーは誰ですか?
-
勝敗の最も高い比率は何ですか?
グローバルセカンダリインデックスを作成して、非キー属性に対するクエリの速度を上げることができます。グローバルセカンダリインデックスには、ベーステーブルからの属性の一部が格納されますが、それらはテーブルのプライマリキーとは異なるプライマリキーによって構成されます。インデックスキーは、テーブルからのキー属性を持つ必要がありません。また、テーブルと同じキースキーマを使用する必要もありません。
例えば、パーティションキーとして GameTitle、ソートキーとして TopScore を使用して、GameTitleIndex という名前のグローバルセカンダリインデックスを作成できます。ベーステーブルのプライマリキー属性は必ずインデックスに射影されるので、UserId 属性も存在します。次の図は、GameTitleIndex インデックスを示しています。
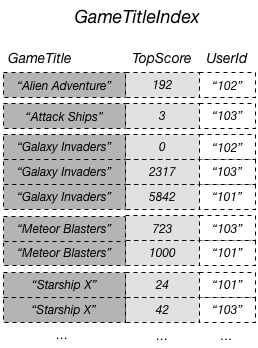
これで、GameTitleIndex に対してクエリを実行し、Meteor Blasters のスコアを簡単に入手できるようになります。結果は、ソートキーの値 TopScore 別に並べられます。ScanIndexForward パラメータを false に設定した場合、結果は降順で返されます。つまり、最高スコアが最初に返されます。
すべてのグローバルセカンダリインデックスには、パーティションキーが必要で、オプションのソートキーを指定できます。インデックスキースキーマは、テーブルスキーマとは異なるものにすることができます。シンプルなプライマリキー (パーティションキー) を持つテーブルを作成し、複合プライマリキー (パーティションキーおよびソートキー) を使用してグローバルセカンダリインデックスを作成できます。またはその逆もあります。インデックスキー属性は、はベーステーブルからの任意の最上位 String、Number、または Binary 属性で構成できます。その他のスカラー型、ドキュメント型、およびセット型は許可されません。
必要な場合、他のベーステーブル属性をインデックスに射影できます。インデックスのクエリを行うと、DynamoDB ではこれらの射影された属性を効率的に取り出すことができます。ただし、グローバルセカンダリインデックス のクエリでは、ベーステーブルから属性をフェッチできません。たとえば、上記の図に示すように、GameTitleIndex にクエリを実行した場合、クエリは TopScore 以外の非キー属性にアクセスすることはできません (キー属性 GameTitle と UserId は自動的に射影されます)。
DynamoDB テーブルでは、各キー値は一意である必要があります。ただし、グローバルセカンダリインデックスのキー値は一意である必要はありません。たとえば、Comet Quest という名前のゲームが特に難しく、多くの新しいユーザーが試しても、ゼロを上回るスコアを獲得することができないとします。以下にこれを表すいくつかのデータを示します。
| UserId | GameTitle | TopScore |
|---|---|---|
| 123 | Comet Quest | 0 |
| 201 | Comet Quest | 0 |
| 301 | Comet Quest | 0 |
このデータを GameScores テーブルに追加すると、DynamoDB はそのデータを GameTitleIndex に伝達します。GameTitle として Comet Quest を、TopScore として 0 を指定してインデックスに対するクエリを実行すると、次のデータが返されます。
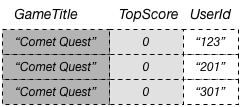
指定したキー値を持つ項目だけがレスポンスに表示されます。その一連のデータ内では、項目は特定の順に並んでいません。
グローバルセカンダリインデックスは、キー属性が実際に存在するデータ項目のみを追跡します。たとえば、別の新しい項目を GameScores テーブルに追加し、必須のプライマリキー属性だけを指定したとします。
| UserId | GameTitle |
|---|---|
| 400 | Comet Quest |
TopScore 属性を指定していないので、DynamoDB は、この項目を GameTitleIndex に伝達しません。このため、すべての Comet Quest 項目を対象に、GameScores に対してクエリを実行した場合、次の 4 つの項目が返されます。
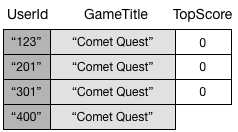
GameTitleIndex に対して同様のクエリを実行すると、4 つではなく 3 つの項目が返されます。これは、TopScore が存在しない項目はインデックスに反映されないためです。
属性の射影
射影とは、テーブルからセカンダリインデックスにコピーされる属性のセットです。テーブルのパーティションキーとソートキーは常にインデックスに射影されます。アプリケーションのクエリ要件をサポートするために、他の属性を射影できます。インデックスをクエリすると、Amazon DynamoDB は、その属性が自身のテーブル内にあるかのように、プロジェクション内の任意の属性にアクセスできます。
セカンダリインデックスを作成するときは、インデックスに射影される属性を指定する必要があります。DynamoDB には、そのために次の 3 つのオプションが用意されています。
-
KEYS_ONLY – インデックス内の各項目は、テーブルパーティションキーとソートキーの値、およびインデックスキーの値のみで構成されます。
KEYS_ONLYオプションを指定すると、セカンダリインデックスが最小になります。 -
INCLUDE –
KEYS_ONLYの属性に加えて、セカンダリインデックスにその他の非キー属性が含まれるように指定できます。 -
ALL – セカンダリインデックスには、ソーステーブルのすべての属性が含まれます。すべてのテーブルデータがインデックスに複製されるため、
ALLの射影にすると、セカンダリインデックスが最大になります。
前の図では、GameTitleIndex には 1 つの射影された属性 UserId のみがあります。そのため、アプリケーションはクエリで UserId および GameTitle を使用して各ゲームのトップスコアラーの TopScore を効率的に判断できますが、トップスコアラーの勝敗の最も高い比率は効率的に判断できません。そのためには、基本テーブルで追加のクエリを実行して、各トップスコアラーの勝敗を取得する必要があります。このデータに対するクエリのサポートを効率化する方法として、次の図に示すように、これらの属性をベーステーブルからグローバルセカンダリインデックスに射影する方法があります。
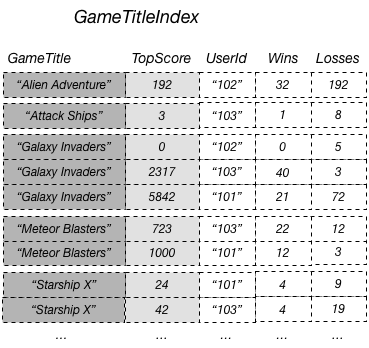
非キー属性 Wins と Losses がインデックスに射影されるので、アプリケーションは、任意のゲーム、またはゲームとユーザー ID の任意の組み合わせに対して、勝敗の比率を特定できます。
グローバルセカンダリインデックスに射影する属性を選択する場合には、プロビジョニングされるスループットコストとストレージコストのトレードオフを考慮する必要があります。
-
ごく一部の属性だけに最小のレイテンシーでアクセスする必要がある場合は、それらの属性だけをグローバルセカンダリインデックスに射影することを検討してください。インデックスが小さいほど少ないコストで格納でき、書き込みコストも低くなります。
-
アプリケーションが非キー属性に頻繁にアクセスする場合には、それらの属性をグローバルセカンダリインデックスに射影することを検討してください。グローバルセカンダリインデックスのストレージコストの増加は、頻繁にテーブルスキャンを実行するコストの減少で相殺されます。
-
ほとんどの非キー属性に頻繁にアクセスする場合は、それらの属性を (場合によっては、ベーステーブル全体を) グローバルセカンダリインデックスに射影することができます。これにより、最大限の柔軟性が得られます。ただし、ストレージコストは増加するか、倍になります。
-
アプリケーションでテーブルのクエリを頻繁に行う必要がなく、テーブル内のデータに対する書き込みや更新が多数になる場合は、
KEYS_ONLYを射影することを検討してください。グローバルセカンダリインデックスは、最小サイズになりますが、それでもクエリのアクティビティに必要な場合は利用可能です。
グローバルセカンダリインデックスからのデータの読み込み
グローバルセカンダリインデックスから項目を取得するには、Query および Scan オペレーションを使用します。GetItem および BatchGetItem オペレーションは、グローバルセカンダリインデックスでは使用できません。
グローバルセカンダリインデックスのクエリ
Query オペレーションを使用して、グローバルセカンダリインデックスの 1 つ以上の項目にアクセスすることができます。クエリでは、使用するベーステーブル名とインデックス名、クエリ結果で返される属性、および適用するクエリ条件を指定する必要があります。DynamoDB は、結果を昇順で返すことも降順で返すこともできます。
順位表アプリケーションのゲームデータをリクエストする Query から返される次のデータについて考えます。
{ "TableName": "GameScores", "IndexName": "GameTitleIndex", "KeyConditionExpression": "GameTitle = :v_title", "ExpressionAttributeValues": { ":v_title": {"S": "Meteor Blasters"} }, "ProjectionExpression": "UserId, TopScore", "ScanIndexForward": false }
このクエリでは次のようになっています。
-
DynamoDB は、GameTitle パーティションキーを使用して GameTitleIndex にアクセスし、Meteor Blasters のインデックス項目を特定します。このキーを持つすべてのインデックス項目が、すばやく取り出せるように隣り合わせに格納されます。
-
このゲーム内で、DynamoDB はインデックスを使用して、このゲームのすべてのユーザーの ID と最高スコアにアクセスします。
-
ScanIndexForwardパラメータが false に設定されているので、結果は降順で返されます。
グローバルセカンダリインデックスのスキャン
Scan オペレーションを使用して、グローバルセカンダリインデックスからすべてのデータを取得することができます。リクエストにはベーステーブル名とインデックス名を指定する必要があります。Scan では、DynamoDB はインデックスのすべてのデータを読み込み、それをアプリケーションに返します。また、データの一部のみを返し、残りのデータを破棄するようにリクエストすることもできます。これを行うには、FilterExpression オペレーションの Scan パラメータを使用します。詳細については、「」を参照してくださいScan のフィルタ式
テーブルとグローバルセカンダリインデックス間のデータ同期
DynamoDB では、各グローバルセカンダリインデックスをそのベーステーブルと自動的に同期させています。アプリケーションがテーブルに項目を書き込むか、削除すると、そのテーブルのすべてのグローバルセカンダリインデックスは、結果整合性モデルを使用して、非同期で更新されます。アプリケーションがインデックスに直接書き込むことはありません。ただし、DynamoDB でこれらのインデックスがどのように維持されるかを理解することは重要です。
グローバルセカンダリーインデックスは、基本テーブルから読み込み/書き込みキャパシティーモードを継承します。詳細については、「DynamoDB でキャパシティモードを切り替える際の考慮事項」を参照してください。
グローバルセカンダリインデックスを作成するときは、1 つ以上のインデックスキー属性およびそれらのデータ型を指定します。つまり、ベーステーブルに項目を書き込むとき、それらの属性のデータ型が、インデックスキースキーマのデータ型に一致する必要があります。GameTitleIndex の場合、インデックス内の GameTitle パーティションキーは、String データ型として定義されています。インデックス内の TopScore ソートキーは、Number の型です。GameScores テーブルに項目を追加し、GameTitle または TopScore に対して別のデータ型を指定する場合、データ型の不一致により DynamoDB によって ValidationException が返されます。
テーブルに項目を入力するか、削除すると、そのテーブルのグローバルセカンダリインデックスは、結果整合性のある方法で更新されます。テーブルデータへの変更は、通常は、瞬時にグローバルセカンダリインデックスに伝達されます。ただし、万が一障害が発生した場合は、長い伝達遅延が発生することがあります。このため、アプリケーションでは、グローバルセカンダリインデックスに関するクエリに対して、最新でない結果が返される状況を予期し、それに対応する必要があります。
テーブルに項目を書き込む場合には、グローバルセカンダリインデックスのソートキーに対して属性を指定する必要はありません。GameTitleIndex を例にとると、GameScores テーブルに新しい項目を書き込むために、TopScore 属性に値を指定する必要はありません。このケースでは、DynamoDB はこの特定の項目のインデックスにデータを書き込むことはありません。
多数のグローバルセカンダリインデックスがあるテーブルは、インデックス数が少ないテーブルに比べて書き込みアクティビティに多くのコストを要します。詳細については、「グローバルセカンダリインデックスに対するプロビジョニングされたスループットに関する考慮事項」を参照してください。
グローバルセカンダリインデックスがあるテーブルクラス
グローバルセカンダリインデックスは、常にベーステーブルと同じテーブルクラスを使用します。テーブルに新しいグローバルセカンダリインデックスが追加されるたびに、新しいインデックスはベーステーブルと同じテーブルクラスを使用します。テーブルのテーブルクラスが更新されると、関連するすべてのグローバルセカンダリインデックスも更新されます。
グローバルセカンダリインデックスに対するプロビジョニングされたスループットに関する考慮事項
プロビジョニングモードのテーブルでグローバルセカンダリインデックスを作成するときには、そのインデックスに対して予想されるワークロードに応じた読み込み/書き込みキャパシティーユニットを指定する必要があります。グローバルセカンダリインデックスのプロビジョニングされたスループット設定は、そのベーステーブルの設定とは独立しています。グローバルセカンダリインデックスに対する Query オペレーションでは、ベーステーブルではなく、インデックスから読み込みキャパシティーユニットを使用します。テーブルで項目を入力、更新または削除すると、そのテーブルのグローバルセカンダリインデックスも更新されます。これらのインデックス更新は、ベーステーブルからではなく、インデックスから書き込みキャパシティーユニットを消費します。
例えば、グローバルセカンダリインデックスに対して Query を実行し、そのプロビジョニングされた読み込みキャパシティーを超えた場合、リクエストは調整されます。多量の書き込みアクティビティをテーブルに対して実行するときに、そのテーブルのグローバルセカンダリインデックスに十分な書き込み容量がない場合、そのテーブルに対する書き込みアクティビティは調整されます。
重要
スロットリングを避けるため、グローバルセカンダリインデックスのプロビジョニングされた書き込みキャパシティーは、ベーステーブルの書き込みキャパシティーと同じかそれより大きい必要があります。これは、新しい更新ではベーステーブルとグローバルセカンダリインデックスの両方に書き込むためです。
グローバルセカンダリインデックスのプロビジョニングされたスループット設定を表示するには、DescribeTable オペレーションを使用します。テーブルのすべてのグローバルセカンダリインデックスに関する詳細情報が返されます。
読み込みキャパシティユニット
グローバルセカンダリインデックスでは、結果整合性のある読み込みをサポートしており、各読み込みで、読み込みキャパシティーユニットの半分を消費します。つまり、1 回のグローバルセカンダリインデックスのクエリでは、1 読み込みキャパシティーユニットあたり最大 2 × 4 KB = 8 KB を取り出すことができます。
グローバルセカンダリインデックスのクエリの場合、DynamoDB はプロビジョニングされた読み込みアクティビティをテーブルに対するクエリと同じ方法で計算します。唯一の違いは、ベーステーブル内の項目のサイズではなくインデックスエントリのサイズに基づいて計算が行われることです。読み込みキャパシティーユニットの数は、返されたすべての項目について射影されたすべての属性のサイズの合計です。結果は、次の 4 KB 境界まで切り上げられます。DynamoDB がプロビジョニングされたスループットの利用率を計算する方法の詳細については、「DynamoDB プロビジョンドキャパシティモード」を参照してください。
Query オペレーションによって返される結果の最大サイズは 1 MB です。これには、返されるすべての項目にわたる、すべての属性の名前と値のサイズが含まれます。
例えば、各項目に 2,000 バイトのデータが格納されているグローバルセカンダリインデックスがあるとします。このインデックスに対して Query を実行したら、クエリの KeyConditionExpression が 8 項目に一致したとします。一致する項目の合計サイズは、2,000 バイト × 8 項目 = 16,000 バイトです。これは、最も近い 4 KB 境界に切り上げられます。グローバルセカンダリインデックスのクエリは結果整合性なので、合計コストは、0.5 × (16 KB / 4 KB)、つまり、2 読み込みキャパシティーユニットです。
書き込みキャパシティユニット
テーブルの項目が追加、更新、または削除されたときに、グローバルセカンダリインデックスがこの影響を受ける場合、グローバルセカンダリインデックスは、そのオペレーションに対してプロビジョニングされた書き込みキャパシティーユニットを使用します。書き込み用にプロビジョニングされたスループットの合計コストは、ベーステーブルに対する書き込みと、グローバルセカンダリインデックスの更新で消費された書き込みキャパシティーユニットの合計になります。テーブルへの書き込みには、グローバルセカンダリインデックスの更新は必要ないので、インデックスから使用される書き込み容量はありません。
テーブルへの書き込みに成功するように、テーブルとそのすべてのグローバルセカンダリインデックスに対するプロビジョニングされたスループット設定は、書き込みに対応できるだけの十分な書き込みキャパシティーを備えている必要があります。十分でない場合、書き込みが調整されます。
グローバルセカンダリインデックスに項目を書き込むコストは、いくつかの要因に左右されます。
-
インデックス付き属性が定義されたテーブルに新しい項目を書き込む場合、または既存の項目を更新して未定義のインデックス付き属性を定義する場合には、インデックスへの項目の挿入に 1 回の書き込みオペレーションが必要です。
-
テーブルに対する更新によってインデックス付きキー属性の値が(A から B に)変更された場合には、インデックスから既存の項目を削除し、インデックスに新しい項目を挿入するために、2 回の書き込みが必要です。
-
インデックス内に既存の項目があって、テーブルに対する書き込みによってインデックス付き属性が削除された場合は、インデックスから古い項目の射影を削除するために、1 回の書き込みが必要です。
-
項目の更新の前後にインデックス内に項目が存在しない場合は、インデックスで追加の書き込みコストは発生しません。
-
テーブルに対する更新によってインデックスキースキーマの射影された属性の値のみが変更され、インデックス付きキー属性の値は変更されない場合は、インデックスに射影された属性の値を更新するために、1 回の書き込みが必要です。
これらすべての要因は、インデックス内の各項目のサイズが 1 KB 以下であるという前提で書き込みキャパシティーユニット数を算出します。インデックスエントリがそれよりも大きい場合は、書き込みキャパシティーユニットを追加する必要があります。クエリが返す必要がある属性を特定し、それらの属性だけをインデックスに射影することで、書き込みコストは最小になります。
グローバルセカンダリインデックスのストレージに関する考慮事項
アプリケーションがテーブルに項目を書き込むと、DynamoDB では、正しい属性のサブセットが、それらの属性が現れる必要があるグローバルセカンダリインデックスに自動的にコピーされます。AWS アカウントでは、テーブル内の項目のストレージと、そのベーステーブルのグローバルセカンダリインデックスにある属性のストレージに対して課金されます。
インデックス項目が使用するスペースの量は、次の量の合計になります。
-
ベーステーブルのプライマリキー (パーティションキーとソートキー) のサイズのバイト数
-
インデックスキー属性のサイズのバイト数
-
射影された属性(存在する場合)のサイズのバイト数
-
インデックス項目あたり 100 バイトのオーバーヘッド
グローバルセカンダリインデックスのストレージ要件の見積もりは、インデックス内の 1 項目の平均サイズの見積もり値に、ベーステーブル内のグローバルセカンダリインデックスキー属性を持つ項目の数を掛けて算出します。
特定の属性が定義されていない項目がテーブルに含まれていて、その属性がインデックスパーティションキーまたはソートキーとして定義されている場合、DynamoDB はその項目のデータをインデックスに書き込みません。
