DynamoDB のマテリアライズされた集計クエリでグローバルセカンダリインデックスを使用する
急速に変化するデータ上で、ほぼリアルタイムの集約や主要メトリクスを維持することは、企業が意思決定を迅速に行う上で、ますます価値が高まりつつあります。例えば、音楽ライブラリでは、最も多くダウンロードされた曲をほぼリアルタイムに紹介する場合があります。
次の音楽ライブラリのテーブルレイアウトを考えてみましょう。
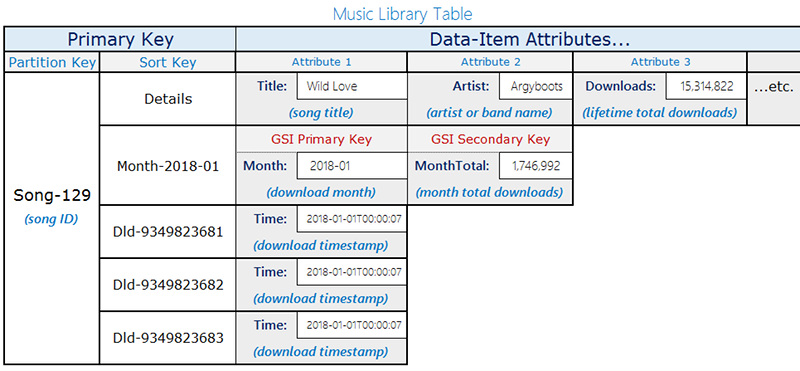
このテーブルの例では、songID をパーティションキーとして使用して曲を保存しています。このテーブルで Amazon DynamoDB Streams を有効にして、Lambda 関数をこのストリームにアタッチすることで、各曲がダウンロードされたときに、Partition-Key=SongID と Sort-Key=DownloadID を含むテーブルにエントリが追加されます。これらの更新が行われると、DynamoDB Streams で Lambda 関数がトリガーされます。この Lambda 関数を使用して、songID ごとにダウンロードを集計してグループ化し、上位レベルの項目 Partition-Key=songID と Sort-Key=Month を更新します。新しい集計値を書き込んだ直後に Lambda 実行が失敗した場合は、再試行して値を複数回集計し、おおよその値を残す可能性があることに注意してください。
1 桁台のミリ秒のレイテンシーでほぼリアルタイムに更新を読み取るには、クエリ条件 Month=2018-01、ScanIndexForward=False、Limit=1 のグローバルセカンダリインデックスを使用します。
ここでは、グローバルセカンダリインデックスがスパースインデックスであり、リアルタイムにデータを取得するために照会する必要のある項目に対してのみ使用できる、もう 1 つのキー最適化を使用します。グローバルセカンダリインデックスは、人気のあった上位 10 曲またはその月にダウンロードされた曲に関する情報を必要とする追加のワークフローに対応できます。
