スパースインデックスの利用
テーブル内の項目について、DynamoDB は項目内にインデックスソートのキーバリューがある場合のみ、対応するインデックスエントリを書き込みます。ソートキーがすべてのテーブル項目に表示されない場合や、インデックスパーティションキーが項目に存在しない場合、インデックスはスパースであると言います。
スパースインデックスは、テーブルの小さなサブセクションに対して行うクエリに役立ちます。例えば、次のキー属性を使用して顧客の注文をすべて格納するテーブルがあるとします。
-
パーティションキー:
CustomerId -
ソートキー:
OrderId
クローズされていない注文を追跡するために、未出荷の注文項目に isOpen というブール属性を挿入することができます。その後、注文が出荷されたら、その属性は削除できます。CustomerId (パーティションキー) と isOpen (ソートキー) でインデックスを作成した場合は、isOpen が定義されている注文のみ、その中に表示されます。多くの注文のうち、少数の注文がクローズされていない場合は、テーブル全体をスキャンするよりも、クローズされていない注文のインデックスをクエリする方が時間もコストもかかりません。
isOpen のようなタイプの属性を使用する代わりに、インデックスに有益なソート順になる値を持つ属性を使用できます。例えば、各注文時の日付に設定された OrderOpenDate 属性を使用して、注文が確定した後でそれを削除することができます。このように、スパースなインデックスをクエリすると、各注文の確定日でソートされた項目が返されます。
DynamoDB のスパースインデックスの例
グローバルセカンダリインデックスは、デフォルトでスパースです。グローバルセカンダリインデックスを作成する際、パーティションキーおよびソートキー (オプション) を指定します。インデックスには、これらの属性を含むベーステーブル内の項目のみ、表示されます。
グローバルセカンダリインデックスをスパースに設計することにより、優れたパフォーマンスを達成しながら、ベーステーブルの書き込みスループットよりも低くプロビジョニングできます。
例えば、ゲームアプリケーションは、各ユーザーのすべてのスコアを追跡することができますが、一般的に、いくつかの高いスコアをクエリするだけで済みます。このシナリオは、次のように効率的に処理されます。
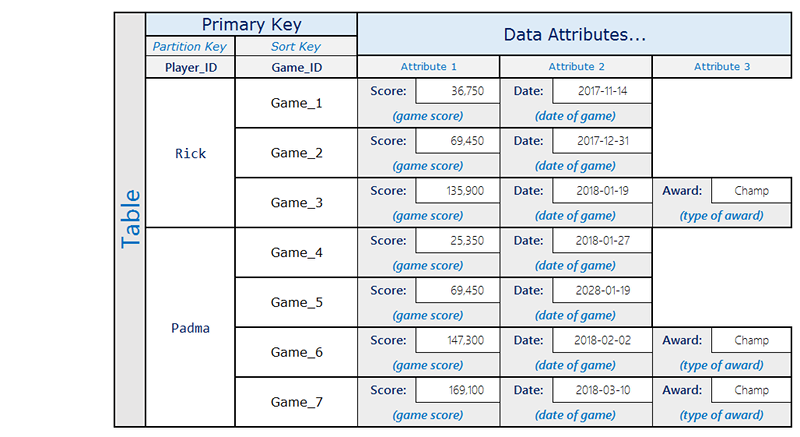
ここで、Rick は 3 つのゲームをプレイし、そのうちの 1 つで Champ ステータスを達成しました。Padma は 4 つのゲームをプレイし、そのうちの 2 つで Champ ステータスを達成しました。Award 属性は、ユーザーが賞を獲得した項目にのみ存在することに注意してください。関連するグローバルセカンダリインデックスは次のようになります。

グローバルセカンダリインデックスには、頻繁にクエリされる上位スコアのみ含まれます。これらのスコアは、ベーステーブルの項目の小さなサブセットです。
