DynamoDB で時系列データを処理するベストプラクティス。
Amazon DynamoDB の一般的な設計原則では、使用するテーブルの数を最小限に抑えることをお勧めします。ほとんどのアプリケーションで、必要なテーブルは 1 つだけです。ただし、時系列データでは、期間あたりアプリケーションごとにテーブルを 1 個使用すると、多くの場合最適に処理できます。
時系列データの設計パターン
大容量のイベントを追跡する一般的な時系列シナリオを考えてみます。書き込みアクセスパターンは、記録されているすべてのイベントが今日の日付であることです。お客様の読み込みアクセスパターンでは、今日のイベントは最も頻繁に、昨日のイベントはそれよりはるかに低い頻度で読み込まれ、それ以前の古いイベントはほとんど読み込まれません。これを処理する 1 つの方法として、現在の日時をプライマリキーに構築できます。
次の設計パターンでは、このようなシナリオを効率的に処理します。
-
必要な読み込みおよび書き込み容量と必要なインデックスでプロビジョニングされたテーブルを 1 つの期間に 1 つ作成します。
-
各期間が終了する前に、次の期間でテーブルを事前に作成します。現在の期間が終了するように、イベントトラフィックを新しいテーブルにリダイレクトします。これらのテーブルには、記録した期間を指定する名前を割り当てることができます。
-
テーブルに書き込まれなくなったら、プロビジョニングされた書き込み容量を小さい値 (1 WCU など) に減らし、適切な読み込み容量をプロビジョニングします。時間の経過と共に、以前のテーブルのプロビジョニングされた読み込み容量を減らします。コンテンツがほとんど必要ないテーブルやコンテンツがまったく必要ないテーブルをアーカイブまたは削除することもできます。
トラフィックボリュームが最も多くなる現在の期間に必要なリソースを割り当て、アクティブに使用されなくなった以前のテーブルのプロビジョニングをスケールダウンすることでコストを削減できます。ビジネスニーズによっては、トラフィックを論理パーティションキーに均等に分散するために書き込みシャーディングを検討します。詳細については、「書き込みシャーディングを使用して DynamoDB テーブルでワークロードを均等に分散させる」を参照してください。
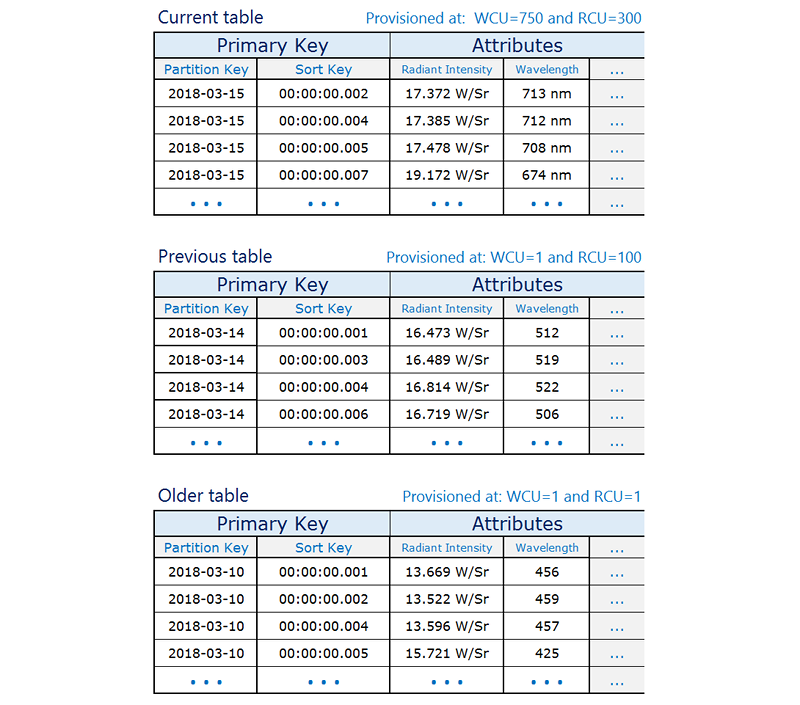
時系列テーブルの例
読み込み/書き込み容量が高いときに現在のテーブルがプロビジョニングされ、頻繁にアクセスされないために以前のテーブルが縮小される時系列データの例を以下に示します。