翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
最初の AWS DeepRacer モデルのトレーニング
このチュートリアルでは、AWS DeepRacer コンソールを使って最初のモデルをトレーニングする方法を紹介します。
AWS DeepRacer コンソールを使用して強化学習モデルをトレーニングします。
AWS DeepRacer コンソールの [モデルの作成] ボタンをクリックし、モデルトレーニングの旅をスタートします。
強化学習モデルをトレーニングするには
-
AWS DeepRacer を初めて使用する場合は、サービスのランディングページから [モデルの作成] を選択するか、メインのナビゲーションペインの見出しにある [強化学習] で、[スタートする] を選択します。
-
[強化学習をスタートする ] ページの [ステップ 2: モデルとレースを作成する] で、[モデルの作成] を選択します。
または、メインのナビゲーションペインの見出しにある [強化学習] で、[モデル] を選択します。[モデル] ページで、[モデルの作成] を選択します。
モデル名と環境を指定します。
モデルに名前を付けて、自分に合ったシミュレーショントラックを選択する方法を学びましょう。
モデル名と環境を指定
-
[モデルの作成] ページの、[トレーニングの詳細] で、モデル名を入力します。
-
必要に応じて、トレーニング ジョブの説明を追加します。
-
オプションタグの追加の詳細いついては、「Tagging」を参照してください。
-
[環境シミュレーション] で、AWS DeepRacer エージェントのトレーニング環境として機能するトラックを選択します。[トラック方向] で、時計回りまたは反時計回りを選択します。続いて、[次へ] を選択します。
最初の実行では、シンプルな形でターンの滑らかなトラックを選択します。後の反復では、モデルを徐々に改善するために、より複雑なトラックを選択できます。特定のレースイベントのモデルをトレーニングするには、そのイベントのトラックに最も近いトラックを選択します。
-
ページの一番下の [次へ] を選択します。
レースタイプとトレーニングアルゴリズムを選択します。
AWS DeepRacer コンソールには、3 つのレースタイプと 2 つのトレーニングアルゴリズムがあり、そこから選択できます。あなたのスキルレベルとトレーニングの目標に適したものを把握しましょう。
レースタイプとトレーニングアルゴリズムを選択する方法
-
「モデルの作成」ページの、[レースタイプ] で、[タイムトライアル]、[オブジェクトの回避]、または [Head-to-bot] を選択します。
最初の走行では、[タイムトライアル] を選択することをお勧めします。このレースタイプで、エージェントのセンサー構成を最適化するためのガイダンスについては、「タイムトライアル用に AWS DeepRacer トレーニングのカスタマイズする」を参照してください。
-
その後の走行では、[オブジェクト回避] を選択して、選択したトラックに沿って固定した位置、またはランダムな位置に配置された静止障害物を避けるオプションを選ぶことができます。詳細については、「オブジェクト回避レース向けの AWS DeepRacer トレーニングをカスタマイズする」を参照してください。
-
トレーニングシミュレーションの各エピソードの開始時に、[固定位置] を選択して、トラックの 2 つのレーンの固定位置にボックスを生成するか、[ランダムな位置] を選択して、2 つのレーンにランダムに分散されるオブジェクトを生成します。
-
次に、[トラック上のオブジェクトの数] の値を選択します。
-
「固定位置」を選択した場合は、トラック上の各オブジェクトの位置を調整できます。[レーンの配置] では、内側レーンと外側レーンのどちらかを選択します。デフォルトでは、オブジェクトはトラック全体に均等に分散されます。オブジェクトの開始位置と終了位置の間の距離を変更するには、「開始点と終了点の間の位置 (%)」フィールドに、その距離のパーセンテージを 7~90 の間で入力します。
-
-
より野心的な走行を行うには、[Head-to-bot レース] を選択して、一定の速度で移動するボット車両 (最大4台) と対戦するオプションもあります。詳細については、「head-to-bot レース向けの AWS DeepRacer トレーニングをカスタマイズします。」を参照してください。
-
[ボット車両の数を選ぶ] で、エージェントにトレーニングさせたいボット車両の数を選択します。
-
次に、ボット車両がトラック内を移動する速度を、ミリメートル/秒で選択します。
-
[レーンの変更を有効にする] ボックスをチェックして、ボット車両に 1〜5 秒ごとにランダムにレーンを変更する機能を与えるオプションもあります。
-
-
[トレーニングアルゴリズムとハイパーパラメータ] で、[Soft Actor Critic (SAC)] または [Proximal Policy Optimization (PPO)] アルゴリズムを選択します。AWS DeepRacer コンソールでは、SAC モデルを連続アクションスペースでトレーニングする必要があります。PPO モデルは、連続または離散アクションスペースのいずれかでトレーニングさせることができます。
-
[トレーニングアルゴリズムとハイパーパラメータ] で、デフォルトのハイパーパラメータ値をそのまま使用します。
後で、トレーニングのパフォーマンスを向上させるには [ハイパーパラメータ] を展開し、デフォルトのハイパーパラメータ値を次のように変更します。
-
[勾配降下バッチサイズ] には、利用可能なオプションを選択します。
-
[エポック数] には有効な値を設定してください。
-
[学習レート] には、有効な値を設定してください。
-
[SAC アルファ値] (SAC アルゴリズムのみ)、[有効な値] を設定します。
-
[エントロピー] には、有効な値を設定してください。
-
[割引係数] には、有効な値を設定してください。
-
[損失タイプ] では、利用可能なオプションを選択してください。
-
[各ポリシー更新反復の間エクスペリエンスエピソードの数] には、有効な値を設定してください。
ハイパーパラメータの詳細については、「ハイパーパラメータを体系的に調整する」を参照してください。
-
-
[次へ] を選択します。
アクションスペースの定義
[アクションスペースの定義] ページで、Soft Actor Critic (SAC) アルゴリズムを使用してトレーニングすることを選択した場合、デフォルトのアクションスペースは連続アクションスペースとなります。Proximal Policy Optimization (PPO) アルゴリズムを使用してトレーニングすることを選択した場合、[連続アクションスペース] と [離散アクションスペース] のいずれかを選択します。各アクションスペースとアルゴリズムがエージェントのトレーニング エクスペリエンスをどのように形作るかについての詳細はこちら「AWS DeepRacer アクションスペースと報酬関数」をご覧ください。
-
[連続アクションスペースの定義] で、[左側のステアリング角度範囲] と [右側のステアリング角度範囲] の度数を選択します。
各ステアリング角度の範囲に異なる度数を入力し、[動的セクターグラフ] で視覚化された、その範囲の変化を確認します。
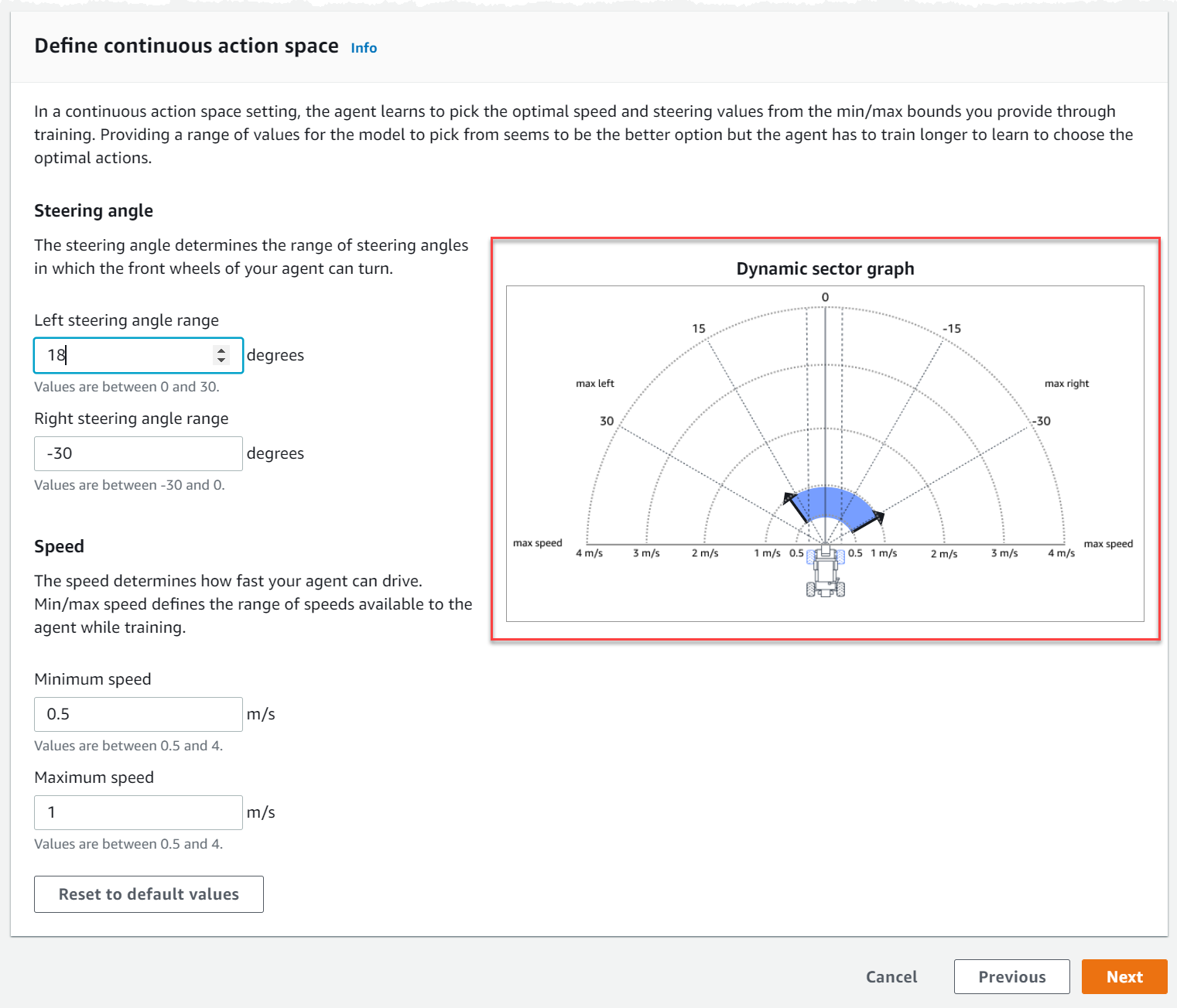
-
[速度] で、エージェントの最小速度と最高速度をミリメートル/秒で入力します。
変更がどのように [動的セクターグラフ] に反映されるかに注目してください。
-
必要に応じて、[デフォルト値にリセット] を選択して、不要な値をクリアします。実験や学習のために、グラフでさまざまな値を試してみることをお勧めします。
-
[次へ] を選択します。
-
ドロップダウンリストから、[ステアリング角度の粒度] の値を選択します。
-
エージェントの [最大ステアリング角度] 度数の値を 1 ~ 30 の範囲で選択します。
-
ドロップダウンリストから [速度の粒度] の値を選択します。
-
エージェントの [最大速度] を 0.1~4 の範囲の値から、ミリメートル/秒で選択します。
-
[アクションリスト] にデフォルトのアクション設定を使用するか、オプションで [アドバンスト設定] をオンに切り替えて、設定をチューニングします。[戻る] を選択する、または値を調整した後で [アドバンスト設定] をオフに切り替えると、変更内容が失われます。
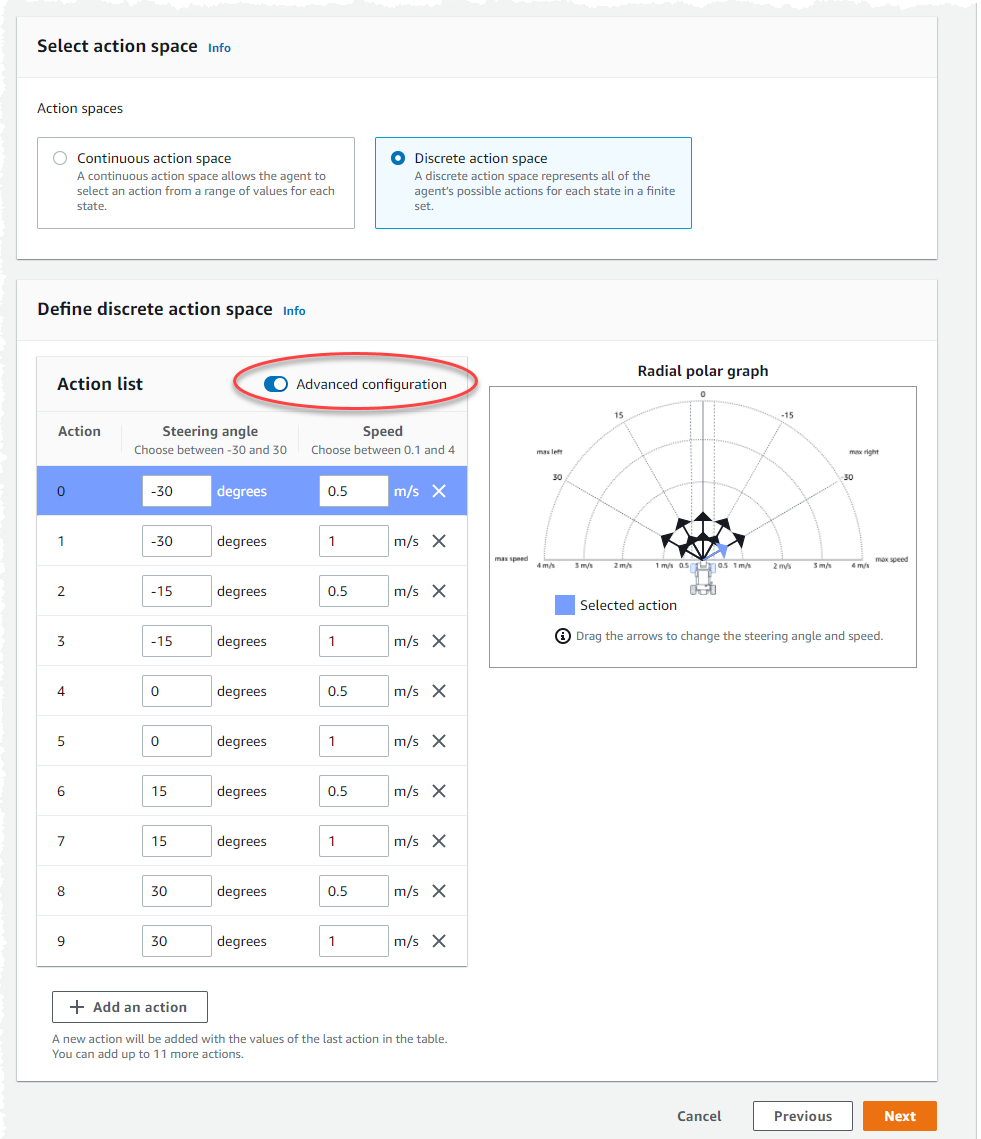
-
[ステアリング角度] 列に -30 から 30 の範囲の値を入力します。
-
最大 9 つのアクションに対して、[速度] 列に 0.1~4 の値をミリメートル/秒で入力します。
-
必要に応じて、[アクションを追加する] を選択し、アクションリストの行数を増やします。
![イメージ: [アクションを追加する] を選択して、アクションをアクションリストに追加します。](images/deepracer-add-an-action.png)
-
必要に応じて、行にある X を選択して削除します。
-
-
[次へ] を選択します。
バーチャルカーを選択
バーチャルカ―で使用をスタートする方法 毎月オープンディビジョンに出場して、新しいカスタムカー、ペイント ジョブ、改造をゲットしましょう。
バーチャルカーを選択する方法
-
[車両シェルとセンサー構成の選択] ページで、自分のレースタイプおよびアクションスペースと互換性のあるシェルを選択します。一致する車がガレージにない場合は、メイン ナビゲーションペインの見出しにある [強化学習] で、[ガレージ] を選択して作成します。
[タイムトライアル] トレーニングに必要なのは、オリジナルの DeepRacer にある、デフォルトのセンサー構成と一眼レフカメラだけです。他のすべてのシェルとセンサー構成は、アクションスペースが一致している場合に限り機能するようになっています。詳細については、「タイムトライアル用に AWS DeepRacer トレーニングのカスタマイズする」を参照してください。
ステレオカメラは オブジェクトの回避 トレーニングで役に立ちますが、固定位置にある静止した障害物を回避するためにはシングルカメラも使用することができます。LiDAR センサーは、オプションです。「AWS DeepRacer アクションスペースと報酬関数」を参照してください。
Head-to-bot トレーニングでは、シングルカメラまたはステレオカメラに加え、他の動いている車両を追い越しながら死角を検出して回避するのに、LiDAR ユニットが最適です。詳細については、「head-to-bot レース向けの AWS DeepRacer トレーニングをカスタマイズします。」を参照してください。
-
[次へ] を選択します。
報酬機能をカスタマイズします。
報酬関数は強化学習の中核です。それを利用して、トラック (環境) を探索するときに車 (エージェント) が特定の行動を起こすようにインセンティブを与える方法を学びます。ペットの特定の行動を奨励および阻止するように、このツールを使用して、車ができるだけ早くラップを終えるように促し、トラックから外れたり、物体に衝突したりしないようにすることができます。
報酬機能をカスタマイズする方法
-
[モデルの作成] ページの [報酬関数] で、最初のモデルのデフォルトの報酬関数の例をそのまま使用します。
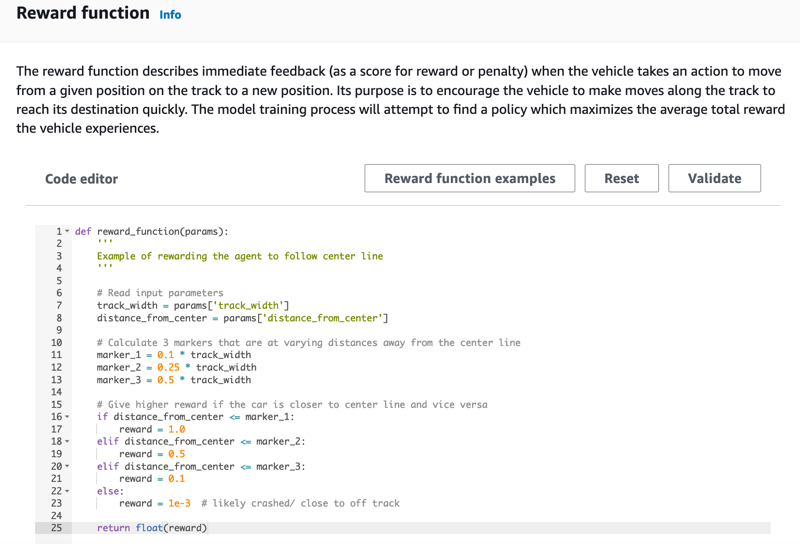
後で、[報酬関数の例] を選択して別の関数の例を選択し、[コードを使用] を選択して、選択した報酬関数を受け入れることができます。
4 つのサンプル関数からスタートすることができます。これらは、トラックの中央を走行する方法 (デフォルト)、トラックの境界線内にエージェントを維持する方法、ジグザグ運転を防止する方法、静止障害物やその他の走行車両への衝突を回避する方法を説明しています。
報酬関数の詳細については、「AWS DeepRacer 報酬関数のリファレンス」を参照してください。
-
[モデルの作成] ページの [停止条件] で、既定の [最大時間] 値をそのままにしておくか、新しい値を設定してトレーニングジョブを終了し、長時間の(また暴走の可能性がある)トレーニングジョブを防止します。
トレーニングの初期段階で実験を行うときは、このパラメータの小さい値からスタートし、徐々にトレーニングを長くしていきます。
-
[AWS DeepRacer に自動的に送信する] にある、[トレーニング完了後にこのモデルを AWS DeepRacer に自動的に送信し、賞品を獲得するチャンスを得る] は、デフォルトでチェックされています。オプションとして、チェックマークを選択してモデルの入力をオプトアウトできます。
-
[リーグ要件] で [居住国] を選択し、チェックボックスをオンにして利用規約に同意します。
-
[モデルの作成] を選択して、モデルの作成とトレーニング ジョブのインスタンスのプロビジョニングを開始します。
-
送信後、トレーニング ジョブが初期化されていることを確認してから実行します。
初期化プロセスでは、ステータスが [初期化中] から [進行中] になるまでに約 6 分かかります。
-
[報酬グラフ] と [シミュレーション ビデオ ストリーム] で、トレーニング ジョブの進捗状況を確認します。[報酬グラフ] の横にある更新ボタンを定期的に選択すると、トレーニング ジョブが完了するまで [報酬グラフ] を更新できます。
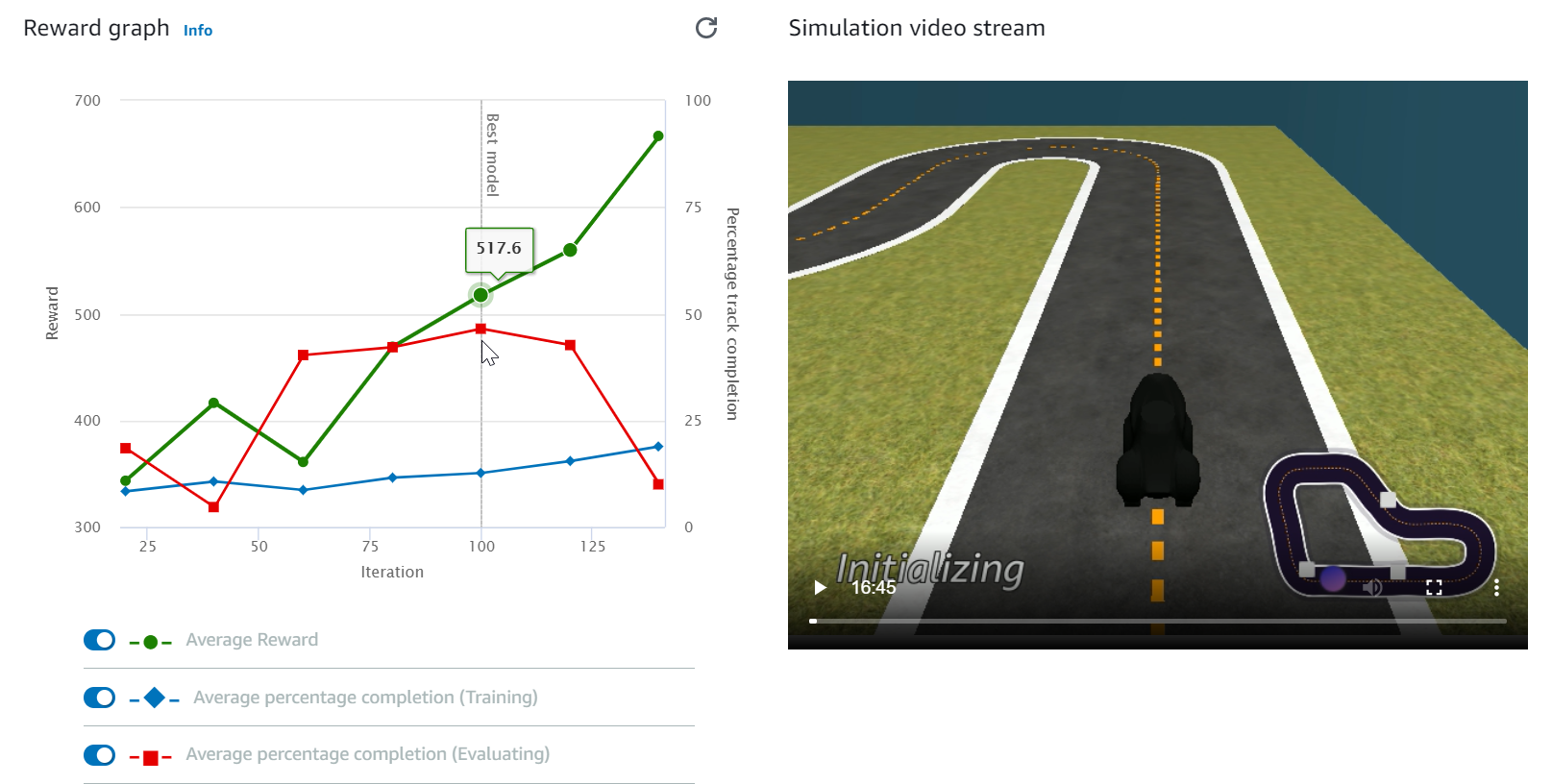
トレーニングジョブは AWS クラウドで実行されるため、AWS DeepRacer コンソールを開いたままにする必要はありません。ジョブの進行中はいつでもコンソールに戻ってモデルをチェックできます。
[ シミュレーション ビデオ ストリーム] ウィンドウ、または [報酬グラフ] の表示が反応しなくなった場合は、ブラウザ ページを更新してトレーニングの進行状況を更新します。
