翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon DocumentDB エラスティッククラスターの開始方法
このセクションでは、初めてのエラスティッククラスターを作成してクエリする方法を順を追って説明します。
Amazon DocumentDB に接続して開始する方法は複数あります。以下の手順は、ユーザーが私たちの強力なドキュメントデータベースの使用を開始するための最も迅速、シンプルかつ簡単な方法です。このガイドでは、AWS CloudShell を使用して、 AWS マネジメントコンソールから直接 Amazon DocumentDB クラスターに接続してクエリを実行します。 AWS 無料利用枠の対象となる新規のお客様は、Amazon DocumentDB と CloudShell を無料で使用できます。 AWS CloudShell 環境または Amazon DocumentDB エラスティッククラスターが無料利用枠を超えるリソースを使用する場合、それらのリソースの通常の AWS 料金が課金されます。このガイドでは、5 分以内に Amazon DocumentDB の使用を開始します。
トピック
前提条件
最初の Amazon DocumentDB クラスターを作成する前に、以下の操作を行う必要があります。
- Amazon Web Services (AWS) アカウントを作成する
-
Amazon DocumentDB を使用する前に、Amazon Web Services (AWS) アカウントを持っている必要があります。 AWS アカウントは無料です。使用しているサービスとリソースに対してのみ料金をお支払いいただきます。
がない場合は AWS アカウント、次の手順を実行して作成します。
にサインアップするには AWS アカウント
オンラインの手順に従います。
サインアップ手順の一環として、電話またはテキストメッセージを受け取り、電話キーパッドで検証コードを入力します。
にサインアップすると AWS アカウント、 AWS アカウントのルートユーザー が作成されます。ルートユーザーには、アカウントのすべての AWS のサービス とリソースへのアクセス権があります。セキュリティベストプラクティスとして、ユーザーに管理アクセス権を割り当て、ルートユーザーアクセスが必要なタスクの実行にはルートユーザーのみを使用するようにしてください。
- 必要な AWS Identity and Access Management (IAM) アクセス許可を設定します。
-
クラスター、インスタンス、クラスターパラメータグループなどの Amazon DocumentDB リソースを管理するには、 がリクエストの認証 AWS に使用できる認証情報が必要です。詳細については、「Amazon DocumentDB の Identity and Access Management」を参照してください。
-
の検索バーで AWS マネジメントコンソール、IAM と入力し、ドロップダウンメニューで IAM を選択します。
-
IAM コンソールにアクセスしたら、ナビゲーションペインから [ユーザー] を選択します。
-
ユーザーネームを選択します。
-
[Add permissions] (アクセス許可の追加) をクリックします。
-
[ポリシーを直接アタッチする] を選択します。
-
検索バーに
AmazonDocDBElasticFullAccessと入力し、検索結果に表示されたら、それを選択します。 -
[次へ] をクリックします。
-
[Add permissions] (アクセス許可の追加) をクリックします。
-
注記
AWS アカウントには、各リージョンにデフォルトの VPC が含まれています。Amazon VPC を使用することを選択した場合は、「Amazon VPC ユーザーガイド」の「Amazon VPC を作成する」トピックの手順を完了します。
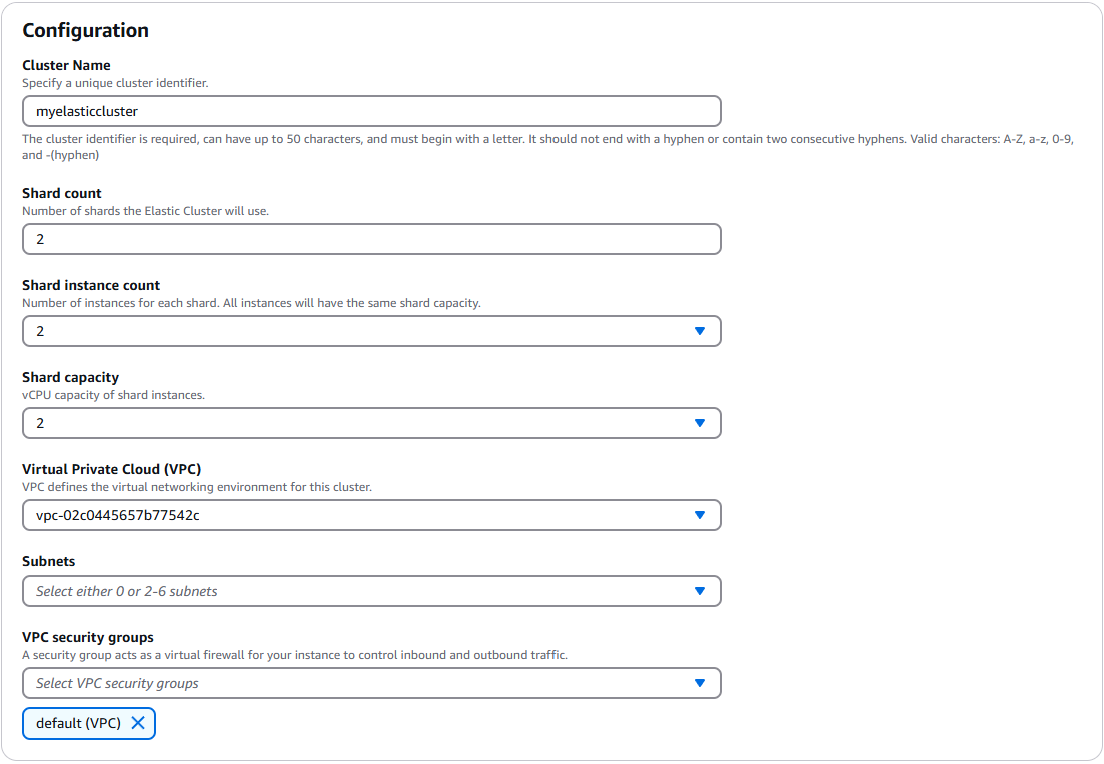
ステップ 1: エラスティッククラスターを作成する
このセクションでは、 AWS マネジメントコンソール または を使用して、以下の手順 AWS CLI で新しい Elastic クラスターを作成する方法について説明します。


![[ユーザー名] と [パスワード] の入力フィールドを含む [認証] セクション。](images/ec-gs-authentication.png)
![メンテナンスウィンドウオプションを示す [メンテナンス] セクション。](images/ec-gs-maintenance.png)
ステップ 2: エラスティッククラスターに接続する
を使用して Amazon DocumentDB エラスティッククラスターに接続します AWS CloudShell。
-
Amazon DocumentDB マネジメントコンソールの [クラスター] で、作成したエラスティッククラスターを探します。クラスターの横にあるチェックボックスをクリックして選択します。
![エラスティッククラスターを示す [Amazon DocumentDB クラスター管理] インターフェイス](images/ec-gs-cluster-new.png)
-
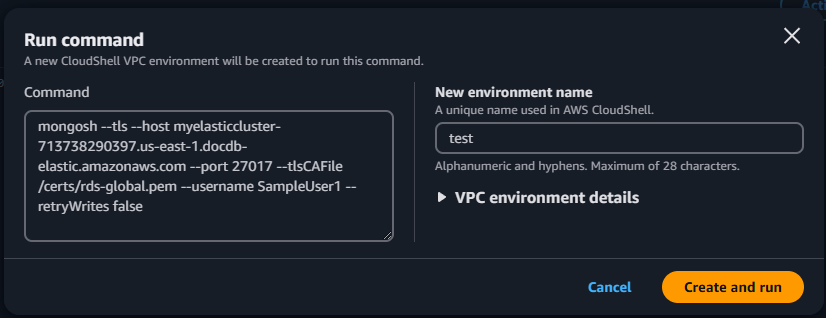
[クラスターに接続] をクリックします([アクション] ドロップダウンメニューの横にある)。このボタンは、クラスターの横にあるチェックボックスをクリックし、クラスターのステータスが 使用可能 と表示された後にのみ有効になります。CloudShell の [Run コマンド] 画面が表示されます。
-
[新しい環境の名前] フィールドに、「test」などの一意の名前を入力し、[作成して実行する] をクリックします。VPC 環境の詳細は、Amazon DocumentDB データベースに自動的に設定されます。
-
プロンプトが表示されたら、ステップ 1: Amazon DocumentDB エラスティッククラスターを作成する (サブステップ 5) で作成したパスワードを入力します。
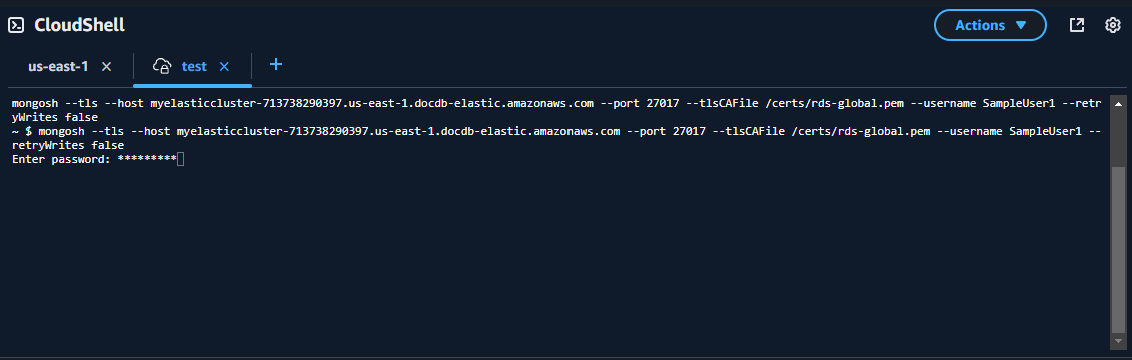
パスワードを入力して、プロンプトが
direct: mongos] <env-name>>に変わったら、Amazon DocumentDB クラスターに正常に接続できています
注記
トラブルシューティングについては、「Amazon DocumentDB のトラブルシューティング」を参照してください。
ステップ 3: コレクションをシャーディングし、データを挿入してクエリする
エラスティッククラスターでは Amazon DocumentDB でのシャーディングのサポートが追加されています。クラスターに接続できたので、クラスターをシャーディングし、データを挿入して、クエリを実行できます。
-
コレクションをシャーディングするには、次のように入力します。
sh.shardCollection("db.Employee1" , { "Employeeid" : "hashed" }) -
1 つのドキュメントを挿入するには、次のように入力します。
db.Employee1.insertOne({"Employeeid":1, "Name":"Joe", "LastName": "Bruin", "level": 1 })以下のような出力が表示されます。
WriteResult({ "nInserted" : 1 }) -
findOne()コマンドで書き込んだドキュメントを読み取るには、 コマンドを入力します (コマンドから一つのドキュメントが返される)。db.Employee1.findOne()以下のような出力が表示されます。
{ "_id" : ObjectId("61f344e0594fe1a1685a8151"), "EmployeeID" : 1, "Name" : "Joe", "LastName" : "Bruin", "level" : 1 } -
さらにクエリを実行するには、ゲームプロファイルのユースケースを検討してみてください。最初に、「Employee」というタイトルのコレクションにエントリをいくつか挿入します。次のように入力します。
db.profiles.insertMany([ { "_id": 1, "name": "Matt", "status": "active", "level": 12, "score": 202 }, { "_id": 2, "name": "Frank", "status": "inactive", "level": 2, "score": 9 }, { "_id": 3, "name": "Karen", "status": "active", "level": 7, "score": 87 }, { "_id": 4, "name": "Katie", "status": "active", "level": 3, "score": 27 } ])以下のような出力が表示されます。
{ acknowledged: true, insertedIds: { '0': ObjectId('679d02cd6b5a0581be78bcbd'), '1': ObjectId('679d02cd6b5a0581be78bcbe'), '2': ObjectId('679d02cd6b5a0581be78bcbf'), '3': ObjectId('679d02cd6b5a0581be78bcc0') } } -
プロファイルコレクション内のすべてのドキュメントを取得するには、
find() コマンドを使用します。db.Employee.find()ステップ 4 で入力したデータが表示されます。
-
1 つのドキュメントに対してクエリを発行するには、フィルター (「Katie」など) を含めます。次のように入力します。
db.Employee.find({name: "Katie"})以下のような出力が表示されます。
[ { _id: ObjectId('679d02cd6b5a0581be78bcc0'), Employeeid: 4, name: 'Katie', lastname: 'Schaper', level: 3 } ] -
プロファイルを見つけて変更するには、
findAndModifyコマンドを入力します。この例では、従業員「Matt」にはより高いレベル「14」が割り当てられています。db.Employee.findAndModify({ query: { "Employeeid" : 1, "name" : "Matt"}, update: { "Employeeid" : 1, "name" : "Matt", "lastname" : "Winkle", "level" : 14 } })以下のような出力が表示されます (レベルはまだ変更されていないことに注意してください)。
{ _id: ObjectId('679d02cd6b5a0581be78bcbd'), Employeeid: 1, name: 'Matt', lastname: 'Winkle', level: 12 } -
レベルが上がったことを確認するには、次のクエリを入力します。
db.Employee.find({name: "Matt"})以下のような出力が表示されます。
[ { _id: ObjectId('679d02cd6b5a0581be78bcbd'), Employeeid: 1, name: 'Matt', lastname: 'Winkle', level: 14 } ]
ステップ 4: 探索する
お疲れ様でした。Amazon DocumentDB エラスティッククラスターの開始手順が正常に完了しました。
次のステップ このデータベースを一般的な機能の一部を使用して、完全に活用する方法を学びましょう。
注記
この開始手順で作成したエラスティッククラスターは、削除しない限り、引き続きコストを計上します。手順については、「Elastic クラスターの削除」を参照してください。
