翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
コスト最適化 - ネットワーキング
高可用性 (HA) のシステム設計は、耐障害性と耐障害性を実現するためのベストプラクティスです。実際には、ワークロードと基盤となるインフラストラクチャを特定の AWS リージョンの複数のアベイラビリティーゾーン (AZs) に分散することを意味します。Amazon EKS 環境にこれらの特性があることを確認することで、システムの全体的な信頼性が向上します。これと組み合わせて、EKS 環境は、さまざまなコンストラクト (VPCs など)、コンポーネント (ELBs など)、統合 (ECR やその他のコンテナレジストリなど) で構成される可能性があります。
高可用性システムとその他のユースケース固有のコンポーネントの組み合わせは、データの転送と処理方法に大きな役割を果たします。これにより、データ転送と処理によって発生するコストにも影響します。
以下に詳述するプラクティスは、さまざまなドメインやユースケースでコスト効率を実現するために、EKS 環境を設計および最適化するのに役立ちます。
ポッド間の通信
設定によっては、Pod 間のネットワーク通信とデータ転送が Amazon EKS ワークロードの実行にかかる全体的なコストに大きな影響を与える可能性があります。このセクションでは、高可用性 (HA) アーキテクチャ、アプリケーションのパフォーマンス、耐障害性を考慮しながら、ポッド間通信に関連するコストを削減するためのさまざまな概念とアプローチについて説明します。
アベイラビリティーゾーンへのトラフィックの制限
Kubernetes プロジェクトは、障害ドメイン間のワークロード分散やトポロジ対応ボリュームプロビジョナーなどの機能を有効にするために、ノードに割り当てられた kubernetes.io/hostname、topology.kubernetes.io/region、topology.kubernetes.io/zone などのラベルを含むトポロジ対応コンストラクトの開発を早期に開始しました。Kubernetes 1.17 を卒業したことで、ラベルは Pod 間通信のトポロジ対応ルーティング機能を有効にするためにも活用されました。
以下は、コストを削減し、レイテンシーを最小限に抑えるために、EKS クラスター内のポッド間のクロス AZ トラフィックの量を制御する方法に関するいくつかの戦略です。
クラスター内のポッド間のクロス AZ トラフィックの量 (バイト単位で転送されるデータ量など) を詳細に可視化する場合は、この投稿を参照してください
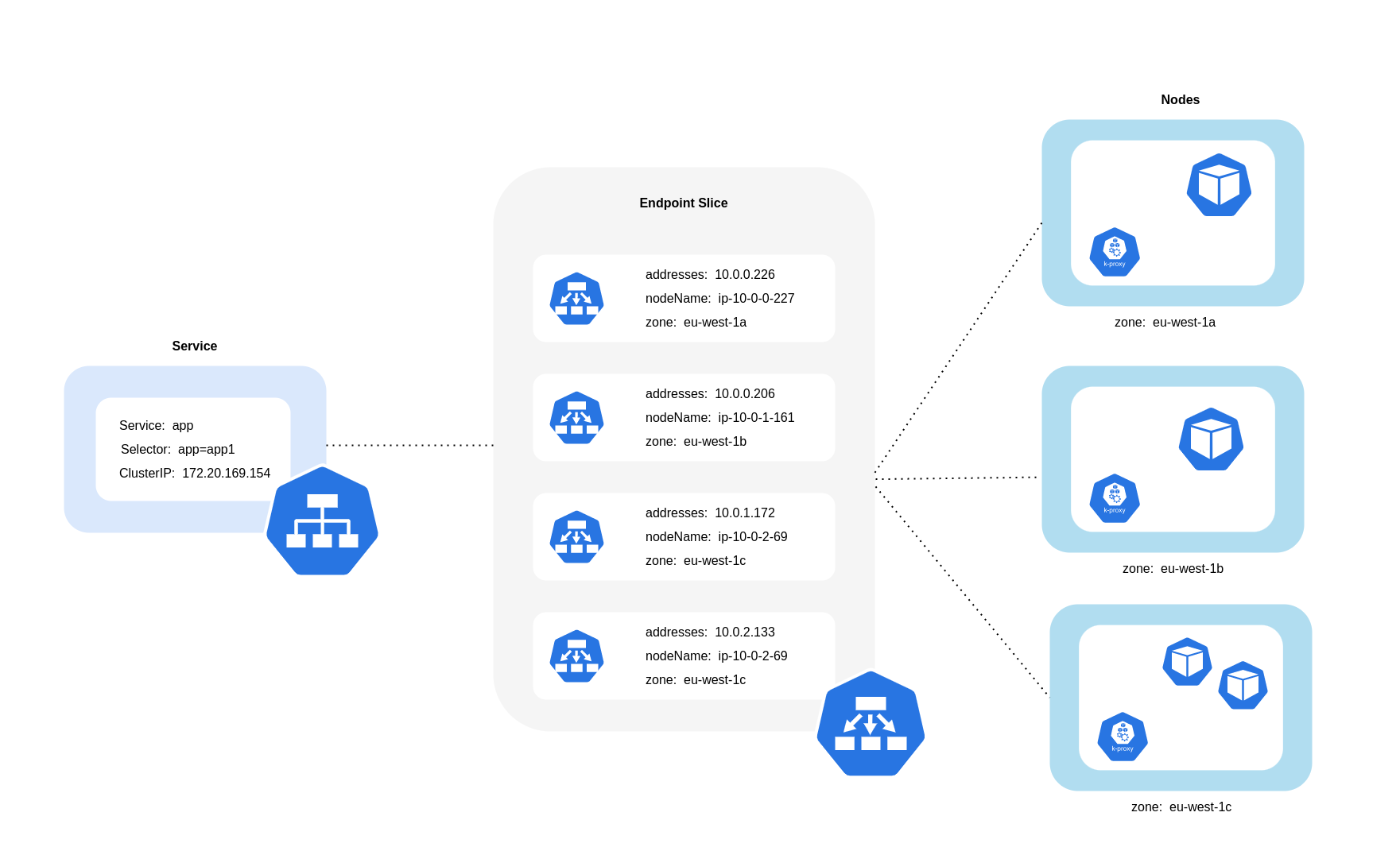
上記の図に示すように、サービスは Pod 宛てのトラフィックを受信する安定したネットワーク抽象化レイヤーです。サービスが作成されると、複数の EndpointSlices が作成されます。各 EndpointSlice には、Pod アドレスのサブセットと、それらが実行されているノード、および追加のトポロジ情報を含むエンドポイントのリストがあります。すべてのノードで実行されるデーモンセットである Amazon VPC CNI を使用する場合、 はネットワークルールを維持し、Pod 通信とサービス検出を有効にします (代替 eBPF ベースの CNIs は kube-proxy を使用しない場合がありますが、同等の動作を提供します)。内部ルーティングのロールは満たされますが、作成された EndpointSlices から消費されるものに基づいて行われます。
EKS では、kube-proxy は、ノードまたは AZ 配置に関係なく、クラスター内のすべてのポッドへのトラフィック分散に iptables NAT ルール (または IPVS、NFTables
トポロジ対応ルーティングの使用 (以前はトポロジ対応ヒントと呼ばれていました)
トポロジ対応ルーティングkube-proxyは、適用されるヒントに基づいて、ゾーンからエンドポイントにトラフィックをルーティングします。
次の図は、ヒントを含む EndpointSlices が、ゾーンのオリジンポイントに基づいてどの宛先に移動するかkube-proxyがわかるように編成されている方法を示しています。ヒントがない場合、このような割り当てや組織は存在せず、トラフィックは送信元に関係なく異なるゾーンの宛先にプロキシされます。
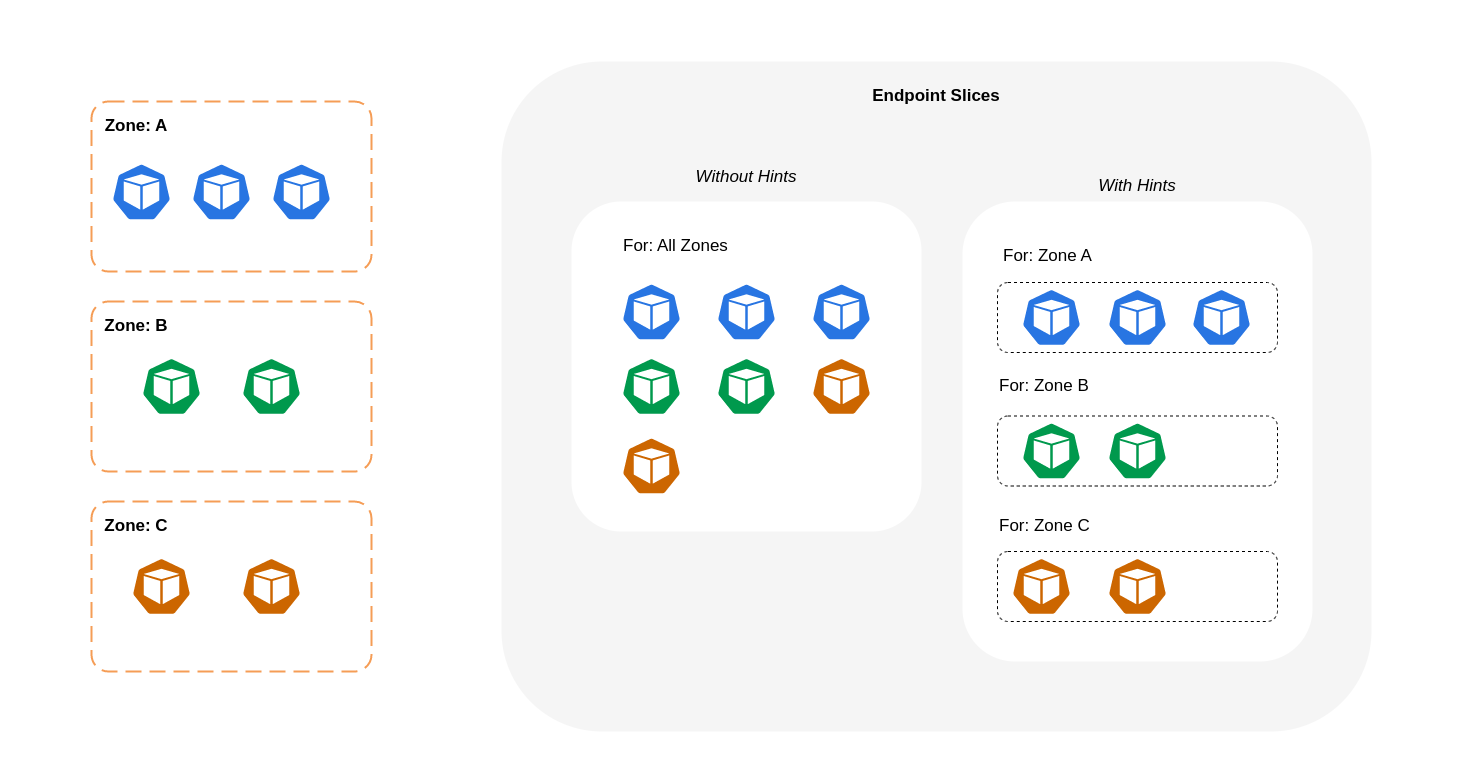
場合によっては、EndpointSlice コントローラーは別のゾーンにヒントを適用することがあります。つまり、エンドポイントは別のゾーンから発信されたトラフィックを処理する可能性があります。これは、異なるゾーンのエンドポイント間のトラフィックの均等な分散を維持しようとするためです。
以下は、サービスのトポロジ対応ルーティングを有効にする方法に関するコードスニペットです。
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce annotations: service.kubernetes.io/topology-mode: Auto spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
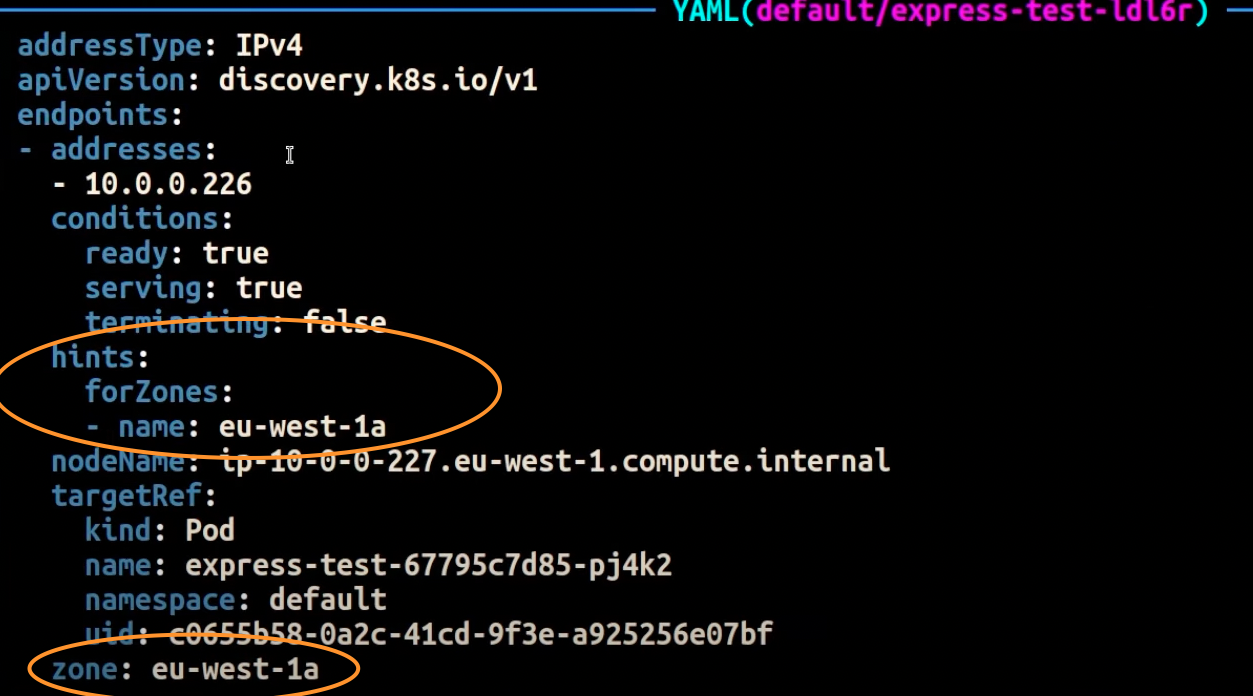
以下のスクリーンショットは、EndpointSlice コントローラーが AZ で実行されているポッドレプリカのエンドポイントにヒントを正常に適用した結果を示していますeu-west-1a。
注記
トポロジ対応ルーティングはまだベータ版であることに注意してください。この機能は、クラスタートポロジ全体で均等に分散されたワークロードでより予測しやすく機能します。コントローラーは、ゾーン間でエンドポイントを比例的に割り当てますが、ゾーン内のノードリソースのバランスが不均衡になりすぎて過剰なオーバーロードを回避すると、ヒントの割り当てをスキップする可能性があります。したがって、ポッドトポロジのスプレッド制約などのアプリケーションの可用性を高めるスケジューリング制約
トラフィック分散の使用
Kubernetes 1.30 で導入され、1.33 で一般公開されたトラフィックディストリビューション
以下は、サービスのトラフィック分散を有効にする方法に関するコードスニペットです。
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: trafficDistribution: PreferClose selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003
トラフィック分散を有効にすると、一般的な課題として、1 つの AZ 内のエンドポイントが過負荷になることがあります。ほとんどのトラフィックが同じゾーンから発信される場合です。このオーバーロードは重大な問題を引き起こす可能性があります。
-
マルチ AZ 配置を管理する 1 つの Horizontal Pod Autoscaler (HPA) は、異なる AZs。ただし、このアクションは、影響を受けるゾーンで増加した負荷に効果的に対処できません。
-
この状況は、リソースの非効率性につながる可能性があります。Karpenter などのクラスターオートスケーラーがさまざまな AZs 間でポッドのスケールアウトを検出すると、影響を受けていない AZs に追加のノードがプロビジョニングされ、不要なリソースの割り当てが発生する可能性があります。
この課題を克服するには:
-
ゾーンごとに個別のデプロイを作成し、独自の HPAs を使用して互いに独立してスケーリングします。
-
トポロジのスプレッド制約を活用して、クラスター全体のワークロード分散を確保します。これにより、トラフィックの多いゾーンでのエンドポイントの過負荷を防ぐことができます。
Autoscaler の使用: 特定の AZ にノードをプロビジョニングする
複数の AZ にまたがる高可用性環境でワークロードを実行することを強くお勧めAZs。これにより、特に AZ に問題がある場合に、アプリケーションの信頼性が向上します。ネットワーク関連のコストを削減するために信頼性を犠牲にする場合は、ノードを 1 つの AZ に制限できます。
同じ AZ ですべての Pod を実行するには、同じ AZ でワーカーノードをプロビジョニングするか、同じ AZ で実行されているワーカーノードで Pod をスケジュールします。単一の AZ 内にノードをプロビジョニングするには、Cluster Autoscaler (CA)topology.kubernetes.io/zoneを指定します。たとえば、次の Karpenter プロビジョナースニペットは、us-west-2a AZ のノードをプロビジョニングします。
Karpenter
apiVersion: karpenter.sh/v1 kind: Provisioner metadata: name: single-az spec: requirements: * key: "topology.kubernetes.io/zone"` operator: In values: ["us-west-2a"]
クラスターオートスケーラー (CA)
apiVersion: eksctl.io/v1alpha5 kind: ClusterConfig metadata: name: my-ca-cluster region: us-east-1 version: "1.21" availabilityZones: * us-east-1a managedNodeGroups: * name: managed-nodes labels: role: managed-nodes instanceType: t3.medium minSize: 1 maxSize: 10 desiredCapacity: 1 ...
ポッド割り当てとノードアフィニティの使用
または、複数の AZs で実行されているワーカーノードがある場合、各ノードには AZ の値 (us-west-2a や us-west-2b など) を含む topology.kubernetes.io/zonenodeSelector または を使用してnodeAffinity、単一の AZ 内のノードにポッドをスケジュールできます。たとえば、次のマニフェストファイルは、AZ us-west-2a で実行されているノード内の Pod をスケジュールします。
apiVersion: v1 kind: Pod metadata: name: nginx labels: env: test spec: nodeSelector: topology.kubernetes.io/zone: us-west-2a containers: * name: nginx image: nginx imagePullPolicy: IfNotPresent
ノードへのトラフィックの制限
ゾーンレベルでのトラフィックの制限では不十分な場合があります。コストを削減するだけでなく、頻繁に相互通信を行う特定のアプリケーション間のネットワークレイテンシーを減らすという要件も追加される場合があります。最適なネットワークパフォーマンスを実現し、コストを削減するには、特定のノードへのトラフィックを制限する方法が必要です。たとえば、マイクロサービス A は、高可用性 (HA) セットアップであっても、ノード 1 のマイクロサービス B と常に通信する必要があります。ノード 1 のマイクロサービス A がノード 2 のマイクロサービス B と通信すると、特にノード 2 が別の AZ にある場合、この種のアプリケーションに必要なパフォーマンスに悪影響を及ぼす可能性があります。
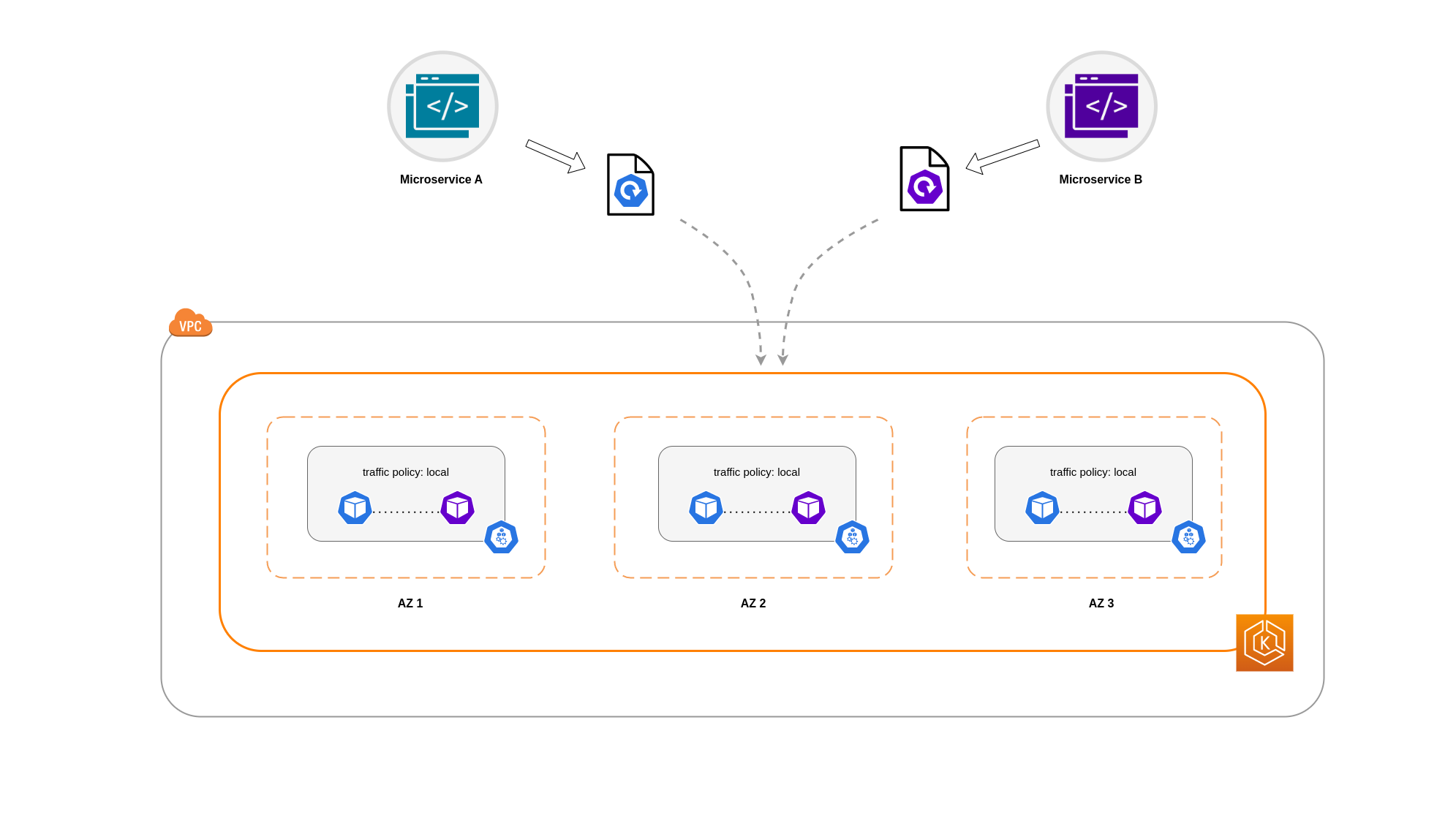
サービス内部トラフィックポリシーの使用
Pod ネットワークトラフィックをノードに制限するには、サービス内部トラフィックポリシーLocal、トラフィックはトラフィックの送信元のノード上のエンドポイントに制限されます。このポリシーは、ノードローカルエンドポイントの排他的な使用を指示します。つまり、そのワークロードのネットワークトラフィック関連のコストは、ディストリビューションがクラスター全体であった場合よりも低くなります。また、レイテンシーが低くなり、アプリケーションのパフォーマンスが向上します。
注記
この機能は、Kubernetes のトポロジ対応ルーティングと組み合わせることはできません。
以下は、サービスの内部トラフィックポリシーを設定する方法に関するコードスニペットです。
apiVersion: v1 kind: Service metadata: name: orders-service namespace: ecommerce spec: selector: app: orders type: ClusterIP ports: * protocol: TCP port: 3003 targetPort: 3003 internalTrafficPolicy: Local
トラフィックの減少によるアプリケーションからの予期しない動作を回避するには、次のアプローチを検討する必要があります。
-
通信ポッドごとに十分なレプリカを実行する
-
通信ポッドのコロケーションにポッドアフィニティルール
を使用する
この例では、マイクロサービス A のレプリカが 2 つ、マイクロサービス B のレプリカが 3 つあります。マイクロサービス A のレプリカがノード 1 と 2 の間に分散されていて、マイクロサービス B のレプリカがノード 3 にある場合、Local内部トラフィックポリシーのため通信できません。使用可能なノードローカルエンドポイントがない場合、トラフィックはドロップされます。
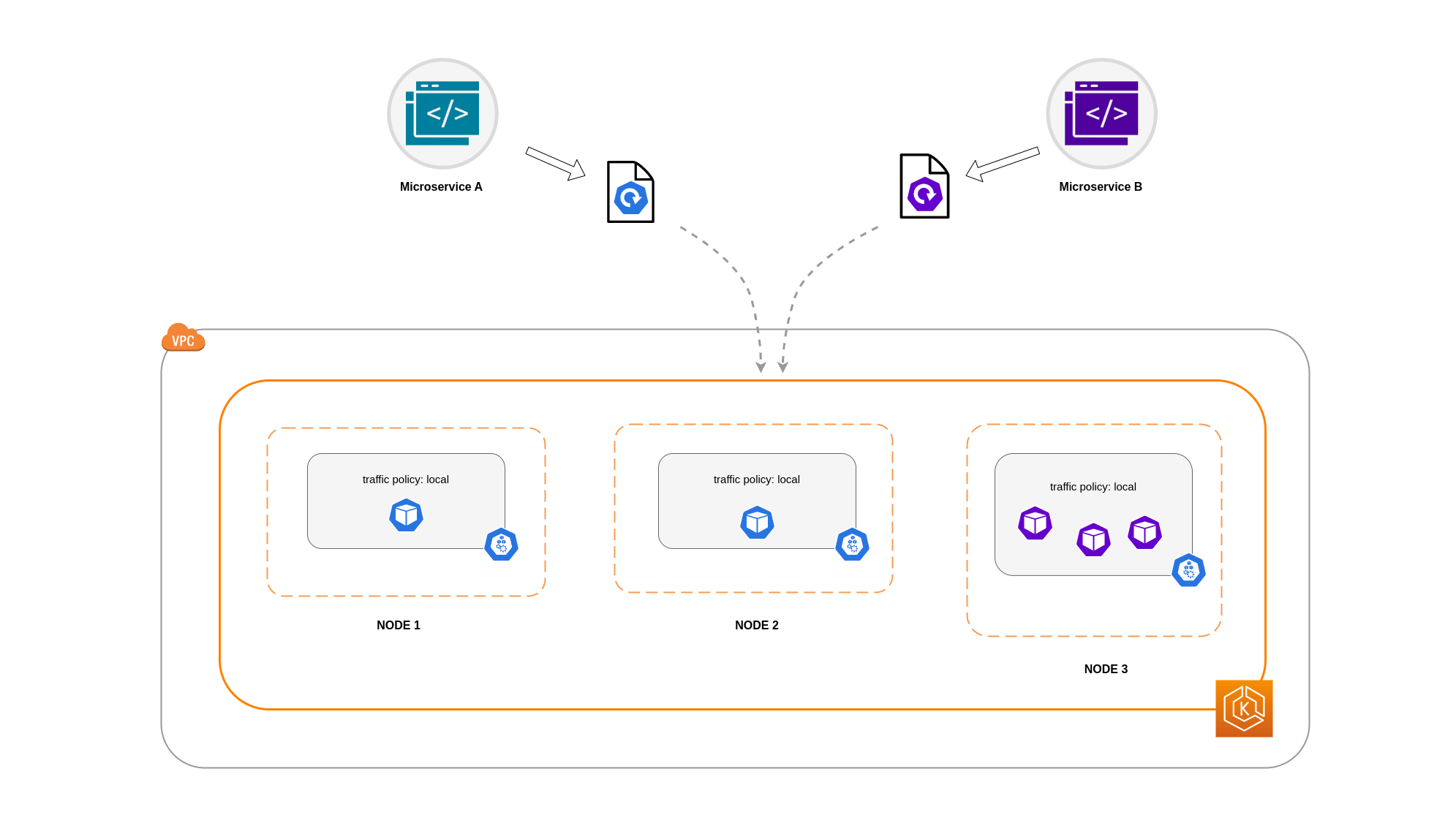
Microservice B にノード 1 と 2 の 3 つのレプリカのうち 2 つがある場合、ピアアプリケーション間の通信が行われます。ただし、マイクロサービス B の分離されたレプリカには、通信するピアレプリカがありません。
注記
シナリオによっては、上記の図に示されているような分離されたレプリカが目的 (外部受信トラフィックからのリクエストの処理など) を満たしていても、懸念の原因にならない場合があります。
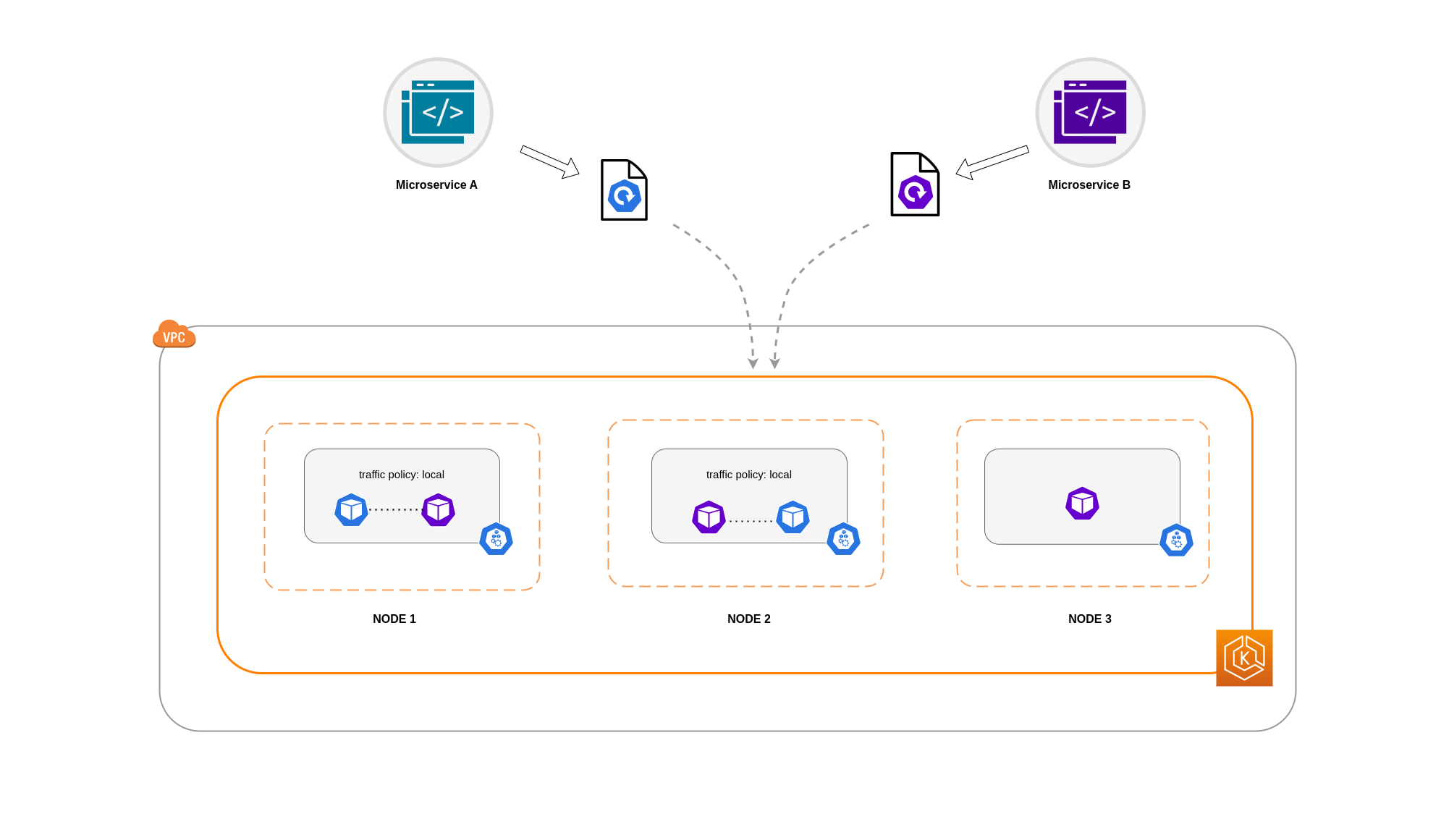
トポロジのスプレッド制約によるサービス内部トラフィックポリシーの使用
内部トラフィックポリシーをトポロジの分散制約と組み合わせて使用すると、異なるノードでマイクロサービスを通信するための適切な数のレプリカを確保できます。
apiVersion: apps/v1 kind: Deployment metadata: name: express-test spec: replicas: 6 selector: matchLabels: app: express-test template: metadata: labels: app: express-test tier: backend spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: express-test
ポッドアフィニティルールでの サービス内部トラフィックポリシーの使用
もう 1 つの方法は、サービス内部トラフィックポリシーを使用するときに Pod アフィニティルールを使用することです。Pod アフィニティを使用すると、スケジューラに影響を与えて、頻繁な通信のために特定の Pod をコロケーションできます。特定の Pod に厳密なスケジューリング制約 (requiredDuringSchedulingIgnoredDuringExecution) を適用することで、スケジューラがノードに Pod を配置するときの Pod コロケーションの結果が向上します。
apiVersion: apps/v1 kind: Deployment metadata: name: graphql namespace: ecommerce labels: app.kubernetes.io/version: "0.1.6" ... spec: serviceAccountName: graphql-service-account affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname"
Load Balancerからポッドへの通信
EKS ワークロードには通常、EKS クラスター内の関連する Pod にトラフィックを分散するロードバランサーが前面に配置されます。アーキテクチャは、内部および/または外部向けロードバランサーで構成される場合があります。アーキテクチャとネットワークトラフィックの設定によっては、ロードバランサーと Pod 間の通信がデータ転送料金に大きく影響する可能性があります。
AWS Load Balancer Controller
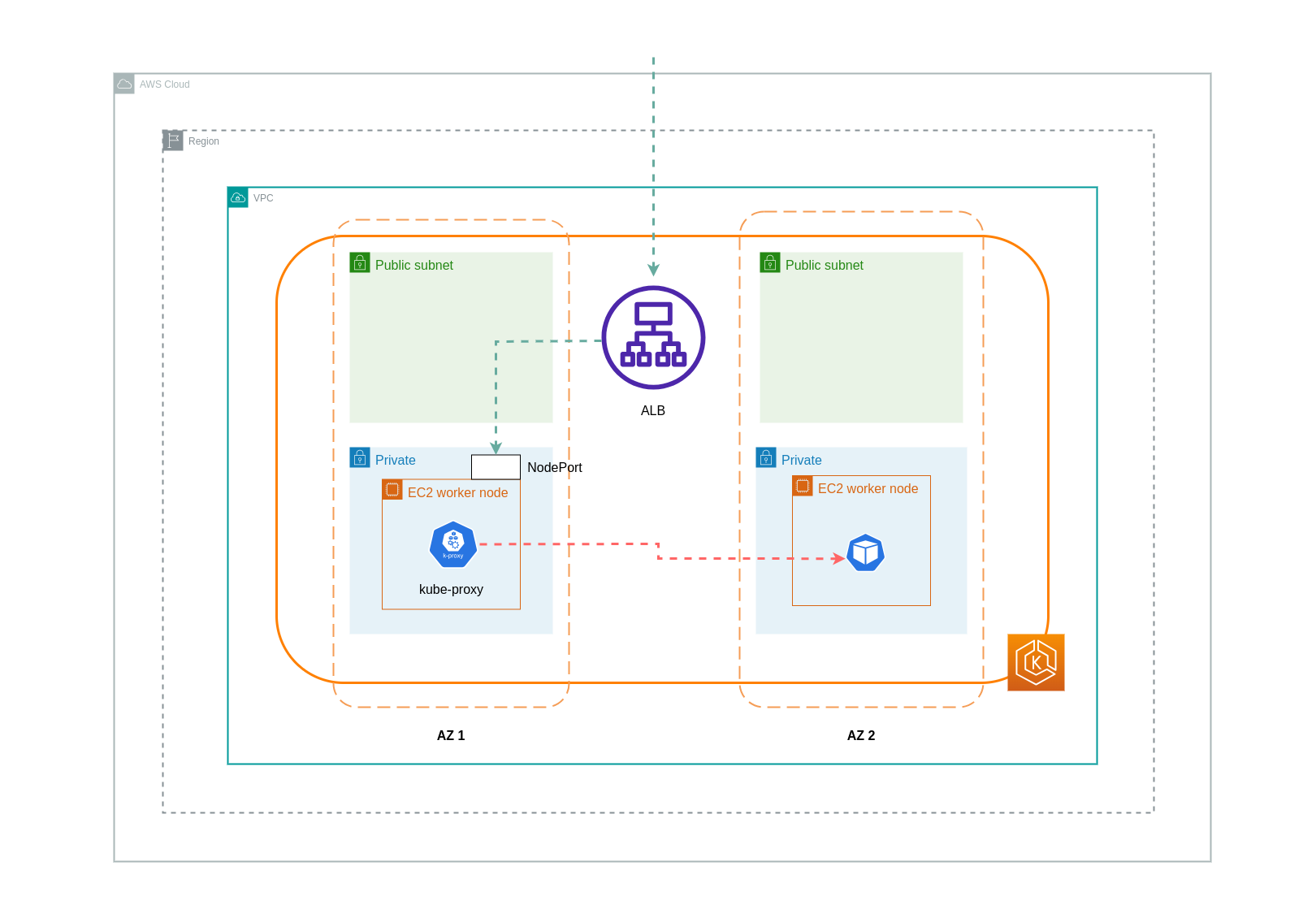
インスタンスモードを使用すると、EKS クラスターの各ノードで NodePort が開きます。その後、ロードバランサーはノード間でトラフィックを均等にプロキシします。ノードで送信先 Pod が実行されている場合、データ転送コストは発生しません。ただし、送信先 Pod が別のノードにあり、トラフィックを受信する NodePort とは異なる AZ にある場合、kube-proxy から送信先 Pod への追加のネットワークホップが発生します。このようなシナリオでは、AZ 間のデータ転送料金が発生します。ノード間でトラフィックが均等に分散されるため、kube-proxies から関連する送信先 Pod へのクロスゾーンネットワークトラフィックホップに関連する追加のデータ転送料金が発生する可能性が高くなります。
以下の図は、ロードバランサーから NodePort に、その後 から別の AZ の別のノードの宛先 Pod kube-proxyに流れるトラフィックのネットワークパスを示しています。これは、インスタンスモード設定の例です。
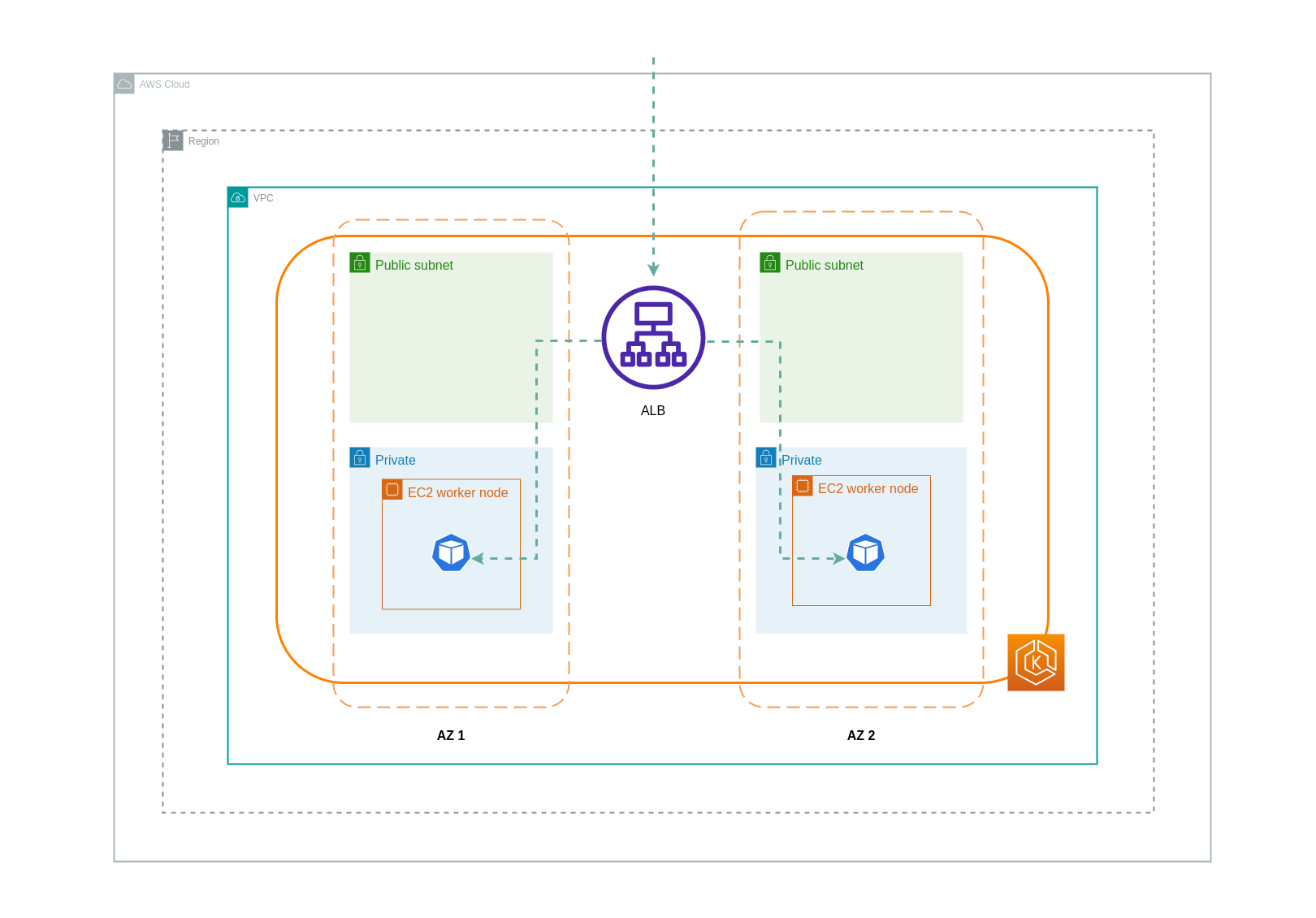
ip モードを使用する場合、ネットワークトラフィックはロードバランサーから送信先 Pod に直接プロキシされます。そのため、このアプローチにはデータ転送料金はかかりません。
注記
データ転送料金を削減するために、ロードバランサーを ip トラフィックモードに設定することをお勧めします。この設定では、ロードバランサーが VPC 内のすべてのサブネットにデプロイされていることを確認することも重要です。
以下の図は、ロードバランサーからネットワーク IP モードで Pod に流れるトラフィックのネットワークパスを示しています。
コンテナレジストリからのデータ転送
Amazon ECR
Amazon ECR プライベートレジストリへのデータ転送は無料です。リージョン内データ転送にはコストはかかりませんが、インターネットへのデータ転送とリージョン間のデータ転送には、転送の両側でインターネットデータ転送料金が課金されます。
ECRs の組み込みイメージレプリケーション機能を使用して、関連するコンテナイメージをワークロードと同じリージョンにレプリケートする必要があります。これにより、レプリケーションは 1 回課金され、同じリージョン (リージョン内) のイメージプルはすべて無料になります。
インターフェイス VPC エンドポイントを使用してリージョン内の ECR リポジトリに接続することで、ECR からのイメージのプル (データ転送) に関連するデータ転送コストをさらに削減できます。ECR のパブリック AWS エンドポイントに接続する別の方法 (NAT ゲートウェイとインターネットゲートウェイ経由) では、データ処理と転送のコストが高くなります。次のセクションでは、ワークロードと AWS サービス間のデータ転送コストの削減について詳しく説明します。
特に大きなイメージでワークロードを実行している場合は、キャッシュされたコンテナイメージを使用して独自のカスタム Amazon マシンイメージ (AMIs) を構築できます。これにより、コンテナレジストリから EKS ワーカーノードへの初期イメージのプル時間と潜在的なデータ転送コストを削減できます。
インターネットおよび AWS サービスへのデータ転送
インターネット経由で Kubernetes ワークロードを他の AWS のサービスやサードパーティーのツールやプラットフォームと統合するのが一般的な方法です。関連する送信先との間でトラフィックをルーティングするために使用される基盤となるネットワークインフラストラクチャは、データ転送プロセスで発生するコストに影響を与える可能性があります。
NAT ゲートウェイの使用
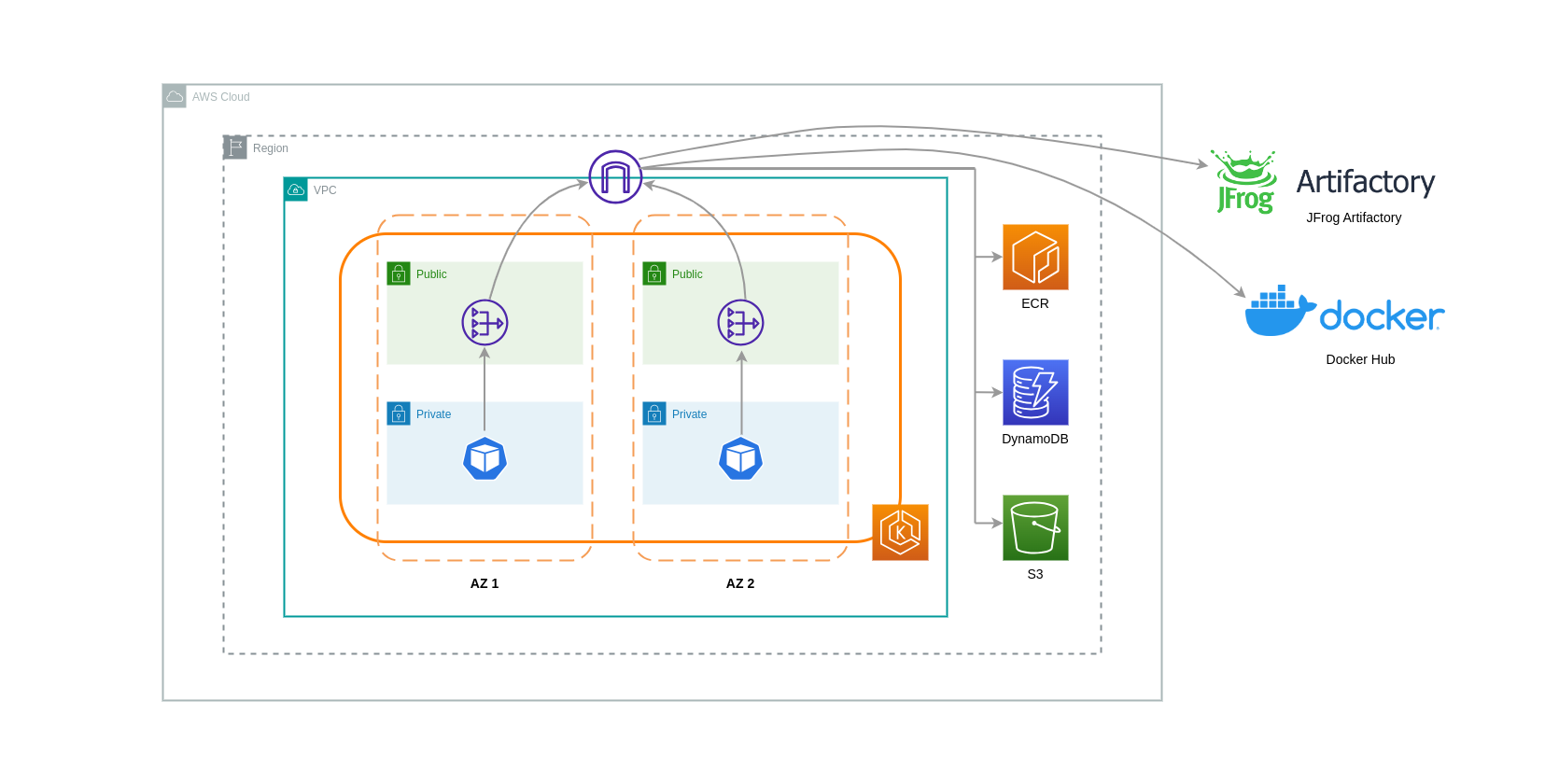
NAT ゲートウェイは、ネットワークアドレス変換 (NAT) を実行するネットワークコンポーネントです。次の図は、他の AWS サービス (Amazon ECR、DynamoDB、S3) およびサードパーティープラットフォームと通信する EKS クラスター内の Pod を示しています。この例では、ポッドは個別の AZs。インターネットからトラフィックを送受信するために、NAT ゲートウェイが 1 つの AZ のパブリックサブネットにデプロイされ、プライベート IP アドレスを持つリソースが 1 つのパブリック IP アドレスを共有してインターネットにアクセスできるようになります。この NAT Gateway は、インターネットゲートウェイコンポーネントと通信し、パケットを最終送信先に送信できるようにします。

このようなユースケースで NAT ゲートウェイを使用する場合、各 AZ に NAT ゲートウェイをデプロイすることで、データ転送コストを最小限に抑えることができます。これにより、インターネットにルーティングされるトラフィックは同じ AZ の NAT ゲートウェイを通過し、AZ 間のデータ転送を回避できます。ただし、AZ 間データ転送のコストを節約できますが、この設定は、アーキテクチャに追加の NAT ゲートウェイのコストが発生することを意味します。
この推奨アプローチを次の図に示します。
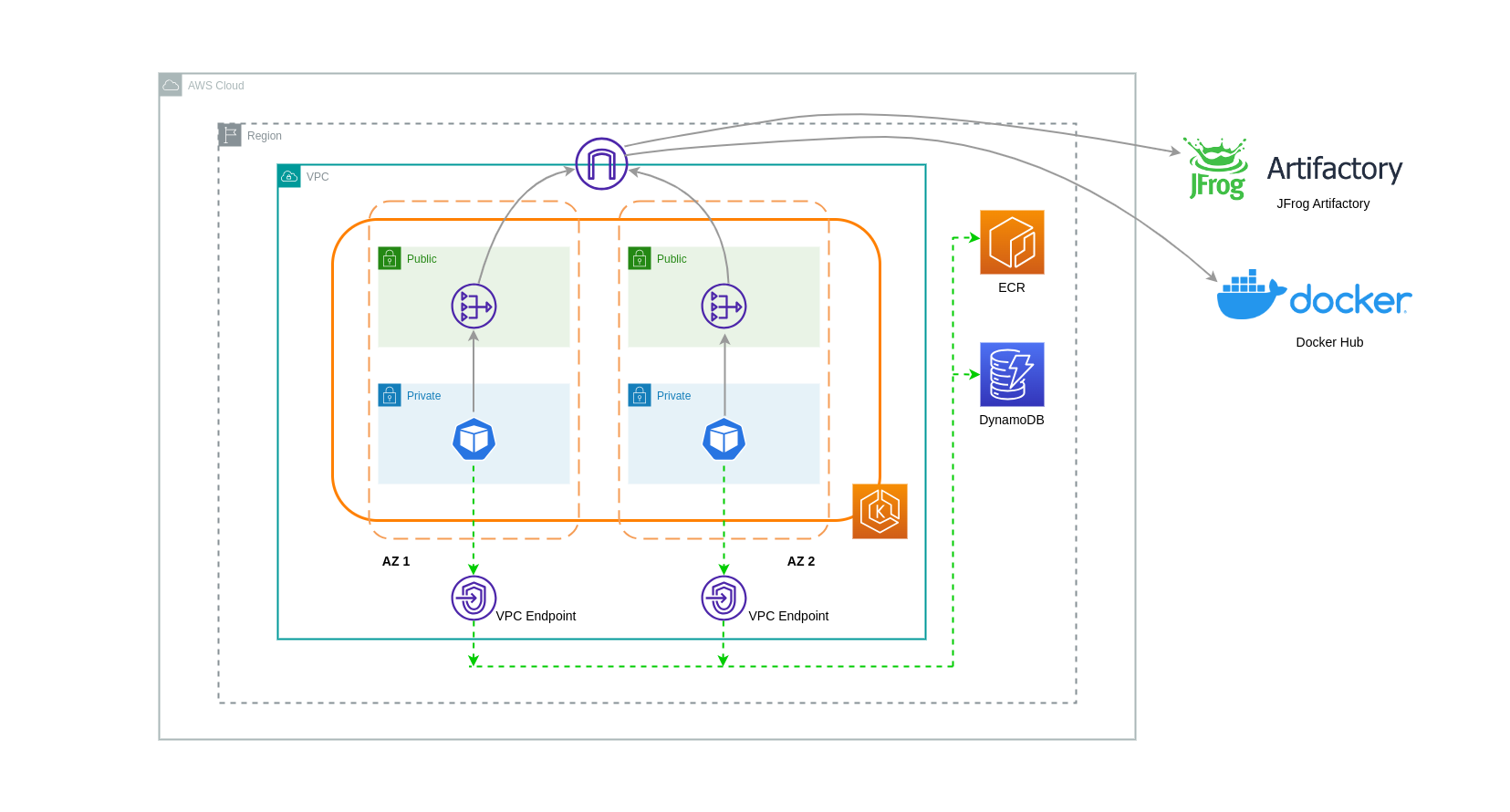
VPC エンドポイントの使用
このようなアーキテクチャのコストをさらに削減するには、VPC エンドポイントを使用してワークロードと AWS サービス間の接続を確立する必要があります。VPC エンドポイントを使用すると、データ/ネットワークパケットがインターネットを通過することなく、VPC 内から AWS のサービスにアクセスできます。すべてのトラフィックは内部であり、AWS ネットワーク内にとどまります。VPC エンドポイントには、インターフェイス VPC エンドポイント (多くの AWS サービスでサポート) とゲートウェイ VPC エンドポイント (S3 と DynamoDB でのみサポート) の 2 種類があります。
ゲートウェイ VPC エンドポイント
Gateway VPC エンドポイントに関連する時間単位またはデータ転送コストはありません。ゲートウェイ VPC エンドポイントを使用する場合は、VPC の境界を越えて拡張できないことに注意してください。VPC ピアリング、VPN ネットワーク、または Direct Connect 経由で使用することはできません。
インターフェイス VPC エンドポイント
VPC エンドポイントには時間単位の料金
次の図は、VPC エンドポイントを介して AWS サービスと通信するポッドを示しています。
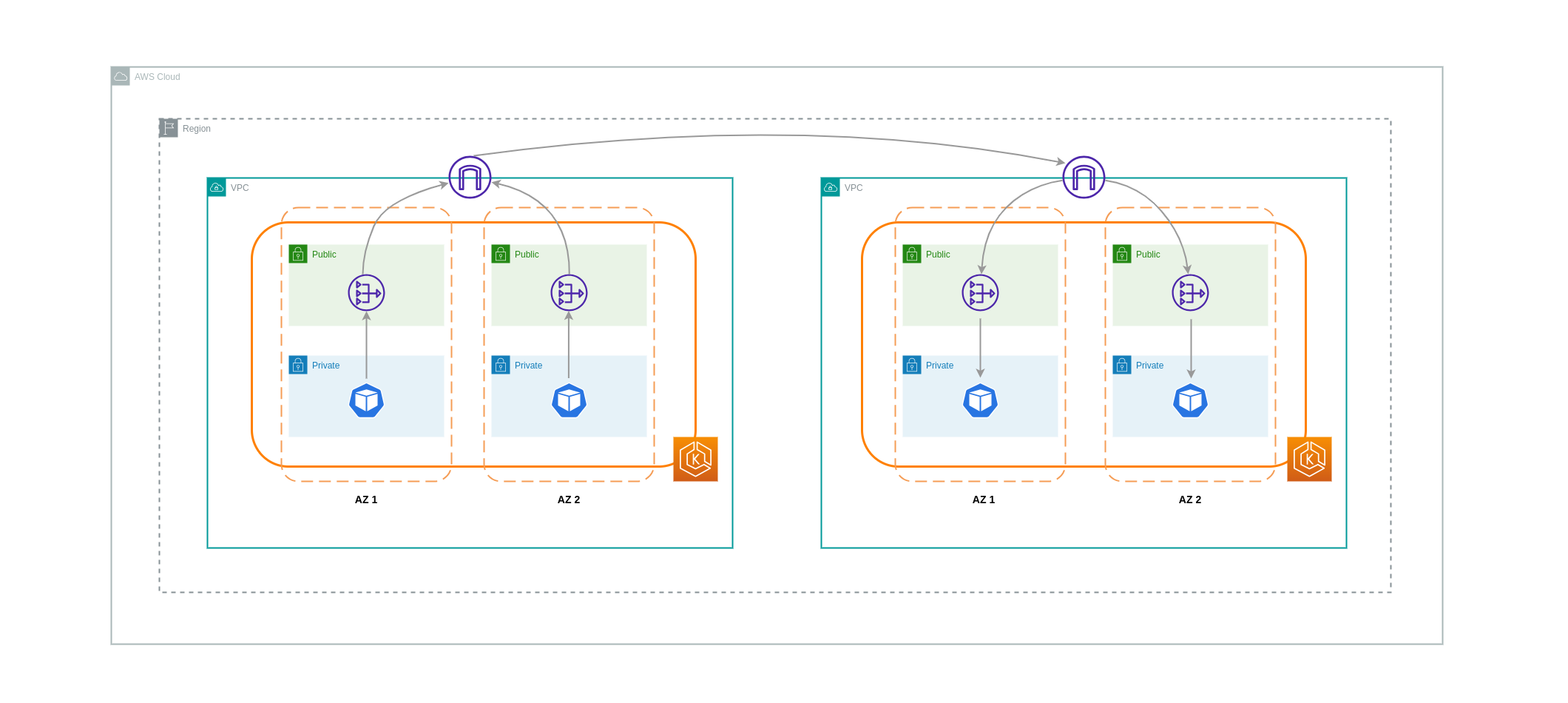
VPCs間のデータ転送
場合によっては、異なる VPCs (同じ AWS リージョン内) にワークロードがあり、相互に通信する必要がある場合があります。これは、トラフィックがそれぞれの VPCs にアタッチされたインターネットゲートウェイを介してパブリックインターネットを通過できるようにすることで実現できます。このような通信を有効にするには、EC2 インスタンス、NAT ゲートウェイ、NAT インスタンスなどのインフラストラクチャコンポーネントをパブリックサブネットにデプロイします。ただし、これらのコンポーネントを含むセットアップでは、VPCs との間でデータを処理/転送するための料金が発生します。個別の VPCs との間のトラフィックが AZs 間で移動する場合は、データ転送に追加料金が発生します。以下の図は、NAT ゲートウェイとインターネットゲートウェイを使用して、異なる VPCs 内のワークロード間の通信を確立するセットアップを示しています。
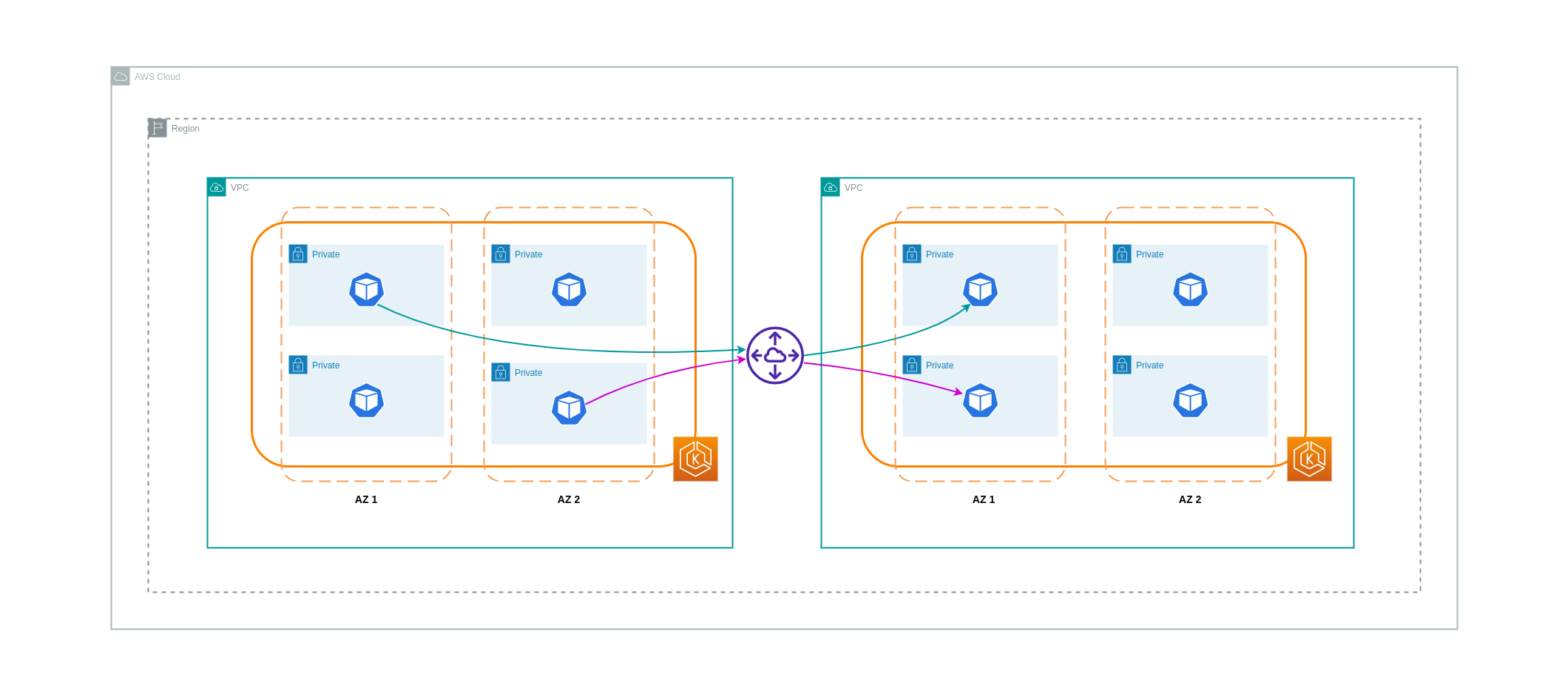
VPC ピアリング接続
このようなユースケースのコストを削減するために、VPC ピアリングを使用できます。VPC ピアリング接続では、同じ AZ 内に留まるネットワークトラフィックに対してデータ転送料金は発生しません。トラフィックが AZs を超えると、コストが発生します。ただし、同じ AWS リージョン内の別々の VPC 内のワークロード間のコスト効率の高い通信にはVPCs ピアリングアプローチが推奨されます。ただし、VPC ピアリングは推移的なネットワークを許可しないため、主に 1:1 VPC 接続に有効であることに注意してください。
次の図は、VPC ピアリング接続を介したワークロード通信の概要を示しています。
推移的なネットワーク接続
前のセクションで説明したように、VPC ピアリング接続では推移的なネットワーク接続は許可されません。3 つ以上の VPCs を推移的なネットワーク要件で接続する場合は、Transit Gateway (TGW) を使用する必要があります。これにより、VPC ピアリングの制限や、複数の VPC 間の複数の VPC ピアリング接続に関連する運用オーバーヘッドVPCs克服できます。TGW に送信されたデータに対して、時間単位で課金
次の図は、異なる VPCs 内の同じ AWS リージョン内のワークロード間で TGW を通過する AZ 間トラフィックを示しています。
Service Mesh の使用
サービスメッシュは、EKS クラスター環境のネットワーク関連コストを削減するために使用できる強力なネットワーク機能を提供します。ただし、サービスメッシュを採用すると、サービスメッシュが環境にもたらす運用タスクと複雑さを慎重に検討する必要があります。
トラフィックをアベイラビリティーゾーンに制限する
Istio の Locality 加重ディストリビューションの使用
Istio を使用すると、ルーティングの発生後にネットワークポリシーをトラフィックに適用できます。これは、ローカリティ加重分散
注記
上記の Istio 送信先ルールは、ロードバランサーから EKS クラスター内の Pod へのトラフィックを管理するためにも適用できます。ローカル加重分散ルールは、高可用性ロードバランサー (特に Ingress Gateway) からトラフィックを受信するサービスに適用できます。これらのルールにより、ゾーンオリジン - この場合のロードバランサーに基づいて、 へのトラフィック量を制御できます。正しく設定すると、異なる AZs のポッドレプリカにトラフィックを均等またはランダムに分散するロードバランサーと比較して、エグレスクロスゾーントラフィックが少なくなります。
以下は、Istio の送信先ルールリソースのコードブロックの例です。以下に示すように、このリソースは、eu-west-1リージョン内の 3 つの異なる AZs からの着信トラフィックの加重設定を指定します。これらの設定は、特定の AZ からの受信トラフィックの大部分 (この場合は 70%) を、送信元と同じ AZ の送信先にプロキシする必要があることを宣言します。
apiVersion: networking.istio.io/v1beta1 kind: DestinationRule metadata: name: express-test-dr spec: host: express-test.default.svc.cluster.local trafficPolicy: loadBalancer: + localityLbSetting: distribute: - from: eu-west-1/eu-west-1a/ + to: "eu-west-1/eu-west-1a/_": 70 "eu-west-1/eu-west-1b/_": 20 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1b/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 70 "eu-west-1/eu-west-1c/_": 10 - from: eu-west-1/eu-west-1c/_ + to: "eu-west-1/eu-west-1a/_": 20 "eu-west-1/eu-west-1b/_": 10 "eu-west-1/eu-west-1c/*": 70** connectionPool: http: http2MaxRequests: 10 maxRequestsPerConnection: 10 outlierDetection: consecutiveGatewayErrors: 1 interval: 1m baseEjectionTime: 30s
注記
分散先として指定できる最小重みは 1% です。これは、メイン送信先のエンドポイントが異常または使用できなくなった場合に備えて、フェイルオーバーリージョンとゾーンを維持するためです。
次の図は、eu-west-1 リージョンに高可用性ロードバランサーがあり、ローカリティ加重分散が適用されるシナリオを示しています。この図の送信先ルールポリシーは、eu-west-1a からのトラフィックの 60% を同じ AZ の Pod に送信するように設定されていますが、eu-west-1a からのトラフィックの 40% は eu-west-1b の Pod に送信する必要があります。
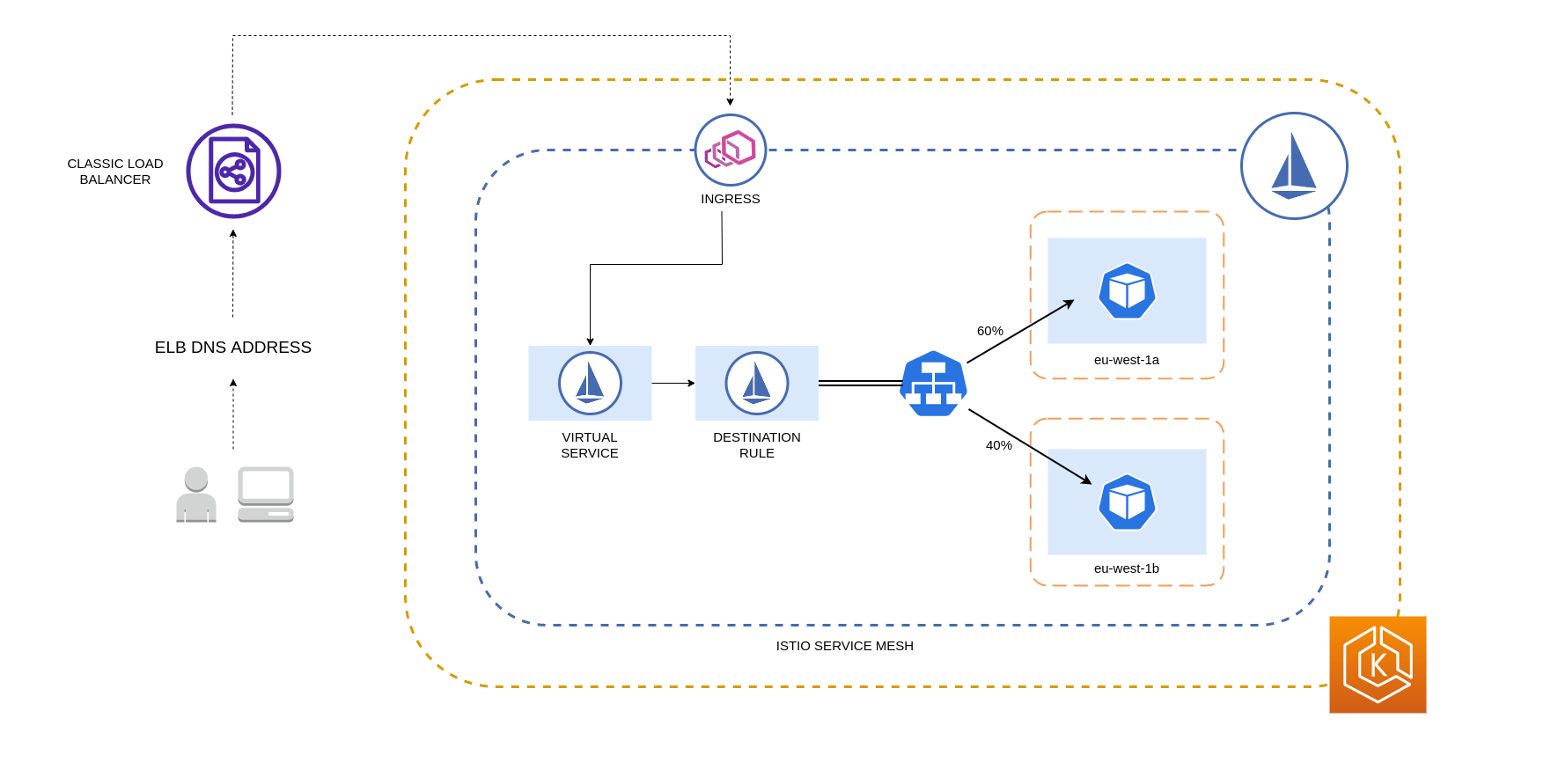
アベイラビリティーゾーンとノードへのトラフィックの制限
Istio での サービス内部トラフィックポリシーの使用
Pod 間の外部受信トラフィックと内部トラフィックに関連するネットワークコストを削減するために、Istio の送信先ルールと Kubernetes Service の内部トラフィックポリシーを組み合わせることができます。Istio 送信先ルールをサービス内部トラフィックポリシーと組み合わせる方法は、主に 3 つの要素によって異なります。
-
マイクロサービスの役割
-
マイクロサービス全体のネットワークトラフィックパターン
-
Kubernetes クラスタートポロジ全体にマイクロサービスをデプロイする方法
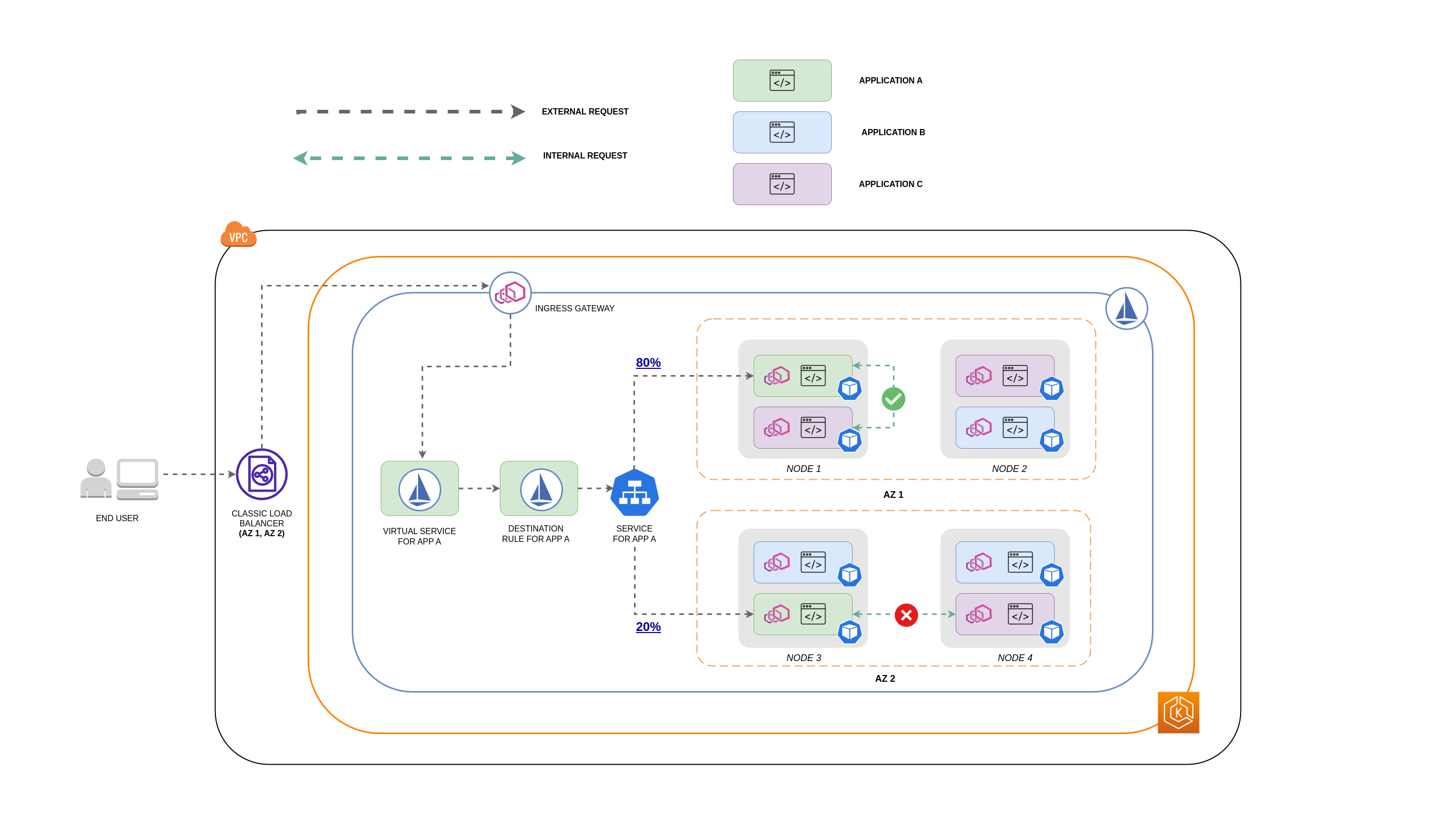
次の図は、ネストされたリクエストの場合のネットワークフローと、前述のポリシーがトラフィックをどのように制御するかを示しています。
-
エンドユーザーは APP A にリクエストを行い、APP C にネストされたリクエストを行います。 このリクエストは、最初に高可用性ロードバランサーに送信されます。このロードバランサーには、上記の図に示すように、AZ 1 と AZ 2 にインスタンスがあります。
-
その後、外部受信リクエストは Istio Virtual Service によって正しい宛先にルーティングされます。
-
リクエストがルーティングされると、Istio 送信先ルールは、送信元 (AZs 1 または AZ 2) に基づいて、各 AZ へのトラフィック量を制御します。
-
その後、トラフィックは APP A のサービスに送信され、それぞれの Pod エンドポイントにプロキシされます。図に示すように、着信トラフィックの 80% が AZ 1 の Pod エンドポイントに送信され、着信トラフィックの 20% が AZ 2 に送信されます。
-
その後、APP A は APP C に内部リクエストを行います。 APP C のサービスでは、内部トラフィックポリシーが有効になっています (
internalTrafficPolicy`: Local`)。 -
APP C のノードローカルエンドポイントが使用可能であるため、APP A (NODE 1) から APP C への内部リクエストは成功しました。
-
APP C に使用可能なノードローカルエンドポイントがないため、APP A (NODE 3) から APP C への内部リクエストは失敗します。 図に示すように、APP C には NODE 3 にレプリカがありません。 **
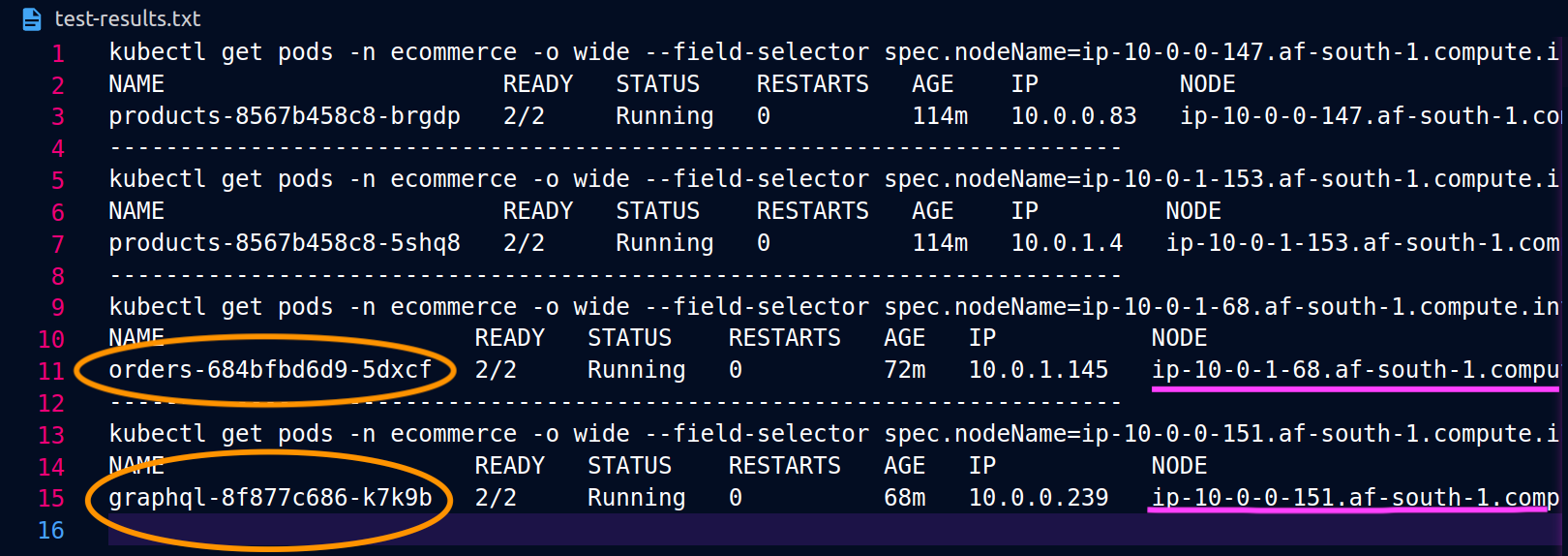
以下のスクリーンショットは、このアプローチのライブ例からキャプチャされています。最初のスクリーンショットのセットは、 への外部リクエストが成功graphqlし、 からノード 上の同じ場所にあるordersレプリカgraphqlへのネストされたリクエストが成功したことを示していますip-10-0-0-151.af-south-1.compute.internal。
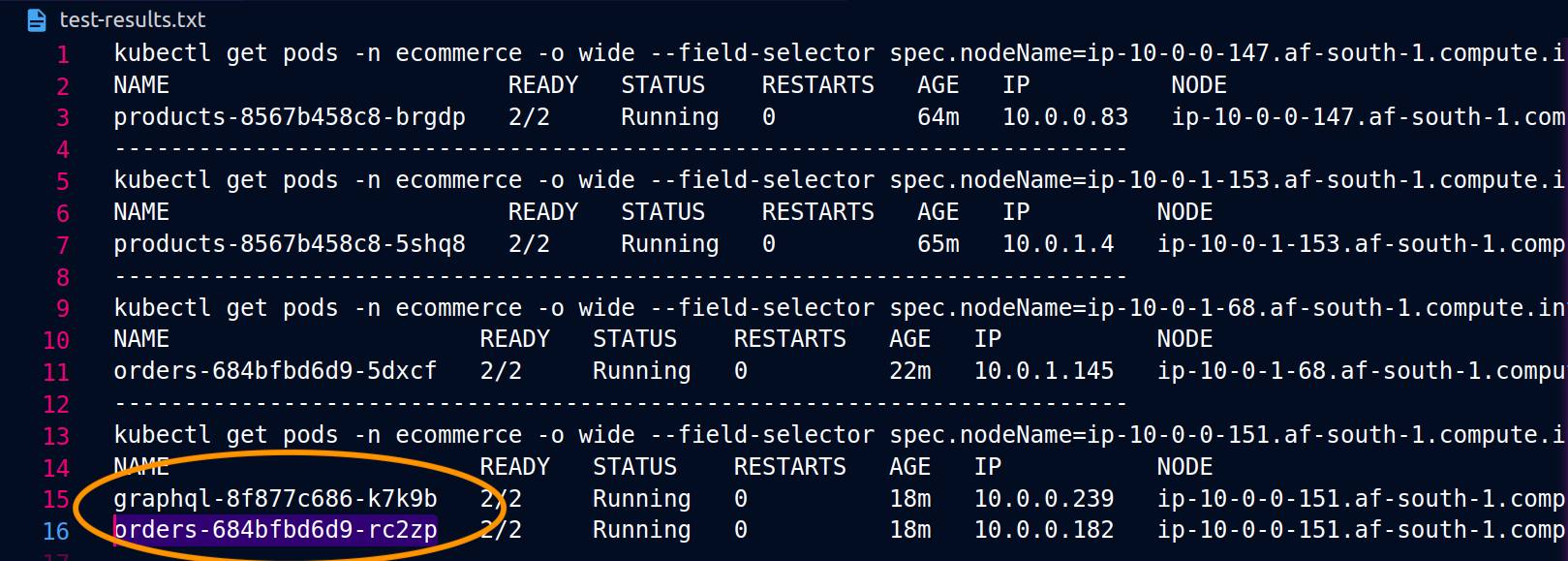
Istio を使用すると、プロキシが認識している [アップストリームクラスター](https://www.envoyproxy.io/docs/envoy/latest/intro/arch_overview/intro/terminologygraphqlプロキシが認識しているordersエンドポイントは、次のコマンドを使用して取得できます。
kubectl exec -it deploy/graphql -n ecommerce -c istio-proxy -- curl localhost:15000/clusters | grep orders
... orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_error::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_success::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_timeout::0** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**rq_total::119** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**health_flags::healthy** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**region::af-south-1** orders-service.ecommerce.svc.cluster.local::10.0.1.33:3003::**zone::af-south-1b** ...
この場合、graphqlプロキシはノードを共有するレプリカのordersエンドポイントのみを認識します。サービス注文から internalTrafficPolicy: Local設定を削除し、上記のようなコマンドを再実行すると、結果は異なるノードにまたがるレプリカのすべてのエンドポイントを返します。さらに、それぞれのエンドポイントrq_totalの を調べると、ネットワークディストリビューションのシェアが比較的均等であることがわかります。したがって、エンドポイントが異なる AZs で実行されているアップストリームサービスに関連付けられている場合、ゾーン間でのこのネットワーク分散によりコストが高くなります。
上記の前のセクションで説明したように、ポッドアフィニティを使用することで、頻繁に通信するポッドを共同配置できます。
... spec: ... template: metadata: labels: app: graphql role: api workload: ecommerce spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - orders topologyKey: "kubernetes.io/hostname" nodeSelector: managedBy: karpenter billing-team: ecommerce ...
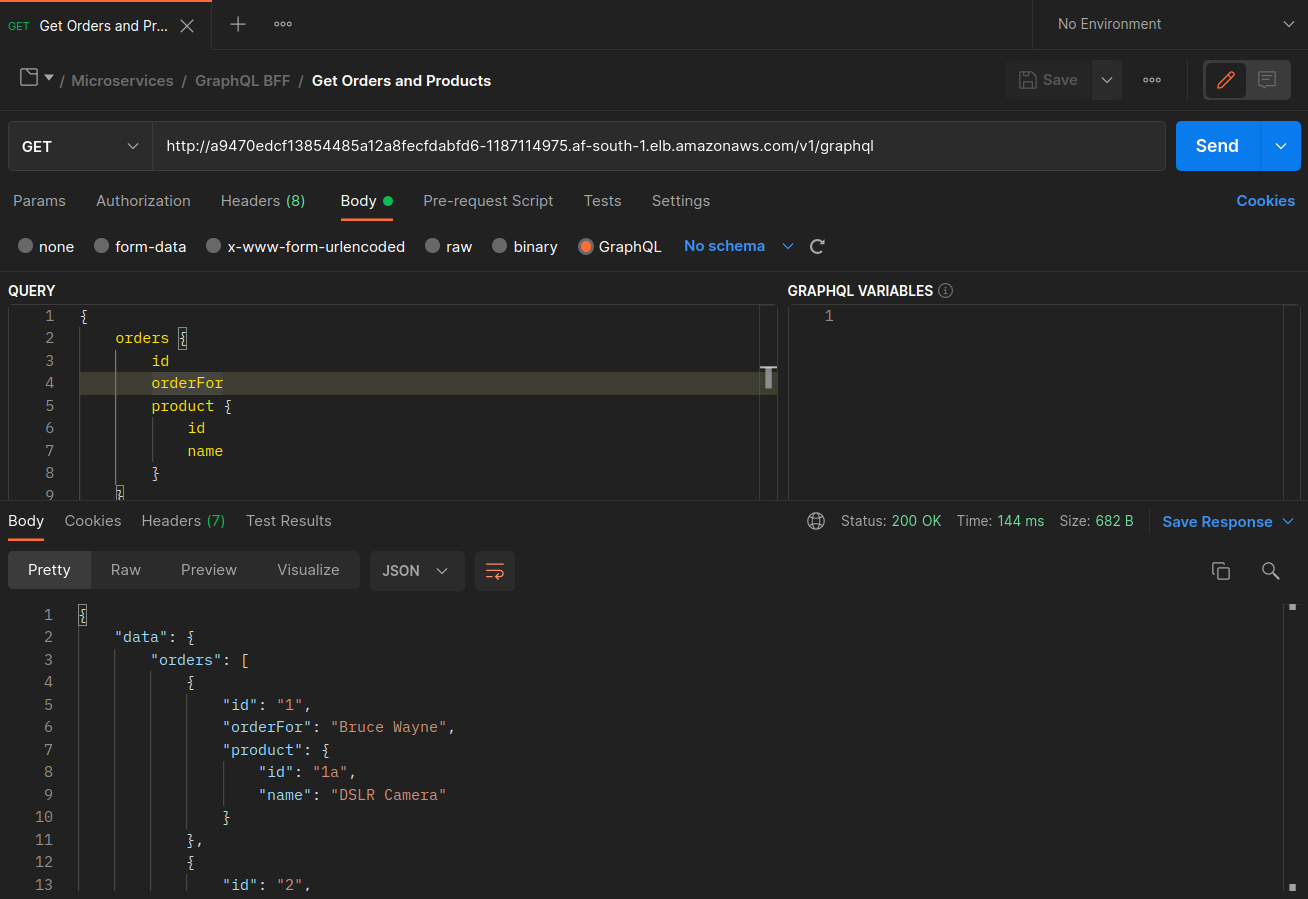
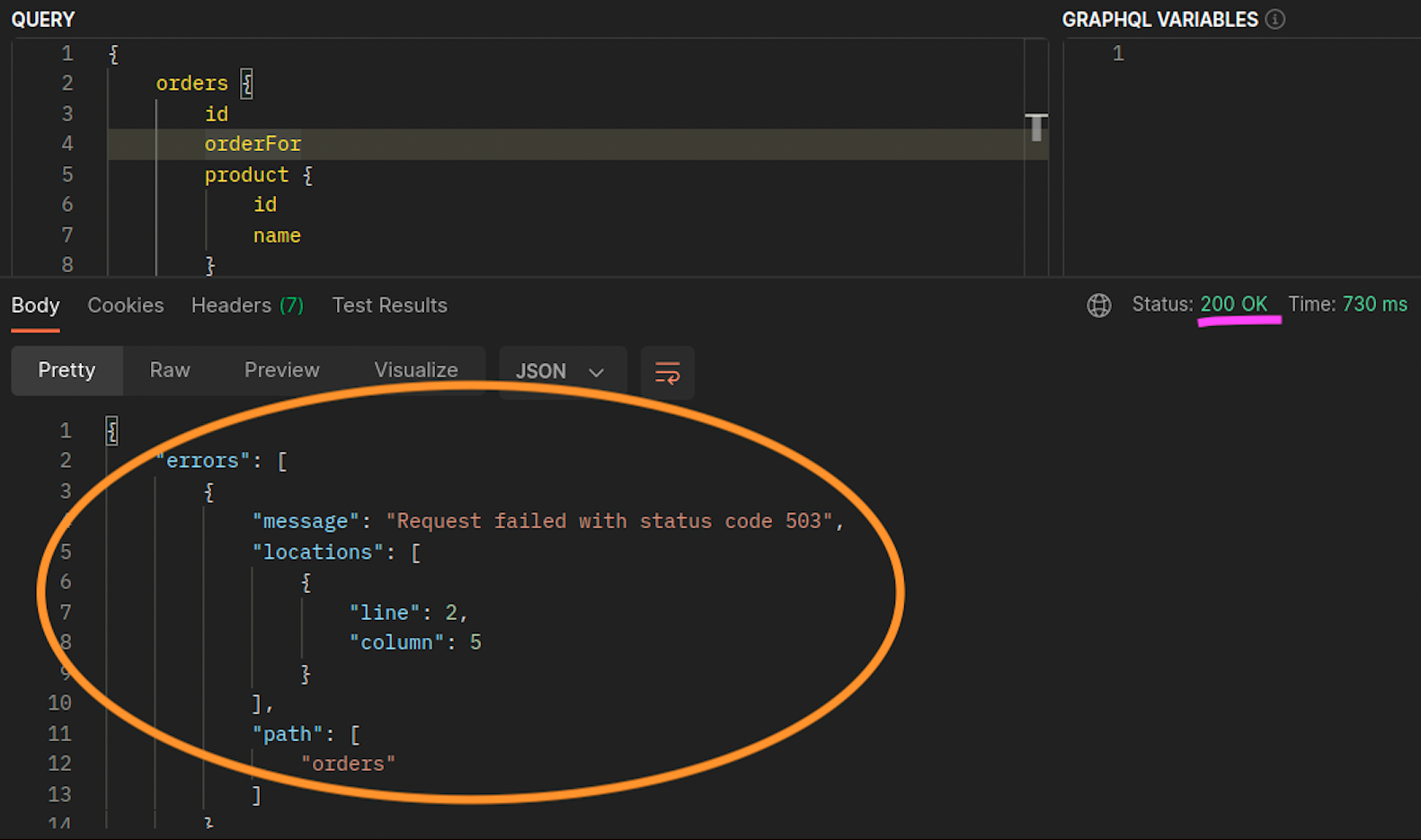
graphql と orders レプリカが同じノード (ip-10-0-0-151.af-south-1.compute.internal) に共存しない場合、 への最初のリクエストgraphqlは、以下の Postman スクリーンショット200 response codeの「」に記載されているように成功しますが、 から graphqlへのネストされた 2 番目のリクエストは でorders失敗します503 response code。
その他のリソース
