翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Kubernetes コントロールプレーン
Kubernetes コントロールプレーンは、Kubernetes API Server、Kubernetes Controller Manager、スケジューラ、および Kubernetes が機能するために必要なその他のコンポーネントで構成されます。これらのコンポーネントのスケーラビリティ制限は、クラスターで実行している内容によって異なりますが、スケーリングに最も影響がある領域には、Kubernetes のバージョン、使用率、個々のノードスケーリングが含まれます。
EKS 1.24 以降を使用する
EKS 1.24 は多くの変更を導入し、コンテナランタイムを docker ではなく containerd--container-runtimeブートストラップフラグを使用してください。
ワークロードとノードのバーストを制限する
重要
コントロールプレーンの API 制限に達しないようにするには、クラスターサイズを一度に 2 桁のパーセンテージで増やすスケーリングスパイクを制限する必要があります (たとえば、1000 ノードから 1100 ノード、4000 から 4500 ポッドに一度に増やすなど)。
EKS コントロールプレーンはクラスターが大きくなると自動的にスケールされますが、スケーリング速度には制限があります。EKS クラスターを初めて作成すると、コントロールプレーンはすぐに数百のノードまたは数千のポッドにスケールできなくなります。EKS によるスケーリングの改善の詳細については、このブログ記事
大規模なアプリケーションのスケーリングには、インフラストラクチャを完全に準備できるように適応させる必要があります (ロードバランサーのウォームなど)。スケーリングの速度を制御するには、アプリケーションに適したメトリクスに基づいてスケーリングしていることを確認してください。CPU とメモリのスケーリングでは、アプリケーションの制約を正確に予測できない場合があります。Kubernetes Horizontal Pod Autoscaler (HPA) でカスタムメトリクス (1 秒あたりのリクエスト数など) を使用すると、スケーリングオプションが適している可能性があります。
カスタムメトリクスを使用するには、Kubernetes ドキュメント
ノードとポッドを安全にスケールダウンする
長時間実行されているインスタンスを置き換える
ノードを定期的に置き換えることで、設定のドリフトや、長時間の稼働後にのみ発生する問題 (メモリリークの遅延など) を回避することで、クラスターを正常に保つことができます。自動交換は、ノードのアップグレードとセキュリティパッチ適用の適切なプロセスとプラクティスを提供します。クラスター内のすべてのノードが定期的に置き換えられる場合、継続的なメンテナンスのために個別のプロセスを維持するのに必要な労力が少なくなります。
Karpenter の有効期限 (TTL)max-instance-lifetime設定を使用してノードを自動的にサイクルできます。マネージド型ノードグループには現在この機能はありませんが、GitHub でリクエスト
使用率の低いノードを削除する
Kubernetes Cluster Autoscaler のスケールダウンしきい値を使用して実行中のワークロードがない場合、ノードを削除できます。--scale-down-utilization-thresholdttlSecondsAfterEmptyプロビジョナー設定を使用できます。
ポッドの中断予算と安全なノードのシャットダウンを使用する
Kubernetes クラスターからポッドとノードを削除するには、コントローラーが複数のリソース (EndpointSlices など) を更新する必要があります。これを頻繁に行うか、速すぎると、変更がコントローラーに伝達されるにつれて、API サーバーのスロットリングやアプリケーションの停止が発生する可能性があります。Pod Disruption Budgets
Kubectl の実行時にクライアント側のキャッシュを使用する
kubectl コマンドを非効率的に使用すると、Kubernetes API Server に追加の負荷がかかる可能性があります。kubectl を繰り返し使用するスクリプトやオートメーション (ループ用 など) を実行したり、ローカルキャッシュなしでコマンドを実行したりしないでください。
kubectl には、クラスターから検出情報をキャッシュして、必要な API コールの量を減らすクライアント側のキャッシュがあります。キャッシュはデフォルトで有効になっており、10 分ごとに更新されます。
コンテナから、またはクライアント側のキャッシュなしで kubectl を実行すると、API スロットリングの問題が発生する可能性があります。不要な API コールが発生しないように--cache-dir、 をマウントしてクラスターキャッシュを保持することをお勧めします。
kubectl 圧縮を無効にする
kubeconfig ファイルで kubectl 圧縮を無効にすると、API とクライアントの CPU 使用率が低下する可能性があります。デフォルトでは、サーバーはクライアントに送信されるデータを圧縮してネットワーク帯域幅を最適化します。これにより、すべてのリクエストに対してクライアントとサーバーに CPU 負荷がかかり、適切な帯域幅がある場合、圧縮を無効にするとオーバーヘッドとレイテンシーが軽減されます。圧縮を無効にするには、 --disable-compression=trueフラグを使用するか、kubeconfig ファイルdisable-compression: trueで を設定します。
apiVersion: v1
clusters:
- cluster:
server: serverURL
disable-compression: true
name: cluster
シャードクラスターオートスケーラー
Kubernetes Cluster Autoscaler は、最大 1000 ノードまでスケールアップするようにテストされています
ClusterAutoscaler-1
autoscalingGroups: - name: eks-core-node-grp-20220823190924690000000011-80c1660e-030d-476d-cb0d-d04d585a8fcb maxSize: 50 minSize: 2 - name: eks-data_m1-20220824130553925600000011-5ec167fa-ca93-8ca4-53a5-003e1ed8d306 maxSize: 450 minSize: 2 - name: eks-data_m2-20220824130733258600000015-aac167fb-8bf7-429d-d032-e195af4e25f5 maxSize: 450 minSize: 2 - name: eks-data_m3-20220824130553914900000003-18c167fa-ca7f-23c9-0fea-f9edefbda002 maxSize: 450 minSize: 2
ClusterAutoscaler-2
autoscalingGroups: - name: eks-data_m4-2022082413055392550000000f-5ec167fa-ca86-6b83-ae9d-1e07ade3e7c4 maxSize: 450 minSize: 2 - name: eks-data_m5-20220824130744542100000017-02c167fb-a1f7-3d9e-a583-43b4975c050c maxSize: 450 minSize: 2 - name: eks-data_m6-2022082413055392430000000d-9cc167fa-ca94-132a-04ad-e43166cef41f maxSize: 450 minSize: 2 - name: eks-data_m7-20220824130553921000000009-96c167fa-ca91-d767-0427-91c879ddf5af maxSize: 450 minSize: 2
API の優先度と公平性
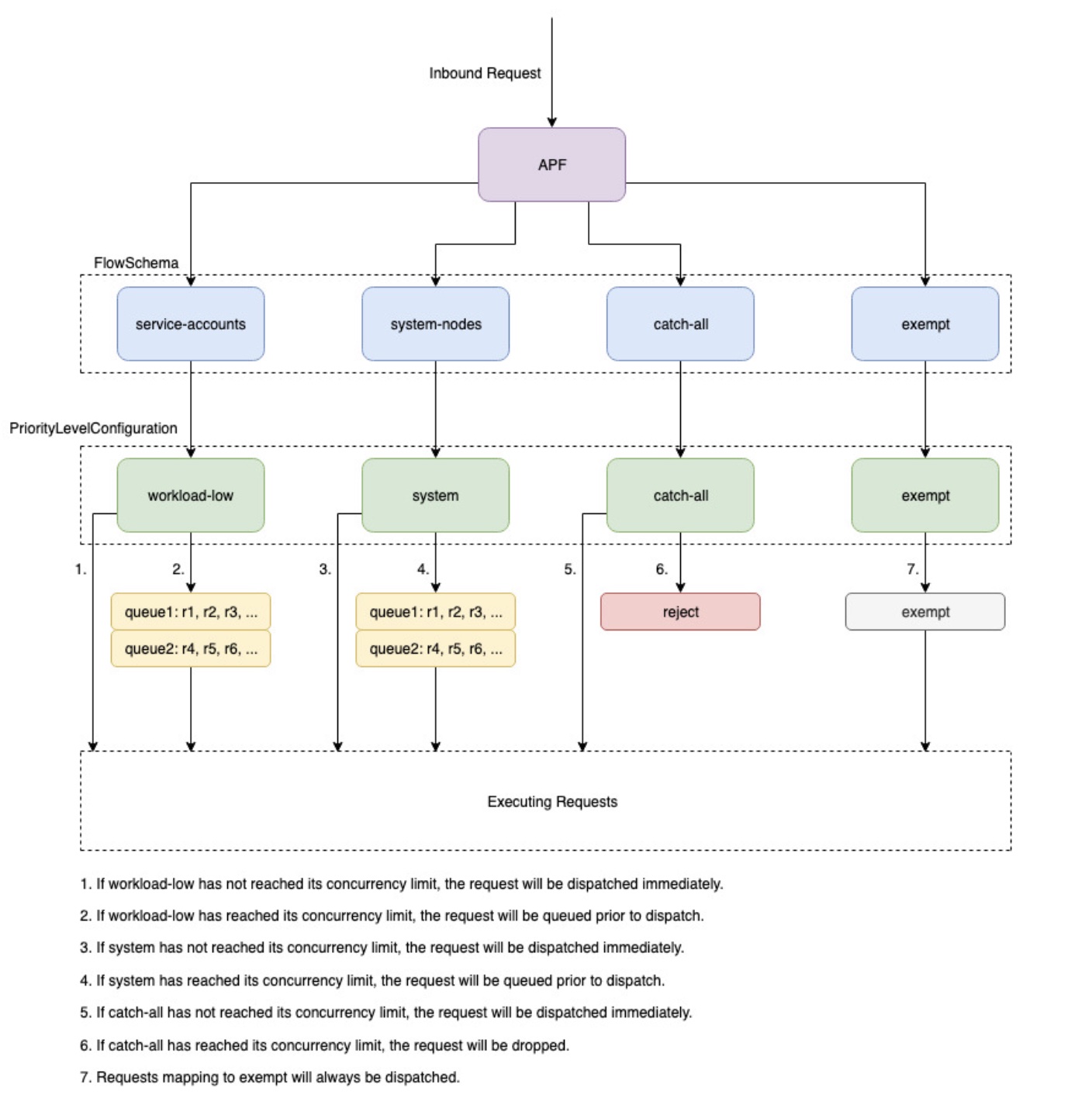
概要
リクエストが増加している間に自分自身が過負荷にならないように、API Server は、特定の時点で未処理の可能性がある処理中のリクエストの数を制限します。この制限を超えると、API Server はリクエストの拒否を開始し、「リクエストが多すぎます」の 429 HTTP レスポンスコードをクライアントに返します。サーバーがリクエストを削除し、後でクライアントに再試行させるのは、リクエスト数にサーバー側の制限を課さず、コントロールプレーンを過負荷にし、パフォーマンスが低下したり、使用不能になったりする可能性があるためです。
これらの処理中のリクエストをさまざまなリクエストタイプに分割する方法を設定するために Kubernetes が使用するメカニズムは、API Priority and Fairness--max-requests-inflightと --max-mutating-requests-inflightフラグで指定された値を合計することで、受け入れることができる処理中のリクエストの合計数を設定します。EKS では、これらのフラグに対してデフォルト値の 400 リクエストと 200 リクエストが使用され、一度に合計 600 リクエストをディスパッチできます。ただし、使用率とワークロードのチャーンの増加に応じてコントロールプレーンをより大きなサイズにスケールするため、それに応じて 2000 年までインフライトリクエストクォータが増加します (変更される可能性があります)。APF は、これらの処理中のリクエストクォータをさまざまなリクエストタイプにさらに分割する方法を指定します。EKS コントロールプレーンは、各クラスターに登録された少なくとも 2 つの API Server で高可用性であることに注意してください。つまり、クラスターが処理できる処理中のリクエストの総数は、kube-apiserver ごとに設定された処理中のクォータの 2 倍 (水平方向にスケールアウトしている場合はそれ以上) になります。これは、最大の EKS クラスターで 1 秒あたり数千のリクエストに相当します。
PriorityLevelConfigurations と FlowSchemas と呼ばれる 2 種類の Kubernetes オブジェクトは、リクエストの合計数を異なるリクエストタイプに分割する方法を設定します。これらのオブジェクトは API Server によって自動的に維持され、EKS は指定された Kubernetes マイナーバージョンのこれらのオブジェクトのデフォルト設定を使用します。PriorityLevelConfigurations は、許可されたリクエストの合計数の一部を表します。たとえば、ワークロードの高い PriorityLevelConfiguration には、合計 600 件のリクエストのうち 98 件が割り当てられます。すべての PriorityLevelConfigurations に割り当てられたリクエストの合計は 600 に等しくなります (または、特定のレベルにリクエストの一部が付与されると API サーバーが切り上げられるため、600 をわずかに上回ります)。クラスター内の PriorityLevelConfigurations と、それぞれに割り当てられたリクエストの数を確認するには、次のコマンドを実行します。EKS 1.24 のデフォルトは次のとおりです。
$ kubectl get --raw /metrics | grep apiserver_flowcontrol_request_concurrency_limit apiserver_flowcontrol_request_concurrency_limit{priority_level="catch-all"} 13 apiserver_flowcontrol_request_concurrency_limit{priority_level="global-default"} 49 apiserver_flowcontrol_request_concurrency_limit{priority_level="leader-election"} 25 apiserver_flowcontrol_request_concurrency_limit{priority_level="node-high"} 98 apiserver_flowcontrol_request_concurrency_limit{priority_level="system"} 74 apiserver_flowcontrol_request_concurrency_limit{priority_level="workload-high"} 98 apiserver_flowcontrol_request_concurrency_limit{priority_level="workload-low"} 245
オブジェクトの 2 番目のタイプは FlowSchemas です。特定のプロパティセットを持つ API サーバーリクエストは、同じ FlowSchema で分類されます。これらのプロパティには、認証されたユーザー、または API グループ、名前空間、リソースなどのリクエストの属性が含まれます。FlowSchema は、このタイプのリクエストをマッピングする PriorityLevelConfiguration も指定します。2 つのオブジェクトは、「このタイプのリクエストをこの処理中のリクエストのシェアにカウントします」と言います。リクエストが API サーバーに到達すると、必要なすべてのプロパティに一致するものが見つかるまで、各 FlowSchemas がチェックされます。複数の FlowSchemas がリクエストに一致する場合、API サーバーは一致する優先順位が最も小さい FlowSchema を選択します。この優先順位は オブジェクトのプロパティとして指定されます。
FlowSchemas と PriorityLevelConfigurations のマッピングは、次のコマンドを使用して表示できます。
$ kubectl get flowschemas NAME PRIORITYLEVEL MATCHINGPRECEDENCE DISTINGUISHERMETHOD AGE MISSINGPL exempt exempt 1 <none> 7h19m False eks-exempt exempt 2 <none> 7h19m False probes exempt 2 <none> 7h19m False system-leader-election leader-election 100 ByUser 7h19m False endpoint-controller workload-high 150 ByUser 7h19m False workload-leader-election leader-election 200 ByUser 7h19m False system-node-high node-high 400 ByUser 7h19m False system-nodes system 500 ByUser 7h19m False kube-controller-manager workload-high 800 ByNamespace 7h19m False kube-scheduler workload-high 800 ByNamespace 7h19m False kube-system-service-accounts workload-high 900 ByNamespace 7h19m False eks-workload-high workload-high 1000 ByUser 7h14m False service-accounts workload-low 9000 ByUser 7h19m False global-default global-default 9900 ByUser 7h19m False catch-all catch-all 10000 ByUser 7h19m False
PriorityLevelConfigurations には、キュー、拒否、または免除のタイプを指定できます。Queue 型と Reject 型では、その優先度レベルの処理中のリクエストの最大数に制限が適用されますが、その制限に達すると動作は異なります。たとえば、ワークロードの高い PriorityLevelConfiguration は Queue 型を使用し、コントローラーマネージャー、エンドポイントコントローラー、スケジューラ、eks 関連コントローラー、および kube-system 名前空間で実行されているポッドから 98 個のリクエストを使用できます。Queue 型が使用されるため、API Server はリクエストをメモリに保持しようとし、これらのリクエストがタイムアウトする前に処理中のリクエストの数が 98 を下回ることを期待します。特定のリクエストがキューでタイムアウトした場合、またはすでにキューに入れられているリクエストが多すぎる場合、API Server はリクエストを削除してクライアントに 429 を返します。キューイングによりリクエストが 429 を受信できなくなる場合がありますが、リクエストに対するend-to-endのレイテンシーの増加というトレードオフが伴います。
次に、タイプが Reject のキャッチオール PriorityLevelConfiguration にマッピングされるキャッチオール FlowSchema について考えます。クライアントが 13 件の処理中のリクエストの制限に達すると、API Server はキューイングを実行せず、429 レスポンスコードを使用してリクエストを即座に削除します。最後に、Exempt 型の PriorityLevelConfiguration へのマッピングリクエストは 429 を受け取ることはなく、常にすぐにディスパッチされます。これは、healthz リクエストや system:masters グループからのリクエストなど、優先度の高いリクエストに使用されます。
APF およびドロップされたリクエストのモニタリング
APF が原因でリクエストが削除されているかどうかを確認するために、 の API サーバーメトリクスapiserver_flowcontrol_rejected_requests_totalをモニタリングして、影響を受ける FlowSchemas と PriorityLevelConfigurations を確認できます。例えば、このメトリクスは、サービスアカウント FlowSchema からの 100 件のリクエストが、ワークロードの低いキューでリクエストがタイムアウトしたために削除されたことを示しています。
% kubectl get --raw /metrics | grep apiserver_flowcontrol_rejected_requests_total
apiserver_flowcontrol_rejected_requests_total{flow_schema="service-accounts",priority_level="workload-low",reason="time-out"} 100
PriorityLevelConfiguration が 429 秒の受信またはキューイングによるレイテンシーの増加にどれだけ近いかを確認するには、同時実行数の制限と使用中の同時実行数の差を比較できます。この例では、100 リクエストのバッファがあります。
% kubectl get --raw /metrics | grep 'apiserver_flowcontrol_request_concurrency_limit.*workload-low' apiserver_flowcontrol_request_concurrency_limit{priority_level="workload-low"} 245 % kubectl get --raw /metrics | grep 'apiserver_flowcontrol_request_concurrency_in_use.*workload-low' apiserver_flowcontrol_request_concurrency_in_use{flow_schema="service-accounts",priority_level="workload-low"} 145
特定の PriorityLevelConfiguration でキューイングが発生しているが、必ずしもリクエストが削除されていないかどうかを確認するには、 の メトリクスを参照apiserver_flowcontrol_current_inqueue_requestsできます。
% kubectl get --raw /metrics | grep 'apiserver_flowcontrol_current_inqueue_requests.*workload-low'
apiserver_flowcontrol_current_inqueue_requests{flow_schema="service-accounts",priority_level="workload-low"} 10
その他の便利な Prometheus メトリクスは次のとおりです。
-
apiserver_flowcontrol_dispatched_requests_total
-
apiserver_flowcontrol_request_execution_seconds
-
apiserver_flowcontrol_request_wait_duration_seconds
APF メトリクス
ドロップされたリクエストの防止
ワークロードを変更して 429 を防ぐ
特定の PriorityLevelConfiguration が許可される処理中のリクエストの最大数を超えたために APF がリクエストを削除している場合、影響を受ける FlowSchemas のクライアントは、特定の時間に実行されるリクエストの数を減らすことができます。これは、429 秒間に行われたリクエストの合計数を減らすことで実現できます。高価なリスト呼び出しなどの長時間実行されるリクエストは、実行中の全期間にわたって処理中のリクエストとしてカウントされるため、特に問題があることに注意してください。これらの高価なリクエストの数を減らしたり、これらのリスト呼び出しのレイテンシーを最適化したり (たとえば、リクエストごとにフェッチされるオブジェクトの数を減らしたり、監視リクエストを使用して に切り替えるなど)、特定のワークロードに必要な合計同時実行数を減らすことができます。
APF 設定を変更して 429 を防ぐ
警告
デフォルトの APF 設定を変更するのは、実行していることがわかっている場合のみです。APF 設定を誤って設定すると、API Server リクエストがドロップされ、ワークロードが大幅に中断される可能性があります。
リクエストの削除を防ぐもう 1 つの方法は、EKS クラスターにインストールされているデフォルトの FlowSchemas または PriorityLevelConfigurations を変更することです。EKS は、特定の Kubernetes マイナーバージョンの FlowSchemas と PriorityLevelConfigurations のアップストリームデフォルト設定をインストールします。API Server は、オブジェクトの次の注釈が false に設定されない限り、変更されると、これらのオブジェクトを自動的にデフォルトに調整します。
metadata:
annotations:
apf.kubernetes.io/autoupdate-spec: "false"
大まかに言うと、APF 設定は次のいずれかに変更できます。
-
関心のあるリクエストにより多くの処理中の容量を割り当てます。
-
他のリクエストタイプの容量を枯渇させる可能性のある、重要でないリクエストや高価なリクエストを分離します。
これは、デフォルトの FlowSchemas と PriorityLevelConfigurations を変更するか、これらのタイプの新しいオブジェクトを作成することによって実現できます。オペレーターは、関連する PriorityLevelConfigurations オブジェクトの assuredConcurrencyShares の値を増やして、割り当てられた処理中のリクエストの割合を増やすことができます。さらに、リクエストがディスパッチされる前にキューに入れられたことによる追加のレイテンシーをアプリケーションが処理できる場合、特定の時間にキューに入れることができるリクエストの数を増やすこともできます。
または、顧客のワークロードに固有の新しい FlowSchema オブジェクトと PriorityLevelConfigurations オブジェクトを作成することもできます。よりassuredConcurrencyShares を既存の PriorityLevelConfigurations または新しい PriorityLevelConfigurations に割り当てると、API Server ごとに全体的な制限が 600 インフライトのままになるため、他のバケットで処理できるリクエストの数が減少します。
APF のデフォルトを変更するときは、これらのメトリクスを非本番稼働用クラスターでモニタリングして、設定を変更しても意図しない 429 が発生しないようにする必要があります。
-
のすべての FlowSchemas の メトリクスをモニタリングして、バケットがリクエストの削除を開始しないように
apiserver_flowcontrol_rejected_requests_totalする必要があります。 -
apiserver_flowcontrol_request_concurrency_limitと の値を比較して、使用中の同時実行がその優先度レベルの制限を超過するリスクがないことを確認するapiserver_flowcontrol_request_concurrency_in_use必要があります。
新しい FlowSchema と PriorityLevelConfiguration を定義するための一般的なユースケースの 1 つは、分離用です。長時間実行されるリストイベント呼び出しをポッドから独自のリクエスト共有に分離するとします。これにより、既存のサービスアカウント FlowSchema を使用するポッドからの重要なリクエストが 429 を受信し、リクエスト容量が枯渇するのを防ぐことができます。処理中のリクエストの合計数は有限ですが、この例では、APF 設定を変更して特定のワークロードのリクエスト容量をより適切に分割できることを示しています。
リストイベントリクエストを分離する FlowSchema オブジェクトの例:
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: FlowSchema
metadata:
name: list-events-default-service-accounts
spec:
distinguisherMethod:
type: ByUser
matchingPrecedence: 8000
priorityLevelConfiguration:
name: catch-all
rules:
- resourceRules:
- apiGroups:
- '*'
namespaces:
- default
resources:
- events
verbs:
- list
subjects:
- kind: ServiceAccount
serviceAccount:
name: default
namespace: default
-
この FlowSchema は、デフォルトの名前空間のサービスアカウントによって行われたすべてのリストイベント呼び出しをキャプチャします。
-
一致する優先順位 8000 は、既存の service-accounts FlowSchema で使用される 9000 の値よりも小さいため、これらのリストイベント呼び出しは service-accounts ではなく list-events-default-service-accounts と一致します。
-
キャッチオール PriorityLevelConfiguration を使用して、これらのリクエストを分離しています。このバケットでは、これらの長時間実行されるリストイベント呼び出しで使用できる処理中のリクエストは 13 個のみです。ポッドは、13 を超えるリクエストを同時に発行しようとするとすぐに 429 を受信し始めます。
API サーバーでのリソースの取得
API サーバーから情報を取得することは、あらゆるサイズのクラスターで想定される動作です。クラスター内のリソースの数をスケールすると、リクエストの頻度とデータ量がすぐにコントロールプレーンのボトルネックになり、API のレイテンシーと遅延につながる可能性があります。レイテンシーの重要度によっては、注意しないと予期しないダウンタイムが発生します。
リクエストしている内容と、これらのタイプの問題を回避するための最初のステップの頻度を認識します。スケーリングのベストプラクティスに基づいてクエリの量を制限するガイダンスを次に示します。このセクションの提案は、最適なスケーリングが知られているオプションから順に提供されています。
共有インフォマーを使用する
Kubernetes API と統合するコントローラーとオートメーションを構築する場合、多くの場合、Kubernetes リソースから情報を取得する必要があります。これらのリソースを定期的にポーリングすると、API サーバーに大きな負荷がかかる可能性があります。
client-go ライブラリのインフォマー
コントローラーは、特に大規模なクラスターでは、ラベルやフィールドセレクタなしでクラスター全体のリソースをポーリングしないようにする必要があります。フィルタリングされていないポーリングごとに、クライアントによってフィルタリングされる API サーバーを介して etcd から送信される不要なデータが多数必要です。ラベルと名前空間に基づいてフィルタリングすることで、API サーバーがクライアントに送信されるリクエストとデータをフルフィルするために実行する必要がある作業の量を減らすことができます。
Kubernetes API の使用を最適化する
カスタムコントローラーまたはオートメーションを使用して Kubernetes API を呼び出す場合は、必要なリソースのみに呼び出しを制限することが重要です。制限がないと、API サーバーや etcd に不要な負荷が発生する可能性があります。
可能な限り watch 引数を使用することをお勧めします。引数がない場合、デフォルトの動作はオブジェクトを一覧表示することです。リストの代わりに watch を使用するには、 API リクエストの末尾?watch=trueに を追加できます。たとえば、ウォッチを使用してデフォルトの名前空間内のすべてのポッドを取得するには、次のようにします。
/api/v1/namespaces/default/pods?watch=true
オブジェクトを一覧表示する場合は、一覧表示するオブジェクトの範囲と返されるデータの量を制限する必要があります。リクエストに引limit=500数を追加することで、返されるデータを制限できます。fieldSelector 引数と/namespace/パスは、リストが必要に応じて絞り込まれていることを確認するのに役立ちます。たとえば、デフォルトの名前空間で実行中のポッドのみを一覧表示するには、次の API パスと引数を使用します。
/api/v1/namespaces/default/pods?fieldSelector=status.phase=Running&limit=500
または、 で実行されているすべてのポッドを一覧表示します。
/api/v1/pods?fieldSelector=status.phase=Running&limit=500
監視呼び出しやリストされたオブジェクトを制限するもう 1 つのオプションは、resourceVersionsKubernetes ドキュメントで参照できる resourceVersion 引数がないと、利用可能な最新バージョンが返されます。このバージョンでは、データベースの読み込みが最もコストが高く、最も遅い etcd クォーラム読み込みが必要になります。resourceVersion は、クエリしようとしているリソースによって異なり、 metadata.resourseVersionフィールドにあります。これは、単に通話を一覧表示するのではなく、ウォッチコールを使用する場合にも推奨されます。
API サーバーキャッシュから結果を返す特別な がresourceVersion=0利用可能です。これにより、 etcd 負荷を減らすことができますが、ページ分割はサポートされていません。
/api/v1/namespaces/default/pods?resourceVersion=0
resourceVersion を前述のリストまたはウォッチから受信した最新の既知の値に設定して watch を使用することをお勧めします。これは client-go で自動的に処理されます。ただし、他の言語で k8s クライアントを使用している場合は、再確認することをお勧めします。
/api/v1/namespaces/default/pods?watch=true&resourceVersion=362812295
引数なしで API を呼び出すと、API サーバーや etcd にとって最もリソースを大量に消費します。この呼び出しでは、ページ分割やスコープの制限なしですべての名前空間内のすべてのポッドを取得し、etcd からのクォーラム読み取りが必要になります。
/api/v1/pods
DaemonSet が群れを雷撃するのを防ぐ
DaemonSet は、すべての (または一部の) ノードがポッドのコピーを実行するようにします。ノードがクラスターに参加すると、daemonset-controller はそれらのノードのポッドを作成します。ノードがクラスターを離れると、それらのポッドはガベージコレクションされます。DaemonSet を削除すると、作成したポッドがクリーンアップされます。
DaemonSet の一般的な用途は次のとおりです。
-
すべてのノードでクラスターストレージデーモンを実行する
-
すべてのノードでログ収集デーモンを実行する
-
すべてのノードでノードモニタリングデーモンを実行する
数千のノードがあるクラスターでは、新しい DaemonSet の作成、DaemonSet の更新、ノード数の増加により、コントロールプレーンに高い負荷がかかる可能性があります。DaemonSet ポッドがポッドの起動時に高価な API サーバーリクエストを発行すると、多数の同時リクエストからコントロールプレーンで大量のリソースが使用される可能性があります。
通常のオペレーションでは、 を使用してRollingUpdate、新しい DaemonSet ポッドを段階的にロールアウトできます。RollingUpdate 更新戦略では、DaemonSet テンプレートを更新すると、コントローラーは古い DaemonSet ポッドを強制終了し、制御された方法で新しい DaemonSet ポッドを自動的に作成します。DaemonSet の最大 1 つのポッドは、更新プロセス全体で各ノードで実行されます。を 1、0、60 maxSurge maxUnavailableに設定することで、段階的なロールアウトを実行できますminReadySeconds。更新戦略を指定しない場合、Kubernetes はデフォルトで を 1、0、minReadySeconds0 maxSurge RollingUpdatemaxUnavailableとして作成します。
minReadySeconds: 60
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 0
maxUnavailable: 1
DaemonSet が既に作成されており、すべてのノードで予想される数のポッドがある場合、 は新しい DaemonSet Ready ポッドを段階的にロールアウトRollingUpdateします。群れの問題は、RollingUpdate戦略の対象ではない特定の条件下で発生する可能性があります。
DaemonSet の作成時に群れが雷鳴するのを防ぐ
デフォルトでは、RollingUpdate設定に関係なく、kube-controller-manager の daemonset-controller は、新しい DaemonSet を作成するときに、一致するすべてのノードのポッドを同時に作成します。DaemonSet の作成後にポッドを段階的にロールアウトするには、 NodeSelectorまたは を使用できますNodeAffinity。これにより、ゼロノードに一致する DaemonSet が作成され、ノードを徐々に更新してDaemonSet からポッドを制御されたレートで実行できるようになります。このアプローチに従うことができます。
-
のすべてのノードにラベルを追加します
run-daemonset=false。
kubectl label nodes --all run-daemonset=false
-
run-daemonset=falseラベルのないノードに一致するNodeAffinity設定で DaemonSet を作成します。これにより、最初は DaemonSet に対応するポッドがなくなります。
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: run-daemonset
operator: NotIn
values:
- "false"
-
制御されたレートでノードから
run-daemonset=falseラベルを削除します。この bash スクリプトを例として使用できます。
#!/bin/bash
nodes=$(kubectl get --raw "/api/v1/nodes" | jq -r '.items | .[].metadata.name')
for node in ${nodes[@]}; do
echo "Removing run-daemonset label from node $node"
kubectl label nodes $node run-daemonset-
sleep 5
done
-
必要に応じて、DaemonSet オブジェクトから
NodeAffinity設定を削除します。また、これにより がトリガーRollingUpdateされ、DaemonSet テンプレートが変更されたため、既存のすべての DaemonSet ポッドが徐々に置き換えられることに注意してください。
ノードスケールアウトで群れが雷鳴するのを防ぐ
DaemonSet の作成と同様に、新しいノードを高速で作成すると、多数の DaemonSet ポッドが同時に起動する可能性があります。コントローラーがこの同じレートで DaemonSet ポッドを作成できるように、制御されたレートで新しいノードを作成する必要があります。これが不可能な場合は、 を使用して、新しいノードを最初に既存の DaemonSet の対象外にすることができますNodeAffinity。次に、新しいノードにラベルを徐々に追加して、daemonset-controller が制御されたレートでポッドを作成できるようにします。このアプローチに従うことができます。
-
のすべての既存のノードにラベルを追加する
run-daemonset=true
kubectl label nodes --all run-daemonset=true
-
DaemonSet を、
run-daemonset=trueラベルを持つ任意のノードと一致するようにNodeAffinity設定で更新します。また、これにより がトリガーRollingUpdateされ、DaemonSet テンプレートが変更されたため、既存のすべての DaemonSet ポッドが徐々に置き換えられることに注意してください。次のステップに進む前にRollingUpdate、 が完了するまで待つ必要があります。
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: run-daemonset
operator: In
values:
- "true"
-
クラスターに新しいノードを作成します。これらのノードには
run-daemonset=trueラベルがないため、DaemonSet はそれらのノードと一致しないことに注意してください。 -
run-daemonset=trueラベルを新しいノード (現在run-daemonsetラベルがありません) に制御されたレートで追加します。この bash スクリプトを例として使用できます。
#!/bin/bash
nodes=$(kubectl get --raw "/api/v1/nodes?labelSelector=%21run-daemonset" | jq -r '.items | .[].metadata.name')
for node in ${nodes[@]}; do
echo "Adding run-daemonset=true label to node $node"
kubectl label nodes $node run-daemonset=true
sleep 5
done
-
必要に応じて、DaemonSet オブジェクトから
NodeAffinity設定を削除し、すべてのノードからrun-daemonsetラベルを削除します。
DaemonSet の更新で群れが雷鳴するのを防ぐ
RollingUpdate ポリシーは、 である DaemonSet ポッドmaxUnavailableの設定のみを尊重しますReady。DaemonSet にNotReadyポッドのみまたはNotReadyポッドの大部分があり、テンプレートを更新すると、daemonset-controller は任意のポッドに対して同時に新しいNotReadyポッドを作成します。これにより、NotReady大量のポッドがある場合に群れの問題が発生する可能性があります。たとえば、ポッドが継続的にクラッシュループしている場合や、イメージのプルに失敗している場合などです。
DaemonSet を更新したときにポッドを段階的にロールアウトするには、DaemonSet NotReady の更新戦略を から RollingUpdateに一時的に変更できますOnDelete。ではOnDelete、DaemonSet テンプレートを更新すると、コントローラーは古いポッドを手動で削除した後に新しいポッドを作成し、新しいポッドのロールアウトを制御できるようにします。このアプローチに従うことができます。
-
DaemonSet
NotReadyにポッドがあるかどうかを確認します。 -
そうでない場合は、DaemonSet テンプレートを安全に更新でき、
RollingUpdate戦略によって段階的なロールアウトが保証されます。 -
「はい」の場合は、まず
OnDelete戦略を使用するように DaemonSet を更新する必要があります。
updateStrategy: type: OnDelete
-
次に、必要な変更で DaemonSet テンプレートを更新します。
-
この更新後、管理されたレートでポッド削除リクエストを発行することで、古い DaemonSet ポッドを削除できます。この bash スクリプトは、kube-system 名前空間で DaemonSet 名が fluentd-elasticsearch である例として使用できます。
#!/bin/bash
daemonset_pods=$(kubectl get --raw "/api/v1/namespaces/kube-system/pods?labelSelector=name%3Dfluentd-elasticsearch" | jq -r '.items | .[].metadata.name')
for pod in ${daemonset_pods[@]}; do
echo "Deleting pod $pod"
kubectl delete pod $pod -n kube-system
sleep 5
done
-
最後に、DaemonSet を以前の
RollingUpdate戦略に更新できます。
