翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon EMR on EC2 – カスタムメトリクスとログを使用した CloudWatch による拡張モニタリング
概要
Amazon EMR は、強力で費用対効果の高いビッグデータ処理機能を提供します。パフォーマンスとリソース使用率を最大化するには、効果的なモニタリングが不可欠です。Amazon CloudWatch は EMR クラスターの包括的なオブザーバビリティを提供するため、メトリクスとログをリアルタイムで追跡できます。このドキュメントでは、以下の方法について説明します。
-
EC2 ログで EMR を CloudWatch に送信するように CloudWatch エージェントを設定する
-
分類を通じてカスタム Hadoop、YARN、および HBase メトリクスを追加する
-
組み込みダッシュボードを使用してメトリクスをモニタリングする
-
CloudWatch ロググループを介してクラスターログを追跡する
前提条件と背景
デフォルトでは、Amazon EMR は基本メトリクスを追加コストなしで 5 分ごとに CloudWatch に送信します。EMR リリース 7.0 以降では、CloudWatch エージェントを次の場所にデプロイできます。
-
1 分間隔で 34 個の詳細なメトリクスを収集します (追加料金が適用されます)
-
すべてのクラスターノードからメトリクスを収集する
-
CloudWatch に送信する前にプライマリノードでデータを集約する
-
EMR コンソールのモニタリングタブまたは CloudWatch コンソールからメトリクスにアクセスする
EMR 7.1 はこれらの機能を拡張し、Hadoop、YARN、HBase コンポーネントから特殊なメトリクスをキャプチャするようにエージェントを設定できます。Prometheus を使用する環境では、メトリクスを Amazon Managed Service for Prometheus に転送できます。
ログの CloudWatch エージェント設定
CloudWatch で EMR ログをキャプチャするには、収集するログファイルを定義する cloudwatch-config.json ファイルを作成します。
cloudwatch-config.json
{ "agent": {"metrics_collection_interval":60,"logfile":"/var/log/emr-cluster-metrics/amazon-cloudwatch-agent/amazon-cloudwatch-agent.log","run_as_user":"****","omit_hostname":true}, "logs": { "logs_collected": { "files": { "collect_list": [ { "file_path": "/mnt/var/log/hadoop-yarn/hadoop-yarn-resourcemanager-*", "log_group_name": "/emr/yarn/resourcemnger", "log_stream_name": "{instance_id}", "publish_multi_logs" : true }, { "file_path": "/var/log/hadoop-hdfs/hadoop-hdfs-namenode-*", "log_group_name": "/emr/hdfs/namenode", "log_stream_name": "{instance_id}", "publish_multi_logs" : true } ] } } } }
CloudWatch エージェント設定のブートストラップスクリプト
カスタム CloudWatch 設定を EMR ノードに適用するには、設定を使用して CloudWatch エージェントを再起動するブートストラップスクリプトを作成します。このスクリプトにより、クラスターのプロビジョニング後にエージェントが特定のログ収集パラメータで実行されるようになります。
ブートストラップスクリプトの作成
次の内容で cloudwatch-agent-bootstrap.sh という名前のファイルを作成します。
#!/bin/bash set -xe EMR_SECONDARY_BA_SCRIPT=$(cat << 'EOF' while true; do NODEPROVISIONSTATE=$(sed -n '/localInstance [{]/,/[}]/ {/nodeProvisionCheckinRecord [{]/,/[}]/ {/status:/ p}}' /emr/instance-controller/lib/info/job-flow-state.txt | awk '{ print $2 }') if [ "$NODEPROVISIONSTATE" == "SUCCESSFUL" ]; then sleep 10 echo "Running my post provision bootstrap" NODETYPE=$(cat /mnt/var/lib/instance-controller/extraInstanceData.json | jq -r '.instanceRole' | awk '{print tolower($0)}') # Copy config file on the instance sudo aws s3 cp s3://amzn-s3-demo-bucket1>/cloudwatch-config.json /etc/emr-cluster-metrics/amazon-cloudwatch-agent/conf/emr-amazon-cloudwatch-agent.json # Stop the current agent sudo /usr/bin/amazon-cloudwatch-agent-ctl -a stop # Start the agent with the created config file sudo /usr/bin/amazon-cloudwatch-agent-ctl -a fetch-config -s -m ec2 -c file:/etc/emr-cluster-metrics/amazon-cloudwatch-agent/conf/emr-amazon-cloudwatch-agent.json # Status CW Agent echo "Status CW Agent" sudo /usr/bin/amazon-cloudwatch-agent-ctl -m ec2 -a status exit fi sleep 10 done EOF ) echo "${EMR_SECONDARY_BA_SCRIPT}" | tee -a /tmp/emr-secondary-ba.sh chmod u+x /tmp/emr-secondary-ba.sh /tmp/emr-secondary-ba.sh > /tmp/emr-secondary-ba.log 2>&1 & exit 0
重要な設定に関する注意事項
重要
スクリプトをアップロードする前に、 を、前のステップで cloudwatch-config.json ファイルを保存した S3 バケットの実際の名前<amzn-s3-demo-bucket1>に置き換えます。これにより、ブートストラップスクリプトはクラスターの初期化中に設定ファイルを取得できます。
このブートストラップスクリプトは次のようになります。
-
ノードのプロビジョニングが完了するまで待機する
-
カスタム CloudWatch 設定をダウンロードする
-
実行中の CloudWatch エージェントを停止する
-
特定の設定でエージェントを再起動する
-
トラブルシューティングのためにエージェントのステータスをログに記録する
Hadoop、YARN、HBase のカスタムメトリクス分類
デフォルトの CloudWatch メトリクスに加えて、EMR クラスターコンポーネントのカスタムアプリケーション固有のメトリクスを設定することで、モニタリング機能を強化できます。Amazon EMR の設定 API は、収集するメトリクスを正確に定義するための柔軟な方法を提供します。
カスタムメトリクスの設定
カスタムメトリクスコレクションは、次の 2 つの方法で実装できます。
-
新しいクラスターのクラスター作成中
-
EMR コンソールを使用した既存のクラスターの再設定として
分類ファイルの作成
分類ファイルは、クラスターから収集する特定のコンポーネントメトリクスを定義します。以下は、カスタム Hadoop メトリクスを収集するためのサンプル構造です。
[ { "Classification": "emr-metrics", "Configurations": [ { "Classification": "emr-hadoop-hdfs-datanode-metrics", "Properties": { "Hadoop:service=DataNode,name=DataNodeActivity-*": "DatanodeNetworkErrors,TotalReadTime,TotalWriteTime,BytesRead,BytesWritten,RemoteBytesRead,RemoteBytesWritten,ReadBlockOpNumOps,ReadBlockOpAvgTime,WriteBlockOpNumOps,WriteBlockOpAvgTime", "otel.metric.export.interval": "30000" } }, { "Classification": "emr-hadoop-yarn-nodemanager-metrics", "Properties": { "Hadoop:service=NodeManager,name=JvmMetrics": "MemNonHeapUsedM,MemNonHeapCommittedM,MemNonHeapMaxM,MemHeapUsedM,MemHeapCommittedM,MemHeapMaxM,MemMaxM", "Hadoop:service=NodeManager,name=NodeManagerMetrics": "ContainerCpuUtilization,NodeCpuUtilization,ContainersCompleted,ContainersFailed,ContainersKilled,ContainersLaunched,ContainersRolledBackOnFailure,ContainersRunning,ContainerUsedMemGB,ContainerUsedVMemGB,ContainerLaunchDurationNumOps,ContainerLaunchDurationAvgTime", "otel.metric.export.interval": "20000" } } ], "Properties": {} } ]
実装手順
-
目的のメトリクス分類を使用して JSON ファイルを作成します。
-
モニタリング要件に基づいてメトリクスをカスタマイズします。
-
ファイルを保存し、S3 バケットにアップロードします。
-
新しいクラスターを作成するとき、または既存のクラスターを再設定するときは、このファイルを参照してください。
ベストプラクティス
-
ワークロードに有意義なインサイトを提供するメトリクスのみを収集します。
-
モニタリングニーズに基づいてメトリクス収集間隔を検討してください。
-
各コンポーネントの使用可能なメトリクスの完全なリストについては、 AWS ドキュメントを参照してください。
-
より良い組織のために、関連するメトリクスを同じ分類内にグループ化します。
このアプローチにより、特定の EMR アプリケーションの最も重要なメトリクスにモニタリングを集中させ、クラスターのパフォーマンスをより詳細に可視化できます。
CloudWatch 統合を使用した EMR クラスターのデプロイ
ログとカスタムメトリクスを CloudWatch に自動的に送信する Amazon EMR クラスターを作成するには、次の手順に従います。
ステップ 1: CloudWatch エージェントを有効にする
AWS マネジメントコンソールを使用して EMR クラスターを作成する場合:
-
クラスターの作成時に アプリケーション セクションに移動します。
-
プライマリアプリケーション (Hadoop、Spark など) のチェックボックスをオンにします。
-
スクロールして Amazon CloudWatch Agent オプションを見つけて選択します。
-
これにより、クラスター上のエージェントが有効になります。これは、拡張メトリクスとログの収集に不可欠です。
CloudWatch エージェントはクラスター内のすべてのノードにインストールされるため、設定された間隔でシステムおよびアプリケーションのメトリクスを収集できます。
名前とアプリケーション
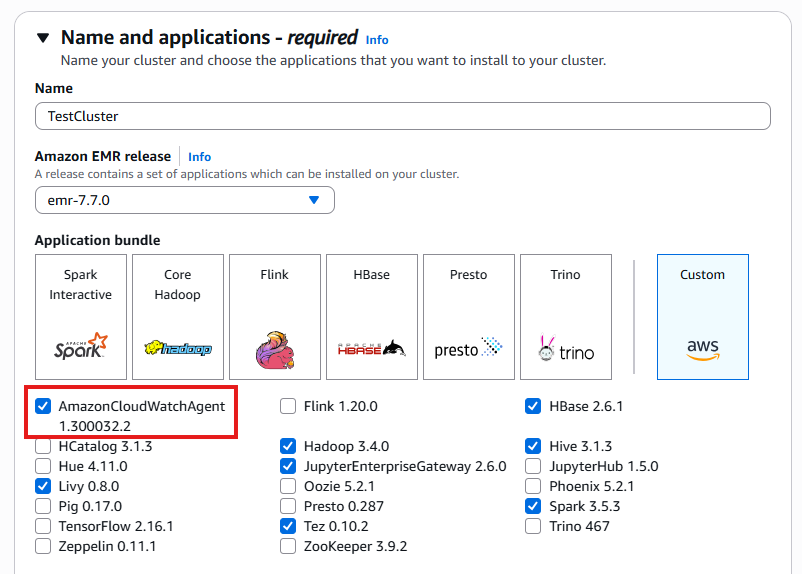
クラスターを作成し、使用可能なバンドルを表示します。
注記
CloudWatch エージェントは、EMR リリース 7.0 以降で使用できます。このコンポーネントを有効にすることは、このガイドで説明されているカスタムメトリクスの収集とログ転送に必要です。
ステップ 2: ログ収集にブートストラップアクションを追加する
特定のログファイルを収集して CloudWatch に転送するように CloudWatch エージェントを設定するには:
-
EMR クラスター作成ウィザードで、ブートストラップアクションセクションに移動します。
-
ブートストラップアクションの追加をクリックします。
-
ドロップダウンメニューからカスタムアクションを選択する
-
ブートストラップアクションの名前を指定する (例: CloudWatch エージェントを設定する)
-
スクリプトの場所フィールドに、cloudwatch-agent-bootstrap.sh スクリプトへの S3 パスを入力します (例: s3://your-bucket-name/cloudwatch-agent-bootstrap.sh)。
-
追加をクリックしてブートストラップアクションを保存します
このブートストラップアクションはクラスターの起動時に実行され、CloudWatchagent がカスタム設定で適切に設定され、設定ファイルで指定されたログファイルが収集および転送されます。
エージェントは、ノードがプロビジョニングされると自動的にログの収集を開始し、CloudWatch Logs を通じてクラスターオペレーションをほぼリアルタイムで可視化します。
ブートストラップアクション
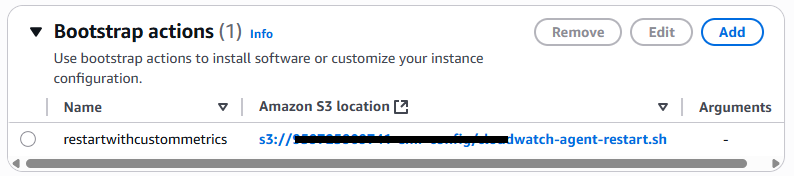
ブートストラップアクションの使用。
ステップ 3: カスタムメトリクス収集を設定する
デフォルトセットを超えるカスタム Hadoop、YARN、または HBase メトリクスの収集を有効にするには:
-
EMR クラスター作成ウィザードで、設定セクションに移動します。
-
設定の編集ボタンをクリックして、設定オプションを展開します。
-
設定方法ドロップダウンから Amazon S3 から JSON をロード オプションを選択します。
-
カスタムメトリクス分類ファイルへの S3 URI パスを入力します (例: s3://amzn-s3-demo-bucket1/emr-metrics-classification.json)。
-
Load をクリックして設定を解析します。
-
コンソールインターフェイスで設定が正しく表示されることを確認します。
-
変更を保存をクリックして、これらのメトリクス設定をクラスターに適用します。
このステップでは、分類ファイルで定義された特定のコンポーネントメトリクスを収集するように CloudWatch エージェントに指示します。メトリクスは、設定で指定された間隔で収集され、CloudWatch に公開されます。CloudWatch では、メトリクスを視覚化して分析できます。
カスタムメトリクスは、クラスターのパフォーマンス特性に関するより深いインサイトを提供し、EMR アプリケーションのより正確なモニタリングとトラブルシューティングを可能にします。
ソフトウェアの設定
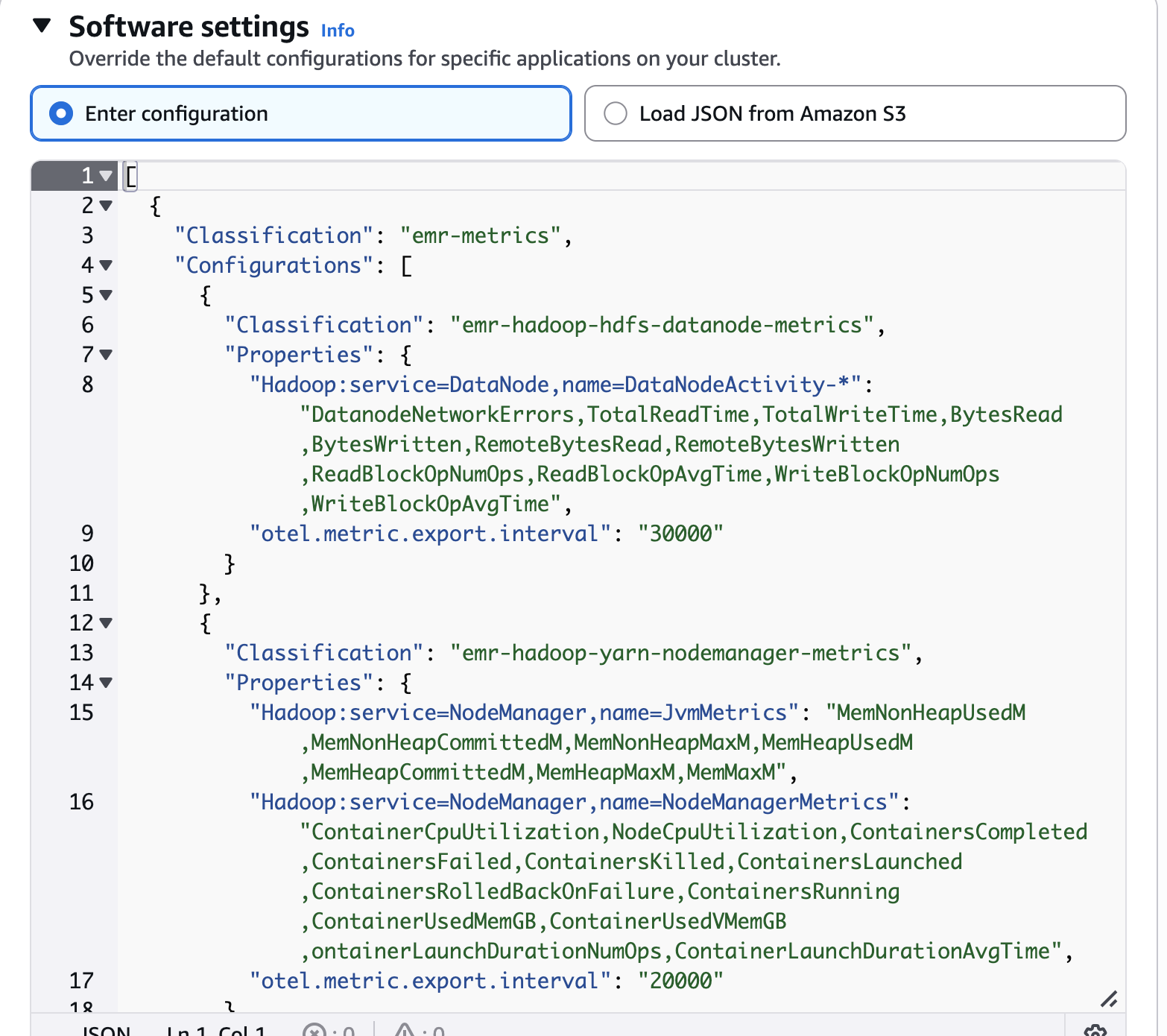
デフォルト設定を上書きします。
クラスターを実行するためのメトリクス設定の更新
以下の手順に従って、オペレーションを中断することなく、既存の EMR クラスターのメトリクス収集設定を変更できます。
-
AWS マネジメントコンソールでアクティブな EMR クラスターに移動します。
-
クラスターの詳細ビューで設定タブを選択します。
-
インスタンスグループ設定セクションを見つけます。
-
再設定ボタンをクリックして設定を変更します。
-
Amazon S3 から JSON をロード を選択するか、設定を直接編集します。
-
更新されたメトリクス分類ファイルの場所を入力するか、エディタで変更を加えます。
-
メトリクス収集の動作を更新するには、変更を適用します。
この再設定機能により、ワークロード要件の進化に合わせてモニタリングアプローチを微調整できます。CloudWatch エージェントは新しい設定に自動的に適応し、クラスターの再起動やダウンタイムを必要とせずに、更新されたメトリクスのセットを収集します。
重要
設定の変更がクラスター内のすべてのノードに伝播されるまでに数分かかる場合があります。CloudWatch ダッシュボードのモニタリングを継続し、新しいメトリクスが期待どおりに表示されることを確認します。
クラスター設定
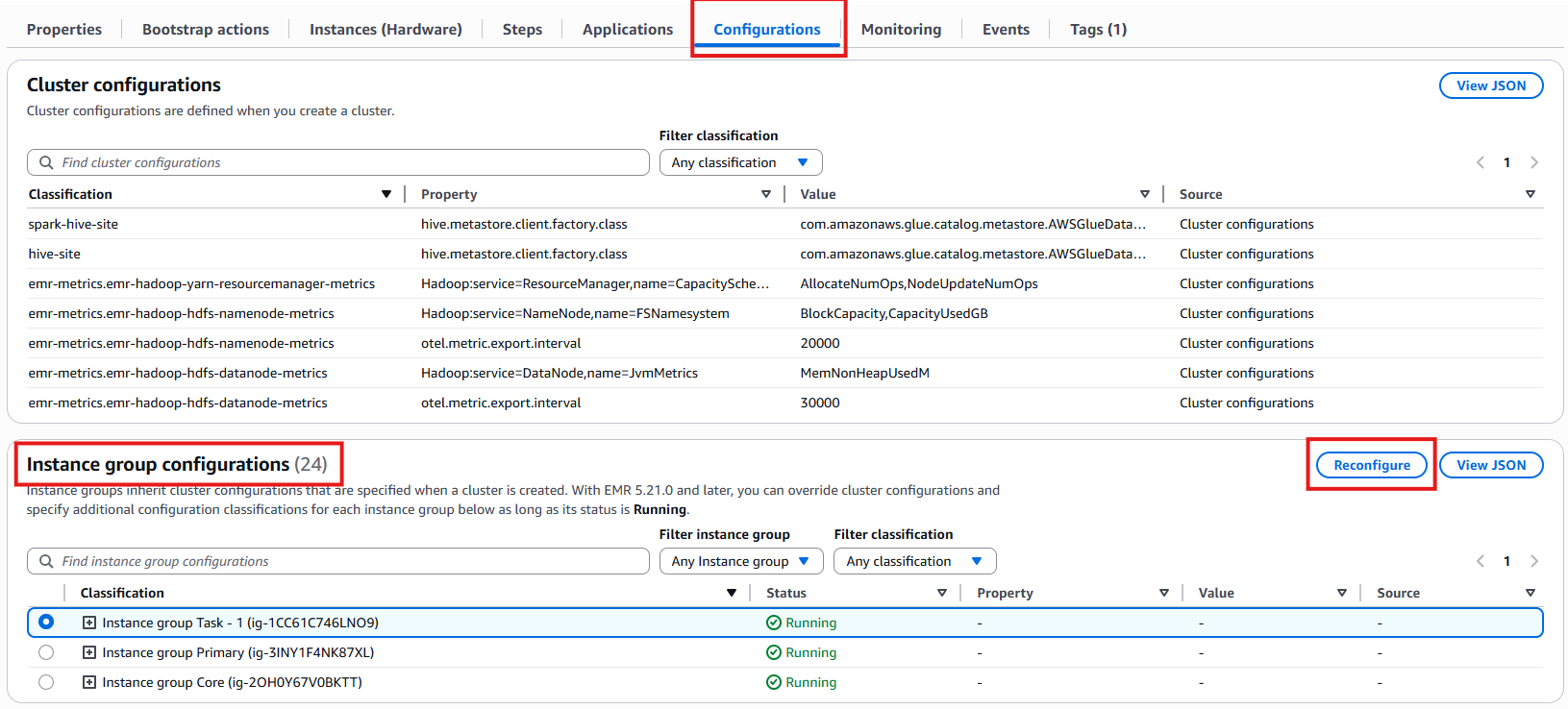
インスタンスグループ設定。
CloudWatch 統合の検証
設定ステップを完了したら、モニタリング設定が正しく動作していることを確認します。
ステップ 1: EMR クラスターをデプロイする
-
すべての設定が正しいことを確認します。
-
ブートストラップアクションと分類ファイルが正しく参照されていることを確認します。
-
クラスターの作成をクリックして EMR 環境を起動します。
-
クラスターが実行中状態になるまで待ちます (通常は 5~15 分)。
ステップ 2: テストアプリケーションを実行する
いくつかのテスト Spark アプリケーションを送信して、意味のあるメトリクスを生成します。
-
サンプルデータを処理するシンプルな Spark ジョブを実行します。
-
長時間実行される分析タスクを実行して、リソース使用率を監視します。
-
さまざまなアプリケーション設定をテストして、パフォーマンスメトリクスを比較します。
アプリケーションが完了した後 (または実行中)。
-
[CloudWatch console] (CloudWatch のコンソール) に移動する。
-
設定されたロググループでアプリケーションログを確認します。
-
メトリクスダッシュボードを調べて、CPU、メモリ、アプリケーション固有のメトリクスを確認します。
-
分類ファイルで定義されたカスタムメトリクスが CloudWatch に表示されることを確認します。
この検証プロセスにより、CloudWatch 統合がログとメトリクスの両方を適切にキャプチャしていることが確認され、EMR クラスターのパフォーマンスとアプリケーションの動作を包括的に可視化できます。
CloudWatch Log Groups での EMR ログへのアクセス
EMR クラスターが実行され、CloudWatch エージェントが適切に設定されると、アプリケーションとシステムログが CloudWatch Logs で利用可能になります。にアクセスして分析するには、次の手順に従います。
ロググループの表示
-
AWS マネジメントコンソールの CloudWatch コンソールに移動します。
-
左側のナビゲーションペインからロググループを選択します。
-
次のような設定によって作成されたロググループを探します。
-
YARN ResourceManager ログの /emr/yarn/resourcemnger。
-
HDFS NameNode ログの /emr/hdfs/namenode。
-
設定ファイルで指定された追加のロググループ。
-
各ロググループには、インスタンス ID 別に整理されたログストリームが含まれており、クラスター内の特定のノードへのログを追跡できます。
ログデータの使用
-
ログデータの検索: CloudWatch Logs Insights を使用して、ロググループ全体で構造化クエリを実行します。
-
メトリクスの作成: ログパターンからメトリクスを抽出して、カスタム CloudWatch メトリクスを作成します。
-
アラートの設定: 特定のエラーパターンまたはログの頻度に基づいてアラームを設定します。
-
ログのエクスポート: オフライン分析またはアーカイブ用のログをダウンロードします。
ログの保持
注記
デフォルトでは、ログは 30 日間保持されます。コンプライアンスまたは分析の目的で必要な場合は、各ロググループの保持ポリシーを変更して、ログをより長期間保持できます。
CloudWatch Logs は、すべての EMR ログデータの一元的な場所を提供するため、個々のクラスターノードに SSH 接続して問題のトラブルシューティングやアプリケーションの動作の分析を行う必要がなくなります。
EMR モニタリングダッシュボードでのカスタムメトリクスの表示
EMR クラスターが CloudWatch エージェントとカスタムメトリクス設定で実行されたら、EMR コンソールでこれらのメトリクスを直接簡単にモニタリングできます。
カスタムメトリクスへのアクセス
-
AWS マネジメントコンソールで EMR クラスターに移動します。
-
クラスターの詳細ページでモニタリングタブを選択します。
-
モニタリングダッシュボードの上部近くにあるフィルターメトリクス分類ドロップダウンを見つけます。
-
このフィルターを使用して、特定のメトリクスカテゴリを選択します。
-
HDFS を選択して NameNode メトリクスと DataNode メトリクスを表示します。
-
YARN を選択すると、ResourceManager とコンテナメトリクスが表示されます。
-
HBase 固有のパフォーマンスデータには HBase を選択します。
-
定義したカスタムメトリクス分類を選択します。
-
ダッシュボードは動的に更新され、選択したメトリクスのグラフが表示され、時間の経過に伴うパフォーマンスの傾向が表示されます。
メトリクスの視覚化の使用
-
時間範囲の調整: 時間枠を変更して、最近のアクティビティまたは過去の傾向を表示します。
-
メトリクスの比較: 相関分析のために複数の関連メトリクスside-by-side表示します。
-
ズーム機能: 異常やパターンが表示される特定の期間に焦点を当てます。
-
データの更新: ほぼリアルタイムで最新のメトリクスデータで視覚化を更新します。
この統合モニタリングアプローチにより、標準 EMR メトリクスとカスタムメトリクスの両方を統合ダッシュボードで追跡できるため、EMR コンソールを離れることなく、パフォーマンスの問題、リソースの制約、またはアプリケーションのボトルネックを簡単に特定できます。
CloudWatch メトリクス
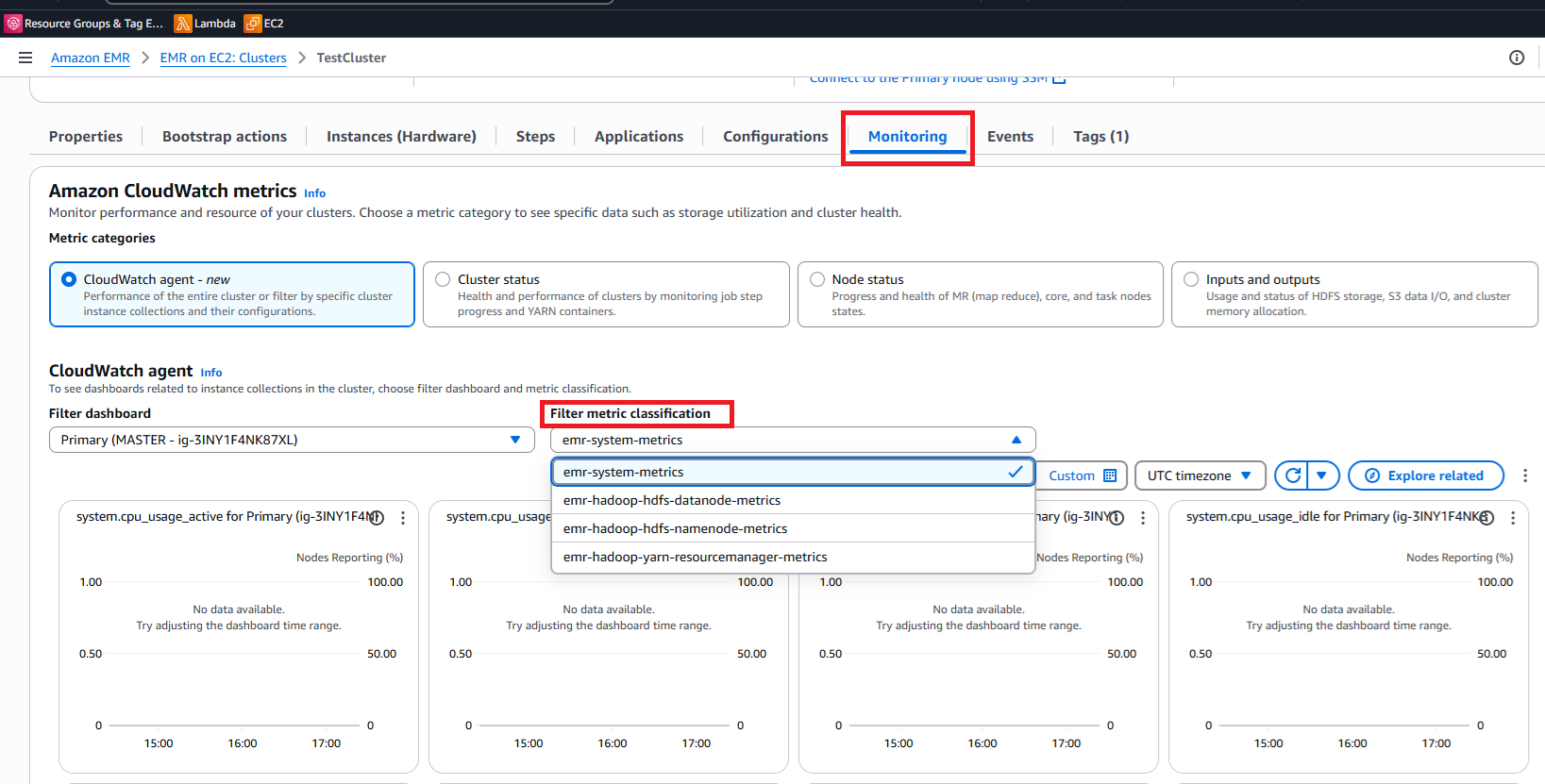
メトリクス分類のフィルタリング。
