AWS Glue でのストリーミング ETL ジョブ
連続的に実行されるストリーミング抽出/変換/ロード (ETL) ジョブを作成し、Amazon Kinesis Data Streams、Apache Kafka、Amazon Managed Streaming for Apache Kafka (Amazon MSK) などのストリーミングソースからのデータを使用できます。ジョブはデータをクレンジングして変換し、その結果を Amazon S3 データレイクまたは JDBC データストアにロードします。
さらに、Amazon Kinesis Data Streams ストリーム用のデータを生成できます。この機能は AWS Glue スクリプトを作成中のみ使用できます。詳細については、「Kinesis 接続」を参照してください。
デフォルトでは、AWS Glue は 100 秒ウィンドウ単位でデータ処理と書き出しを行います。これにより、データを効率的に処理しつつ、想定より遅く到着したデータに対する集計を実行できます。このウィンドウサイズを変更して、タイムリーで高精度の集計にできます。AWS Glue ストリーミングジョブでは、ジョブブックマークではなくチェックポイントを使用して、読み取られたデータを追跡します。
注記
AWS Glue では、実行中の ETL ジョブのストリーミングに対して 1 時間ごとに課金します。
このビデオでは、ストリーミング ETL のコストに関する課題と、AWS Glue のコスト削減機能について説明しています。
ストリーミング ETL ジョブを作成するには、次の手順を実行します。
-
Apache Kafka ストリーミングソースの場合は、Kafka ソースまたは Amazon MSK クラスターへの AWS Glue 接続を作成します。
-
ストリーミングソースの Data Catalog テーブルを手動で作成します。
-
ストリーミングデータソースの ETL ジョブを作成します。ストリーミング固有のジョブプロパティを定義し、独自のスクリプトを指定するか、生成されたスクリプトを必要に応じて変更します。
詳細については、「AWS Glue でのストリーミング ETL」を参照してください。
Amazon Kinesis Data Streams にストリーミング ETL ジョブを作成する場合、AWS Glue 接続を作成する必要はありません。ただし、Kinesis Data Streams をソースとする AWS Glue ストリーミング ETL ジョブへの接続がある場合は、の場合は、Kinesis への Virtual Private Cloud (VPC) エンドポイントが必要です。詳細については、 Amazon VPC ユーザーガイド のインターフェイスエンドポイントの作成を参照してください。別のアカウントで Amazon Kinesis Data Streams ストリームを指定する場合は、クロスアカウントアクセスを許可するようにロールおよびポリシーを設定する必要があります。詳細については、「例: 別のアカウントで Kinesis Stream から読み込む」を参照してください。
AWS Glue ストリーミング ETL ジョブにより、圧縮データの自動検出が行えます。また、ストリーミングデータを透過的に解凍し、入力ソースに対して一般的な変換を実行して、出力ストアにロードすることができます。
AWS Glue は、入力形式に対して指定された、以下の圧縮タイプのための自動解凍をサポートしています。
| 圧縮タイプ | Avro ファイル | Avro データム | JSON | CSV | Grok |
|---|---|---|---|---|---|
| BZIP2 | はい | あり | あり | あり | あり |
| GZIP | いいえ | あり | あり | あり | あり |
| SNAPPY | はい (raw Snappy) | はい (framed Snappy) | はい (フレーム付 Snappy) | はい (フレーム付 Snappy) | はい (フレーム付 Snappy) |
| XZ | はい | あり | あり | あり | あり |
| ZSTD | あり | なし | なし | なし | なし |
| DEFLATE | はい | あり | あり | あり | あり |
トピック
Apache Kafka データストリームの AWS Glue 接続の作成
Apache Kafka ストリームから読み取りを行うには、AWS Glue 接続を作成する必要があります。
Kafka ソース用の AWS Glue 接続を作成するには (コンソール)
https://console.aws.amazon.com/glue/
で AWS Glue コンソール を開きます。 -
ナビゲーションペインの [データカタログ] で [接続] を選択します。
-
[接続の追加] を選択し、[接続のプロパティを設定します] ページで接続名を入力します。
注記
接続プロパティ指定の詳細については、「AWS Glue connection properties.」( の接続プロパティ) を参照してください。
-
[接続タイプ] で、[Kafka] を選択します。
-
Kafka のブートストラップサーバーの URL として、Amazon MSK クラスターまたは Apache Kafka クラスターのブートストラップブローカーのホストとポート番号を入力します。Kafka クラスターへの初期接続を確立するには、Transport Layer Security (TLS) エンドポイントのみを使用します。Plaintext エンドポイントはサポートされていません。
Amazon MSK クラスターのホスト名とポート番号のペアのリスト例を次に示します。
myserver1.kafka.us-east-1.amazonaws.com:9094,myserver2.kafka.us-east-1.amazonaws.com:9094, myserver3.kafka.us-east-1.amazonaws.com:9094ブートストラップブローカー情報の取得の詳細については、Amazon Managed Streaming for Apache Kafka デベロッパーガイドの「Getting the Bootstrap Brokers for an Amazon MSK Cluster」を参照してください。
-
Kafka データソースへのセキュアな接続が必要な場合は、[Require SSL connection] (SSL 接続が必要) を選択し、[Kafka private CA certificate location] (Kafka のプライベート CA 証明書の場所) に、カスタム SSL 証明書への有効な Amazon S3 パスを入力します。
自己管理型 Kafka への SSL 接続の場合、カスタム証明書は必須です。Amazon MSK ではオプションです。
Kafka のカスタム証明書を指定する方法の詳細については、「AWS Glue SSL 接続プロパティ」を参照してください。
-
AWS Glue Studio または AWS CLI を使用して、Kafka クライアントの認証方法を指定します。AWS Glue Studio にアクセスするには、左側のナビゲーションペインの [ETL] メニューから [AWS Glue] を選択します。
Kafka クライアントの認証方法の詳細については、「クライアント認証用の AWS Glue Kafka 接続プロパティ 」を参照してください。
-
必要に応じて説明を入力し、[Next] (次へ) をクリックします。
-
Amazon MSK クラスターの場合は、その Virtual Private Cloud (VPC)、サブネット、およびセキュリティグループを指定します。VPC 情報は、自己管理型 Kafka の場合はオプションです。
-
[Next] (次へ) をクリックして、すべての接続プロパティを確認し、[Finish] (完了) をクリックします。
AWS Glue 接続の詳細については、「データへの接続」を参照してください。
クライアント認証用の AWS Glue Kafka 接続プロパティ
- SASL/GSSAPI (Kerberos) 認証
-
この認証方法を選択すると、Kerberos のプロパティを指定できます。
- Kerberos のキータブ
-
キータブファイルの場所を選択します。キータブには、1 つ以上のプリンシパルの長期キーが保存されます。詳細については、「MIT Kerberos ドキュメント: キータブ
」を参照してください。 - Kerberos の krb5.conf ファイル
-
krb5.conf ファイルを選択します。これには、デフォルトの領域 (同じ KDC のシステムのグループを定義する論理ネットワークで、ドメインに類似しています) と KDC サーバーの場所が含まれます。詳細については、「MIT Kerberos ドキュメント: krb5.conf
」を参照してください。 - Kerberos のプリンシパルと Kerberos のサービス名
-
Kerberos のプリンシパルとサービス名を入力します。詳細については、「MIT Kerberos ドキュメント: Kerberos のプリンシパル
」を参照してください。 - SASL/SCRAM-SHA-512 認証
-
この認証方法を選択すると、認証情報を指定することができます。
- AWS Secrets Manager
-
[Search] (検索) ボックスに名前または ARN を入力して、トークンを検索します。
- プロバイダのユーザー名とパスワードを直接入力
-
[Search] (検索) ボックスに名前または ARN を入力して、トークンを検索します。
- SSL クライアント認証
-
この認証方法を選択すると、Amazon S3 を参照することによって Kafka クライアントキーストアの場所を選択できます。オプションで、Kafka クライアントキーストアのパスワードと Kafka クライアントキーのパスワードを入力できます。
- IAM 認証
-
この認証方法は追加の仕様を必要とせず、ストリーミングソースが MSK Kafka の場合にのみ適用されます。
- SASL/PLAIN 認証
-
この認証方法を選択すると、認証情報を指定することができます。
ストリーミングソースの Data Catalog テーブルの作成
データスキーマなど、ソースデータストリームのプロパティを指定するデータカタログテーブルを手動でストリーミングソースに対して作成できます。このテーブルは、ストリーミング ETL ジョブのデータソースとして使用されます。
ソースデータストリーム内のデータのスキーマがわからない場合は、スキーマなしでテーブルを作成できます。次に、ストリーミング ETL ジョブを作成するときに、AWS Glue スキーマ検出機能を有効にできます。AWS Glue では、ストリーミングデータからスキーマを決定します。
テーブルを作成するには、AWS Glue コンソール
注記
AWS Lake Formation コンソールを使用してテーブルを作成することはできません。AWS Glue コンソールを使用する必要があります。
また、Avro 形式のストリーミングソースや Grok パターンを適用できるログデータについては、次の情報を考慮します。
Kinesis データソース
テーブルを作成するときは、次のストリーミング ETL プロパティ (コンソール) を設定します。
- ソースの種類
-
Kinesis
- 同じアカウント内の Kinesis ソースの場合:
-
- リージョン
-
Amazon Kinesis Data Streams サービスが存在する AWS リージョン。リージョンと Kinesis ストリーム名は一緒にストリーム ARN に変換されます。
例: https://kinesis.us-east-1.amazonaws.com
- Kinesis ストリーム名
-
Amazon Kinesis Data Streams デベロッパーガイドの「Creating a Stream」に記載されているストリーム名。
- 別のアカウントの Kinesis ソースについては、この例 を参照して、アカウント間アクセスを許可するようにロールとポリシーを設定します。これらの設定を行います。
-
- ストリーム ARN
-
コンシューマーを登録する Kinesis データストリームの ARN。詳細については、AWS 全般のリファレンス の「Amazon リソースネーム (ARN) と AWS サービス ネームスぺース」を参照してください。
- 引き受けたロールの ARN
-
引き受けるロールの Amazon リソースネーム (ARN)。
- セッション名 (オプション)
-
引き受けたロールセッションの識別子。
異なるプリンシパルによって同じロールが引き継がれた場合にセッションを一意に識別するために、またはその他の理由で、ロールセッション名を使用します。クロスアカウントシナリオでは、ロールセッション名が表示され、ロールを所有するアカウントでログ記録できます。引き受けたロールプリンシパルの ARN では、ロールセッション名も使用されます。つまり、一時的なセキュリティ認証情報を使用する後続のクロスアカウント API リクエストでは、ロールセッション名が AWS CloudTrail ログとして外部アカウントに開示されます。
Amazon Kinesis Data Streams のストリーミング ETL プロパティを設定するには (AWS Glue API または AWS CLI)
-
同じアカウント内の Kinesis ソースのストリーミング ETL プロパティを設定するには、
CreateTableAPI オペレーションまたはcreate_tableCLI コマンドのStorageDescriptorデータ構造のstreamNameおよびendpointUrlパラメータを指定します。"StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamName": "sample-stream", "endpointUrl": "https://kinesis.us-east-1.amazonaws.com" } ... }または、
streamARNを指定します。"StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream" } ... } -
別のアカウントの Kinesis ソースのストリーミング ETL プロパティを設定するには、
CreateTableAPI オペレーションまたはcreate_tableCLI コマンドのStorageDescriptorデータ構造のstreamARN、awsSTSRoleARN、およびawsSTSSessionName(オプション) パラメータを指定します。"StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream", "awsSTSRoleARN": "arn:aws:iam::123456789:role/sample-assume-role-arn", "awsSTSSessionName": "optional-session" } ... }
Kafka データソース
テーブルを作成するときは、次のストリーミング ETL プロパティ (コンソール) を設定します。
- ソースの種類
-
Kafka
- Kafka ソースの場合:
-
- トピック名
-
Kafka で指定されたトピック名。
- 接続
-
Kafka ソースを参照する AWS Glue 接続 (「Apache Kafka データストリームの AWS Glue 接続の作成」を参照)。
AWS Glue スキーマレジストリテーブルのソース
AWS Glue スキーマレジストリをストリーミングジョブに使用するには、ユースケース: AWS Glue Data Catalog スキーマレジストリのテーブルを作成または更新する手順に従ってください。
現在、AWS Glue ストリーミングは、false にスキーマ推論が設定されたGlue スキーマレジストリ Avro 形式のみをサポートします。
Avro ストリーミングソースに関する注意事項と制約事項
Avro 形式のストリーミングソースには、次の注意事項と制限事項が適用されます。
-
スキーマの検出が有効になっている場合、Avro スキーマをペイロードに含める必要があります。無効にすると、ペイロードにはデータのみが含まれます。
-
一部の Avro データ型は、ダイナミックフレームでサポートされていません。AWS Glue コンソールの [create table] (テーブル作成) ウィザードの [Define a schema] (スキーマの定義) でスキーマを定義するときに、これらのデータ型を指定することはできません。スキーマの検出中に、Avro スキーマでサポートされていない型は、次のようにサポートされている型に変換されます。
-
EnumType => StringType -
FixedType => BinaryType -
UnionType => StructType
-
-
コンソールの [Define a schema] (スキーマの定義) ページでテーブルスキーマを定義する場合は、スキーマの暗黙のルート要素タイプは
recordです。record以外のルート要素タイプ (arrayやmapなど) が必要な場合、[Define a schema] (スキーマの定義) ページでスキーマを指定することはできません。代わりに、そのページをスキップして、スキーマをテーブルプロパティとして、または ETL スクリプト内で指定する必要があります。-
テーブルのプロパティでスキーマを指定するには、テーブル作成ウィザードを完了し、テーブルの詳細を編集し、[Table properties] (テーブルのプロパティ) に新しいキーと値のペアを追加します。
avroSchemaキーを使用して、次のスクリーンショットに示すように、値のスキーマ JSON オブジェクトを入力します。![[Table properties] (テーブルのプロパティ) の見出しの下に、2 列のテキストフィールドがあります。左側の列見出しは [Key] (キー) であり、右側の列見出しは [Value] (値) です。最初の行のキー/値のペアは、classification/avro です。2 行目のキー/値のペアは、avroSchema/{"type":"array","items":"string"} です。](images/table_properties_avro.png)
-
ETL スクリプトでスキーマを指定するには、次の Python と Scala の例に示すように、
datasource0代入ステートメントを修正し、avroSchemaキーをadditional_options引数に追加します。
-
ストリーミングソースへの grok パターンの適用
ログデータソース用のストリーミング ETL ジョブを作成し、Grok パターンを使用してログを構造化データに変換できます。その後、ETL ジョブは、データを構造化データソースとして処理します。ストリーミングソースの Data Catalog テーブルを作成するときに適用する Grok パターンを指定します。
Grok パターンとカスタムパターン文字列値については、「Grok カスタム分類子の書き込み」を参照してください。
Grok パターンを Data Catalog テーブルに追加するには (コンソール)
-
[create table] (テーブル作成) ウィザードを使用し、ストリーミングソースの Data Catalog テーブルの作成 に指定されたパラメータでテーブルを作成します。データ形式を Grok として指定し、[Grok pattern] (Grok パターン) フィールドに入力し、必要に応じてカスタムパターンを [Custom patterns (optional)] (カスタムパターン (オプション)) に追加します。
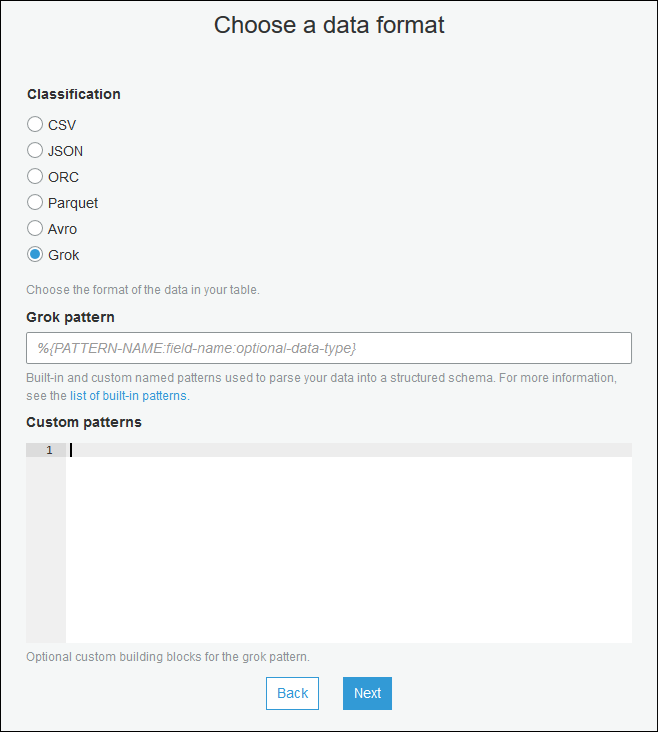
各カスタムパターンの後に、Enter を押します。
Grok パターンを Data Catalog テーブルに追加するには (AWS Glue API または AWS CLI)
-
GrokPatternパラメータと、必要に応じてCustomPatternsパラメータをCreateTableAPI オペレーションまたはcreate_tableCLI コマンドに追加します。"Parameters": { ... "grokPattern": "string", "grokCustomPatterns": "string", ... },grokCustomPatternsを文字列として表現し、パターン間の区切りとして「\n」を使用します。これらのパラメータの指定の例を次に示します。
"parameters": { ... "grokPattern": "%{USERNAME:username} %{DIGIT:digit:int}", "grokCustomPatterns": "digit \d", ... }
ストリーミング ETL ジョブのジョブプロパティの定義
AWS Glue コンソールでストリーミング ETL ジョブを定義する場合は、次に示すストリーム固有のプロパティを指定します。その他のジョブプロパティの説明については、「Spark ジョブのジョブプロパティの定義」を参照してください。
- IAM ロール
-
ジョブの実行、ストリーミングソースへのアクセス、およびターゲットデータストアへのアクセスに使用されるリソースへの権限付与に使用される AWS Identity and Access Management (IAM) ロールを指定します。
Amazon Kinesis Data Streams にアクセスする場合は、 AWS 管理ポリシー
AmazonKinesisFullAccessをロールにアタッチするか、よりきめ細かにアクセスを許可する同様の IAM ポリシーをアタッチします。サンプルポリシーについては、「IAM を使用して Amazon Kinesis Data Streams リソースへのアクセスを制御する」を参照してください。AWS Glue でジョブを実行するためのアクセス権限の詳細については、AWS Glue のアイデンティティとアクセスの管理 を参照してください。
- タイプ
-
[Spark Streaming] (スパークストリーミング)を選択します。
- AWS Glue バージョン
-
AWS Glue バージョンによって、ジョブで使用できる Apache Spark、および Python または Scala のバージョンが決まります。ジョブで使用可能な Python または Scala のバージョンを指定する選択肢を選択します。AWS Glueバージョン 2.0 (Python 3 をサポート) は、ストリーミング ETL ジョブのデフォルトです。
- メンテナンスウィンドウ
-
ストリーミングジョブを再起動できるウィンドウを指定します。「AWS Glue ストリーミングのメンテナンスウィンドウ」を参照してください。
- ジョブのタイムアウト
-
必要に応じて、長さを分単位で入力します。デフォルト値は空白です。
ストリーミングジョブのタイムアウト値は 7 日または 10080 分未満である必要があります。
値が空白の場合、メンテナンスウィンドウを設定していない場合、ジョブは 7 日後に再起動されます。メンテナンスウィンドウを設定している場合、ジョブは7 日後にメンテナンスウィンドウ中に再起動されます。
- データソース
-
「ストリーミングソースの Data Catalog テーブルの作成」で作成したテーブルを指定します。
- データターゲット
-
次のいずれかを行います:
-
[データターゲットでテーブルを作成する] を選択し、次に示すデータターゲットプロパティを指定します。
- データストア
-
Amazon S3 または JDBC を選択します。
- 形式
-
任意の形式を選択します。ストリーミングではすべてがサポートされています。
-
[Use tables in the data catalog and update your data target] (データカタログのテーブルを使用し、データターゲットを更新する) を選択し、JDBC データストアのテーブルを選択します。
-
- 出力スキーマ定義
-
次のいずれかを行います:
-
[Automatically detect schema of each record] (各レコードのスキーマを自動的に検出) を選択してスキーマ検出を有効にします。AWS Glue は、ストリーミングデータからスキーマを決定します。
-
[Specify output schema for all records] (すべてのレコードの出力スキーマを指定する) を選択して、[Apply Mapping] (マッピングの適用) 変換を使用して出力スキーマを定義します。
-
- スクリプト
-
必要に応じて、独自のスクリプトを指定するか、生成されたスクリプトを変更して、Apache Spark 構造化ストリーミングエンジンでサポートされる操作を実行します。使用可能な操作の詳細については、「Operations on streaming DataFrames/Datasets
」を参照してください。
ストリーミング ETL に関する注意と制限
次の注意事項と制限事項に留意してください。
-
AWS Glue ストリーミング ETL ジョブでの自動解凍は、サポートされた圧縮タイプに対してのみ使用できます。また、以下の点にも注意してください。
Framed Snappy とは、公式のフレーミング形式
を使用する Snappy を指します。 Deflate がサポートされるのは、Glue バージョン 3.0 です (Glue バージョン 2.0 ではサポートされません)。
-
スキーマ検出を使用する場合、ストリーミングデータの結合を実行できません。
-
AWS Glue のストリーミング ETL ジョブは、Avro 形式の AWS Glue スキーマレジストリに対する Union データ型をサポートしません。
-
ETL スクリプトでは、AWS Glue の組み込み変換と Apache Spark 構造化ストリーミングのネイティブな変換を使用できます。詳細については、Apache Spark ウェブサイトの「ストリーミング DataFrames/Datasets の操作
」または「AWS Glue PySpark 変換リファレンス」を参照してください。 -
AWS Glue ストリーミング ETL ジョブでは、チェックポイントを使用して、読み取ったデータの追跡が行われます。このため、停止して再起動されたジョブは、ストリーム内で中断した位置から開始されます。データを再処理する場合は、スクリプト内で参照されているチェックポイントフォルダを削除することができます。
-
ジョブのブックマークはサポートされていません。
-
ジョブで Kinesis Data Streams の拡張ファンアウト機能を使用するには、「Kinesis ストリーミングジョブでの拡張ファンアウトの使用」を参照してください。
-
AWS Glue スキーマレジストリ から作成されたData Catalog テーブルを使用する場合、新しいスキーマバージョンが使用可能になったら、新しいスキーマを反映するには、次の操作を行う必要があります。
-
テーブルに関連するジョブを停止します。
-
Data Catalog テーブルのスキーマを更新します。
-
テーブルに関連付するジョブを再起動します。
-
