AWS Glue 向けの自動スケーリングの使用
Auto Scaling は、AWS Glue ETL、インタラクティブセッション、および AWS Glue バージョン 3.0 以降のストリーミングジョブで使用できます。
Auto Scaling を有効にすると、次のようなメリットがあります。
-
AWS Glue は、ジョブ実行の各ステージでの並行処理またはマイクロバッチに応じて自動的にワーカーをクラスターに追加、またはクラスターから削除します。
-
これにより AWS Glue ETL ジョブに割り当てるワーカーの数について試行して判断する必要性を排除します。
-
最大数のワーカーの場合、AWS Glue がワークロードに適したサイズのリソースを選択します。
-
ジョブの実行中にクラスターのサイズがどのように変化するかについては、AWS Glue Studio のジョブ実行の詳細ページの CloudWatch メトリクスで確認できます。
AWS Glue ETL およびストリーミングジョブ向けの Auto Scaling は、AWS Glue ジョブのコンピューティングリソースのオンデマンドでのスケールアップとスケールダウンを可能にします。オンデマンドのスケールアップは、ジョブ実行のスタートアップに必要なコンピューティングリソースのみを最初に割り当てることができ、またジョブ実行中の需要に応じて必要なリソースをプロビジョニングするためにも役立ちます。
Auto Scaling は、ジョブの過程全体での AWS Glue ジョブリソースの動的なスケールインもサポートします。ジョブ実行中に Spark アプリケーションからより多くのエグゼキューターが要求されると、より多くのワーカーがクラスターに追加さます。エグゼキュータがアクティブな計算タスクなしでアイドル状態になると、エグゼキュータと対応するワーカーが削除されます。
Auto Scaling が Spark アプリケーションのコストと使用率に役立つ一般的なシナリオは次のとおりです。
-
Spark ドライバーがAmazon S3 内の多数のファイルを一覧表示している、またはエグゼキュターが非アクティブのときにロードを実行している場合
-
Spark ステージがオーバープロビジョニングにより、少数のエグゼキュターのみで実行されている場合
-
Spark ステージ間でのデータの偏りまたは不均一な計算需要
要件
Auto Scaling は、AWS Glue バージョン 3.0 以降でのみ利用可能です。Auto Scaling を使用するには、「移行ガイド」に従って既存のジョブをバージョン 3.0 以降の AWS Glue に移行するか、AWS Glue のバージョン 3.0 以降を使用して新しいジョブを作成します。
Auto Scaling は、G.1X、G.2X、G.4X、G.8X、G.12X、G.16X、R.1X、R.2X、R.4X、R.8X、または G.025X (ストリーミングジョブのみ) ワーカータイプを使用する AWS Glue ジョブに利用できます。Auto Scaling は標準 DPU をサポートしていません。
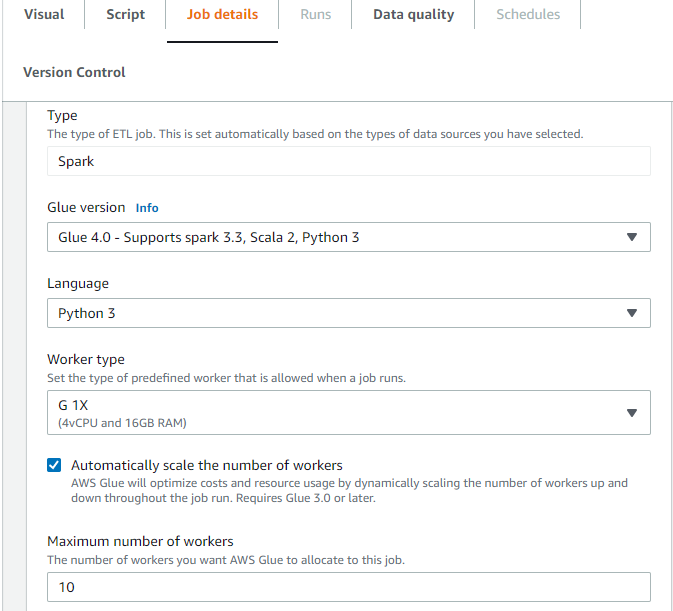
AWS Glue Studio の Auto Scaling を有効にする
AWS Glue Studio の [ジョブ詳細] タブで、タイプに [Spark] または [Spark Streaming] を選択し、[Glue バージョン] には Glue 3.0 以降を選択します。次に、[ワーカータイプ] の下にチェックボックスが表示されます。
-
[Automatically scale the number of workers] (ワーカー数を自動的にスケールする) を選択します。
-
ワーカーの最大数を設定して、ジョブ実行に投入できるワーカーの最大数を定義します。
AWS CLI または SDK を使用した Auto Scaling の有効化
Auto Scaling を有効にするには、ジョブ実行の AWS CLI から、次の設定で start-job-run を実行します。
{ "JobName": "<your job name>", "Arguments": { "--enable-auto-scaling": "true" }, "WorkerType": "G.2X", // G.1X, G.2X, G.4X, G.8X, G.12X, G.16X, R.1X, R.2X, R.4X, and R.8X are supported for Auto Scaling Jobs "NumberOfWorkers": 20, // represents Maximum number of workers ...other job run configurations... }
ETL ジョブ実行が終了したら、get-job-run を呼び出して、実行されたジョブの実際のリソース使用量を DPU 秒単位で確認することもできます。注: 新しいフィールド [DPUSeconds] は、Auto Scaling が有効な AWS Glue 4.0 以降のバッチジョブに対してのみ表示されます。このフィールドは、ストリーミングジョブではサポートされません。
$ aws glue get-job-run --job-name your-job-name --run-id jr_xx --endpoint https://glue.us-east-1.amazonaws.com --region us-east-1 { "JobRun": { ... "GlueVersion": "3.0", "DPUSeconds": 386.0 } }
同じ設定で AWS Glue SDK を使用して、Auto Scaling でジョブ実行を設定することもできます。
インタラクティブセッションによる Auto Scaling の有効化
インタラクティブセッションを使用して AWS Glue ジョブを構築するときに Auto Scaling を有効にするには、「AWS Glue インタラクティブセッションの設定」を参照してください。
ヒントと注意点
AWS Glue Auto Scaling を微調整するためのヒントと注意点:
-
ワーカーの最大数の初期値について不明な場合は、推定 AWS Glue DPU で説明されている概算計算から始めることができます。データ量が非常に少ない場合、最大ワーカー数に極端に大きな値を設定しないでください。
-
AWS Glue Auto Scaling は、ジョブで設定された DPU の最大数 (ワーカーの最大数とワーカータイプで計算) に基づいて
spark.sql.shuffle.partitionsとspark.default.parallelismを設定します。これらの設定で固定値を使用する場合は、次のジョブパラメータでこれらのパラメータを上書きできます。-
[Key] (キー):
--conf -
値:
spark.sql.shuffle.partitions=200 --conf spark.default.parallelism=200
-
-
ストリーミングジョブの場合、デフォルトでは、AWS Glue はマイクロバッチ内で自動スケーリングせず、自動スケーリングを開始するには複数のマイクロバッチが必要です。マイクロバッチ内で自動スケーリングを有効にする場合は、
--auto-scale-within-microbatchを指定します。詳細については、「擬似パラメータのリファレンス」を参照してください。
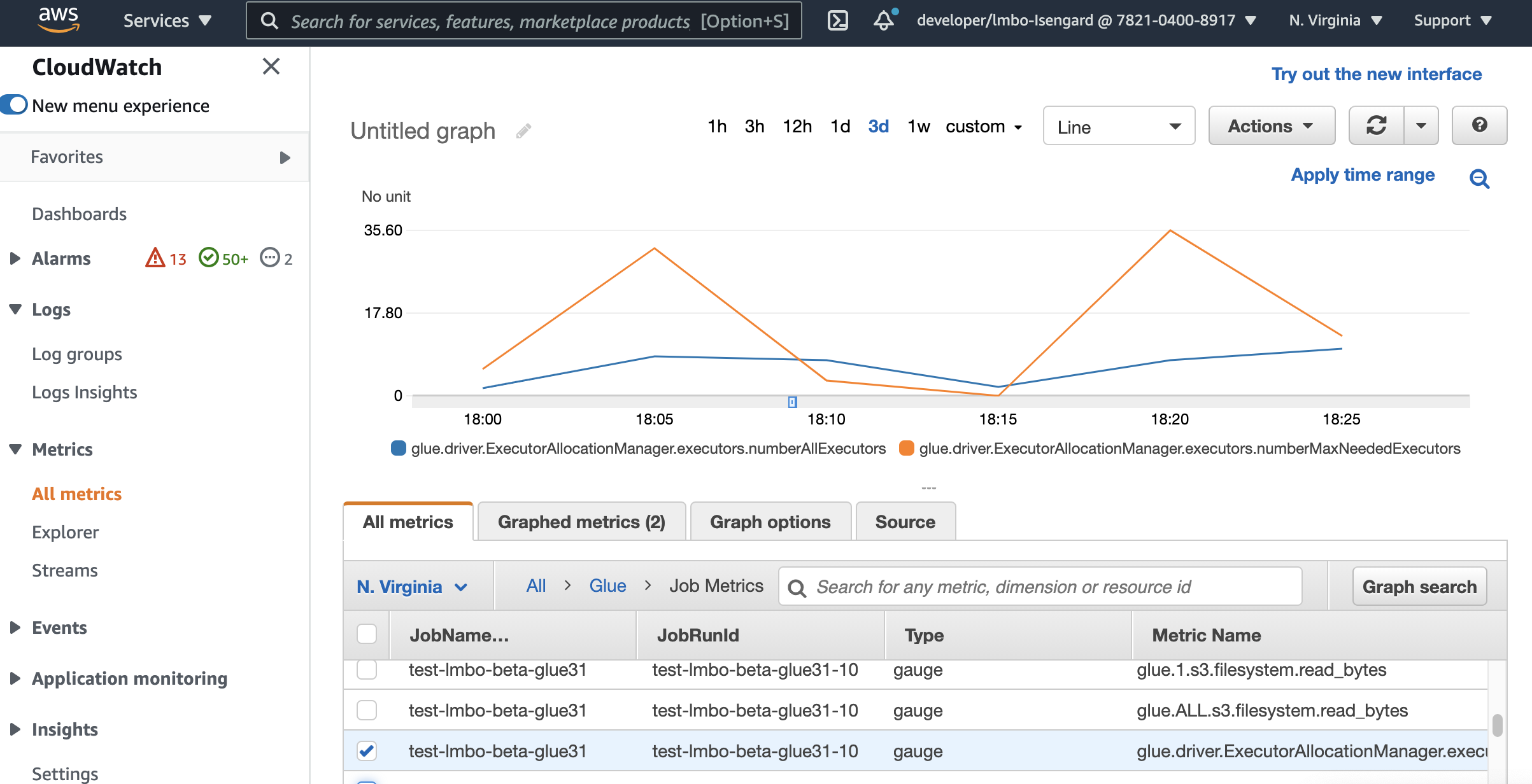
Amazon CloudWatch メトリクスを使用した Auto Scaling のモニタリング
Auto Scaling を有効にすると、CloudWatch の実行者メトリクスが AWS Glue 3.0 以降のジョブで利用できるようになります。メトリクスを使用して、Auto Scaling で有効化された Spark アプリケーションでのエグゼキューターの需要と最適化された使用状況をモニタリングできます。詳細については、「Amazon CloudWatch メトリクスを使用した AWS Glue のモニタリング」を参照してください。
また、AWS Glue オブザーバビリティメトリクスを使用して、リソース使用率に関するインサイトを取得することもできます。例えば、glue.driver.workerUtilization をモニタリングすることで、自動スケーリングの有無にかかわらず、実際に使用されたリソースの量をモニタリングできます。別の例として、glue.driver.skewness.job と glue.driver.skewness.stage をモニタリングすることで、データの歪みを確認できます。これらのインサイトは、自動スケーリングを有効にするかどうかを決定し、設定を微調整するのに役立ちます。詳細については、「AWS Glue オブザーバビリティメトリクスを使用したモニタリング でのモニタリング」を参照してください。
-
glue.driver.ExecutorAllocationManager.executors.numberAllExecutors
-
glue.driver.ExecutorAllocationManager.executors.numberMaxNeededExecutors
これらのメトリクスの詳細については、「DPU の容量計画のモニタリング」を参照してください。
注記
CloudWatch エグゼキュターメトリクスは、インタラクティブセッションでは使用できません。
Amazon CloudWatch Logs での Auto Scaling のモニタリング
インタラクティブセッションを使用している場合、エグゼキュターの数をモニタリングするには、継続的な Amazon CloudWatch Logs を有効にしてログ内の「executor」を検索するか、Spark UI を使用します。これを行うには、%%configure マジックを使用して enable auto scaling とともに継続的なログ記録を有効にします。
%%configure{ "--enable-continuous-cloudwatch-log": "true", "--enable-auto-scaling": "true" }
Amazon CloudWatch Logseventsで、ログ内の「executor」を検索します。

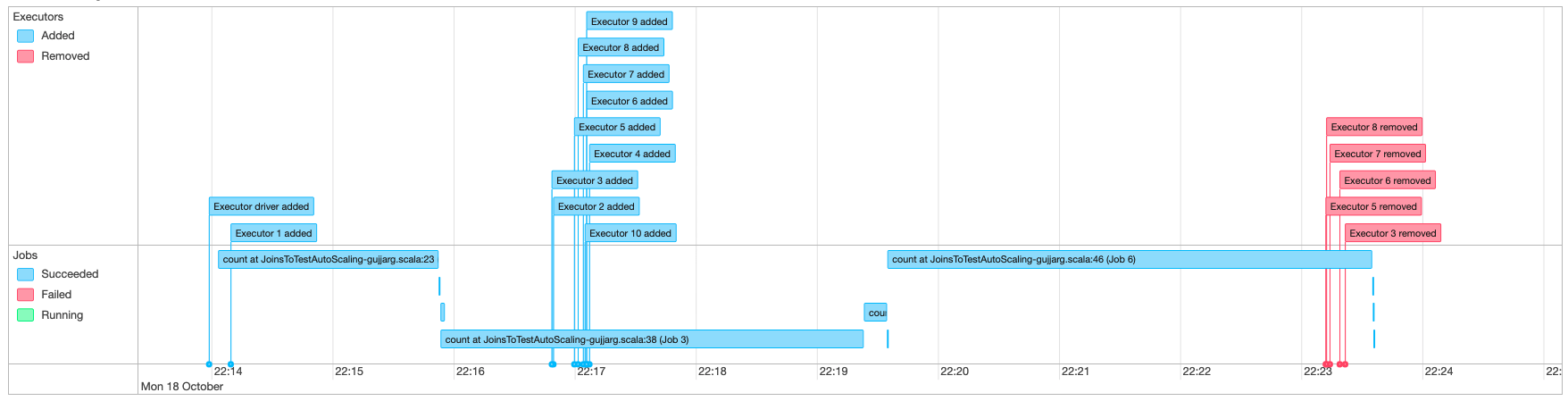
Spark UI による Auto Scaling のモニタリング
Auto Scaling を有効にすると、Glue Spark UI を使用して、AWS Glue ジョブの需要に基づいた動的なスケールアップとスケールダウンで追加または削除されるエグゼキュターをモニタリングすることもできます。詳細については、「AWS Glue ジョブ用の Apache Spark ウェブ UI の有効化」を参照してください。
Jupyter Notebook のインタラクティブセッションを使用すると、次のマジックを実行して、Spark UI とともに自動スケーリングを有効にすることができます。
%%configure{ "--enable-auto-scaling": "true", "--enable-continuous-cloudwatch-log": "true" }
Auto Scaling ジョブ実行の DPU 使用量モニタリング
[AWS Glue Studio ジョブ実行ビュー] を使用して、Auto Scaling ジョブの DPU 使用量をチェックします。
-
AWS Glue Studio ナビゲーションペインから [モニタリング] を選択します。Monitoring (モニタリング) ページが表示されます。
-
ジョブ実行チャートまでスクロールダウンします。
-
チェックしたいジョブ実行に移動して、[DPU hours] (DPU 時間) 列を下にスクロールして、そのジョブ実行の使用量をチェックします。
制限
AWS Glue ストリーミングの Auto Scaling は現在、ForEachBatch 外で作成された静的 DataFrame とのストリーミング DataFrame の結合をサポートしていません。ForEachBatch 内で作成された 静的 DataFrame は、期待通りに動作します。
