データ品質定義言語 (DQDL) リファレンス
データ品質定義言語 (DQDL) は、AWS Glue Data Quality でのルール定義に使用するドメイン固有の言語です。
このガイドでは、DQDL の理解を助けるために、この言語の主要な概念について解説します。また、DQDL ルールタイプのリファレンスの中で、構文や例も提供しています。このガイドを開始する際には、あらかじめ AWS Glue Data Quality を理解しておくことをお勧めします。詳細については、「AWS Glue Data Quality」を参照してください。
注記
DynamicRules は AWS Glue ETL でのみサポートされています。
目次
DQDL 構文
DQDL のドキュメントでは大文字と小文字が区別されます。また、個々の 品質評価ルールをグループ化したルールセットが含まれます。ルールセットを作成するには、Rules という名前 (大文字) の、角括弧で区切られたリストを作成する必要があります。リストの中には、次の例のようにカンマで区切られた 1 つ以上の DQDL ルールを含めます。
Rules = [ IsComplete "order-id", IsUnique "order-id" ]
ルールの構造
DQDL ルールの構造は、そのルールタイプによって異なります。ただし、DQDL の各ルールは、以下のような基本的な形式を取ります。
<RuleType> <Parameter> <Parameter> <Expression>
RuleType は設定するルールタイプの名前で、大文字と小文字が区別されます。例えば、IsComplete、IsUnique、または CustomSql です。ルールタイプごとに、ルールのパラメータが異なります。DQDL のルールタイプと、そのパラメータの詳細なリファレンスについては、「DQDL ルールタイプリファレンス」を参照してください。
複合ルール
DQDL では、ルールを組み合わせる際に、以下の論理演算子を使用できます。これらのルールは複合ルールと呼ばれます。
- and
-
and論理演算子は、接続するルールがすべてtrueである場合に限り、結果にtrueを返します。それ以外の場合、ルールの組み合わせ結果はfalseになります。and演算子前後に配置する各ルールは、丸括弧で囲む必要があります。次の例では、
and演算子を使用して 2 つの DQDL ルールを組み合わせています。(IsComplete "id") and (IsUnique "id") - or
-
or論理演算子は、接続するルールが 1 つ以上trueであれば、結果にtrueを返します。or演算子前後に配置する各ルールは、丸括弧で囲む必要があります。次の例では、
or演算子を使用して 2 つの DQDL ルールを組み合わせています。(RowCount "id" > 100) or (IsPrimaryKey "id")
同じ演算子を使用して複数のルールを接続でき、次のようなルールの組み合わせが可能です。
(Mean "Star_Rating" > 3) and (Mean "Order_Total" > 500) and (IsComplete "Order_Id")
論理演算子を 1 つの式にまとめることができます。例:
(Mean "Star_Rating" > 3) and ((Mean "Order_Total" > 500) or (IsComplete "Order_Id"))
より複雑な入れ子になったルールを作成することもできます。
(RowCount > 0) or ((IsComplete "colA") and (IsUnique "colA"))
複合ルールの仕組み
デフォルトでは、複合ルールはデータセットまたはテーブル全体の個別のルールとして評価されたら、結果が結合されます。つまり、最初に列全体を評価してから演算子を適用します。このデフォルト動作は以下の例で説明します。
# Dataset +------+------+ |myCol1|myCol2| +------+------+ | 2| 1| | 0| 3| +------+------+ # Overall outcome +----------------------------------------------------------+-------+ |Rule |Outcome| +----------------------------------------------------------+-------+ |(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)|Failed | +----------------------------------------------------------+-------+
上の例では、AWS Glue Data Quality は最初に失敗に終わる (ColumnValues "myCol1" > 1) を評価します。次に (ColumnValues "myCol2" > 2) を評価しますが、これも失敗します。両方の結果の組み合わせは FAILED として表示されます。
ただし、行全体を評価する必要がある SQL のような動作を好む場合、以下のコードスニペットの additionalOptions で示すように ruleEvaluation.scope パラメータを明示的に設定する必要があります。
object GlueApp { val datasource = glueContext.getCatalogSource( database="<db>", tableName="<table>", transformationContext="datasource" ).getDynamicFrame() val ruleset = """ Rules = [ (ColumnValues "age" >= 26) OR (ColumnLength "name" >= 4) ] """ val dq_results = EvaluateDataQuality.processRows( frame=datasource, ruleset=ruleset, additionalOptions=JsonOptions(""" { "compositeRuleEvaluation.method":"ROW" } """ ) ) }
AWS Glue Data Catalog では、次に示すように、ユーザーインターフェイスでこのオプションを簡単に設定できます。
![このスクリーンショットは、行と列の間でルール評価設定を選択できる複合ルール設定ウィンドウを示しています。[行] を選択した場合、複合ルールは行全体を評価する単一のルールとして動作します。[列] を選択した場合、複合ルールはデータセット全体の個々のルールを評価し、結果を結合します。](images/composite-rule-settings.png)
いったん設定すると、複合ルールは行全体を評価する単一のルールとして動作します。次の例では、この動作を示します。
# Row Level outcome +------+------+------------------------------------------------------------+---------------------------+ |myCol1|myCol2|DataQualityRulesPass |DataQualityEvaluationResult| +------+------+------------------------------------------------------------+---------------------------+ |2 |1 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed | |0 |3 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed | +------+------+------------------------------------------------------------+---------------------------+
一部のルールは全体的な結果がしきい値または比率に依存するため、この機能ではサポートできません。以下に一覧表示します。
比率に依存するルール:
-
Completeness
-
DatasetMatch
-
ReferentialIntegrity
-
Uniqueness
しきい値に依存するルール:
次のルールにしきい値が含まれる場合、ルールはサポートされません。ただし、with threshold に関連しないルールは引き続きサポートされます。
-
ColumnDataType
-
ColumnValues
-
CustomSQL
表現
ルールタイプがブール型で応答を生成しない場合、この応答を取得するには、パラメータで表現を指定する必要があります。例えば、次のルールでは、表現に対応させながら列内のすべての値の mean 値 (平均) をチェックし、真または偽の結果を返します。
Mean "colA" between 80 and 100
一部のルールタイプ (IsUnique や IsComplete など) は、既にブール型の応答を返しています。
次の表に、DQDL ルールで使用できる式を一覧で示します。
| 式 | 説明 | 例 |
|---|---|---|
=x |
ルールタイプの応答が x と等しい場合、true を返します。 |
|
!=x |
ルールタイプの応答が x と等しくない場合、x は true を返します。 |
|
> x |
ルールタイプの応答が x より大きい場合、true を返します。 |
|
< x |
ルールタイプの応答が x より小さい場合、true を返します。 |
|
>= x |
ルールタイプの応答が x 以上の場合、true を返します。 |
|
<= x |
ルールタイプの応答が x 以下の場合、true を返します。 |
|
between x and y |
ルールタイプの応答が指定された範囲内 (除外) にある場合、true を返します。この式のタイプは、数値および日付タイプにのみ使用できます。 |
|
x と y の間ではない |
ルールタイプの応答が指定された範囲外 (含有) にある場合、true を返します。この式のタイプは、数値および日付のタイプにのみ使用できます。 |
|
in [a, b, c, ...] |
ルールタイプの応答が指定されたセットに含まれている場合に、true を返します。 |
|
not in [a, b, c, ...] |
ルールタイプの応答が指定されたセットに含まれていない場合、true を返します。 |
|
matches /ab+c/i |
ルールタイプの応答が正規表現と一致する場合に、true を返します。 |
|
not matches /ab+c/i |
ルールタイプのレスポンスが正規表現と一致しない場合、true を返します。 |
|
now() |
日付表現を作成する ColumnValues ルールタイプでのみ機能します。 |
|
matches/in […]/not matches/not in [...] with threshold |
ルール条件に一致する値をパーセンテージで指定します。ColumnValues、ColumnDataType、CustomSQL のルールタイプのみで使用できます。 |
|
NULL、EMPTY、WHITESPACES_ONLY のキーワード
文字列の列に null、空、空白のみの文字列があるかどうかを検証する場合、次のキーワードを使用できます。
-
NULL / null – 文字列の列の
null値には、このキーワードは true を返します。50% 以上のデータに null 値が含まれていない場合、
ColumnValues "colA" != NULL with threshold > 0.5は true を返します。null 値または長さが 5 を超えるすべての行に対し、
(ColumnValues "colA" = NULL) or (ColumnLength "colA" > 5)は true を返します。これには、「compositeRuleEvaluation.Method」=「ROW」オプションを使用する必要があることに注意してください。 -
EMPTY / empty – 文字列の列に空の文字列 (“”) の値には、このキーワードは true を返します。一部のデータ形式は、文字列の列に null を空の文字列に変換します。このキーワードは、データの空の文字列を除外するのに便利です。
行が空、「a」、「b」のいずれかの場合、
(ColumnValues "colA" = EMPTY) or (ColumnValues "colA" in ["a", "b"])は true を返します。これには、「compositeRuleEvaluation.Method」=「ROW」オプションを使用する必要があることに注意してください。 -
WHITESPACES_ONLY / whitespaces_only – 文字列の列で空白 (“ ”) のみの値が含まれる文字列には、このキーワードは true を返します。
行が「a」、「b」、空白のいずれかでない場合、
ColumnValues "colA" not in ["a", "b", WHITESPACES_ONLY]は true を返します。サポートされているルール:
数値または日付ベースの式には、列に null があるかどうかを検証する場合、次のキーワードを使用できます。
-
NULL / null – 文字列の列の null 値には、このキーワードは true を返します。
列の日付が
2023-01-01または null の場合、ColumnValues "colA" in [NULL, "2023-01-01"]は true を返します。null 値または 1 から 9 までの値が含まれているすべての行に対し、
(ColumnValues "colA" = NULL) or (ColumnValues "colA" between 1 and 9)は true を返します。これには、「compositeRuleEvaluation.Method」=「ROW」オプションを使用する必要があることに注意してください。サポートされているルール:
Where 句によるフィルタリング
注記
Where 句は AWS Glue 4.0 でのみサポートされています。
ルールの作成時にデータをフィルタリングできます。これは、条件付きルールを適用する場合に便利です。
<DQDL Rule> where "<valid SparkSQL where clause> "
フィルターは where キーワード、その後に引用符 ("") で囲まれた有効な Spark SQL ステートメントを指定する必要があります。
しきい値を持つルールに Where 句を追加するルールの場合、しきい値条件の前に Where 句を指定する必要があります。
<DQDL Rule> where "valid SparkSQL statement>" with threshold <threshold condition>
この構文では次のようなルールを記述できます。
Completeness "colA" > 0.5 where "colB = 10" ColumnValues "colB" in ["A", "B"] where "colC is not null" with threshold > 0.9 ColumnLength "colC" > 10 where "colD != Concat(colE, colF)"
提供された Spark SQL ステートメントが有効であることを検証します。無効な場合、ルールの評価は失敗し、次の形式の IllegalArgumentException がスローされます。
Rule <DQDL Rule> where "<invalid SparkSQL>" has provided an invalid where clause : <SparkSQL Error>
行レベルのエラーレコード識別が有効になっている場合の句の動作
AWS Glue Data Quality を使用すると、失敗した特定のレコードを識別できます。行レベルの結果をサポートするルールに Where 句を適用すると、Where 句で除外された行に Passed というラベルが付けられます。
フィルタリングされた行に個別にSKIPPEDというラベルを付ける場合は、ETL ジョブに以下additionalOptionsを設定できます。
object GlueApp { val datasource = glueContext.getCatalogSource( database="<db>", tableName="<table>", transformationContext="datasource" ).getDynamicFrame() val ruleset = """ Rules = [ IsComplete "att2" where "att1 = 'a'" ] """ val dq_results = EvaluateDataQuality.processRows( frame=datasource, ruleset=ruleset, additionalOptions=JsonOptions(""" { "rowLevelConfiguration.filteredRowLabel":"SKIPPED" } """ ) ) }
例として、次のルールとデータフレームを参照してください:
IsComplete att2 where "att1 = 'a'"
| id | att1 | att2 | 行レベルの結果 (デフォルト) | 行レベルの結果 (スキップオプション) | コメント |
|---|---|---|---|---|---|
| 1 | a | f | PASSED | PASSED | |
| 2 | b | d | PASSED | SKIPPED | att1 は "a" ではないため、行はフィルターで除外されます |
| 3 | a | null | FAILED | FAILED | |
| 4 | a | f | PASSED | PASSED | |
| 5 | b | null | PASSED | SKIPPED | att1 は "a" ではないため、行はフィルターで除外されます |
| 6 | a | f | PASSED | PASSED |
動的ルール
注記
動的ルールは AWS Glue ETL でのみサポートされており、 AWS Glue Data Catalog ではサポートされていません。
動的ルールを作成して、ルールによって生成された現在のメトリクスと履歴値を比較できるようになりました。これらの履歴比較は、式に last() 演算子を使用することで可能になります。例えば、現在の実行で行数が同じデータセットの最新の行数よりも多い場合、RowCount >
last() ルールは成功します。last() は、考慮すべき事前メトリクスの数を記述する自然数引数をオプションで取り、last(k) では k
>= 1 が直近の k メトリクスを参照します。
-
データポイントがない場合、
last(k)はデフォルト値 0.0 を返します。 -
利用可能な
kメトリクスよりも少ない場合は、last(k)はそれ以前のメトリクスをすべて返します。
有効な式を作成するには last(k) を使用します。k > 1 では、複数の履歴結果を 1 つの数値にまとめる集計関数が必要です。例えば RowCount > avg(last(5)) は、現在のデータセットの行数が、同じデータセットの直近の 5 つの行数の平均より真に大きいかどうかを確認します。現在のデータセットの行数をリストと有意に比較できないため、RowCount > last(5) はエラーを生成します。
サポートされている集計関数:
-
avg -
median -
max -
min -
sum -
std(標準偏差) -
abs(絶対値) -
index(last(k), i)では直近のkからi番目に新しい値を選択できます。iはゼロインデックスであるため、index(last(3), 0)は最新のデータポイントを返しますが、データポイントが 3 つしかなく、4 番目に新しいデータポイントにインデックスを付けようとするため、index(last(3), 3)はエラーになります。
式の例
ColumnCorrelation
ColumnCorrelation "colA" "colB" < avg(last(10))
DistinctValuesCount
DistinctValuesCount "colA" between min(last(10))-1 and max(last(10))+1
数値条件またはしきい値を使用するほとんどのルールタイプは動的ルールをサポートします。使用しているルールタイプで動的ルールがサポートされているかどうかを確認するには、提供されている「アナライザーとルール」の表を参照してください。
動的ルールからの統計の除外
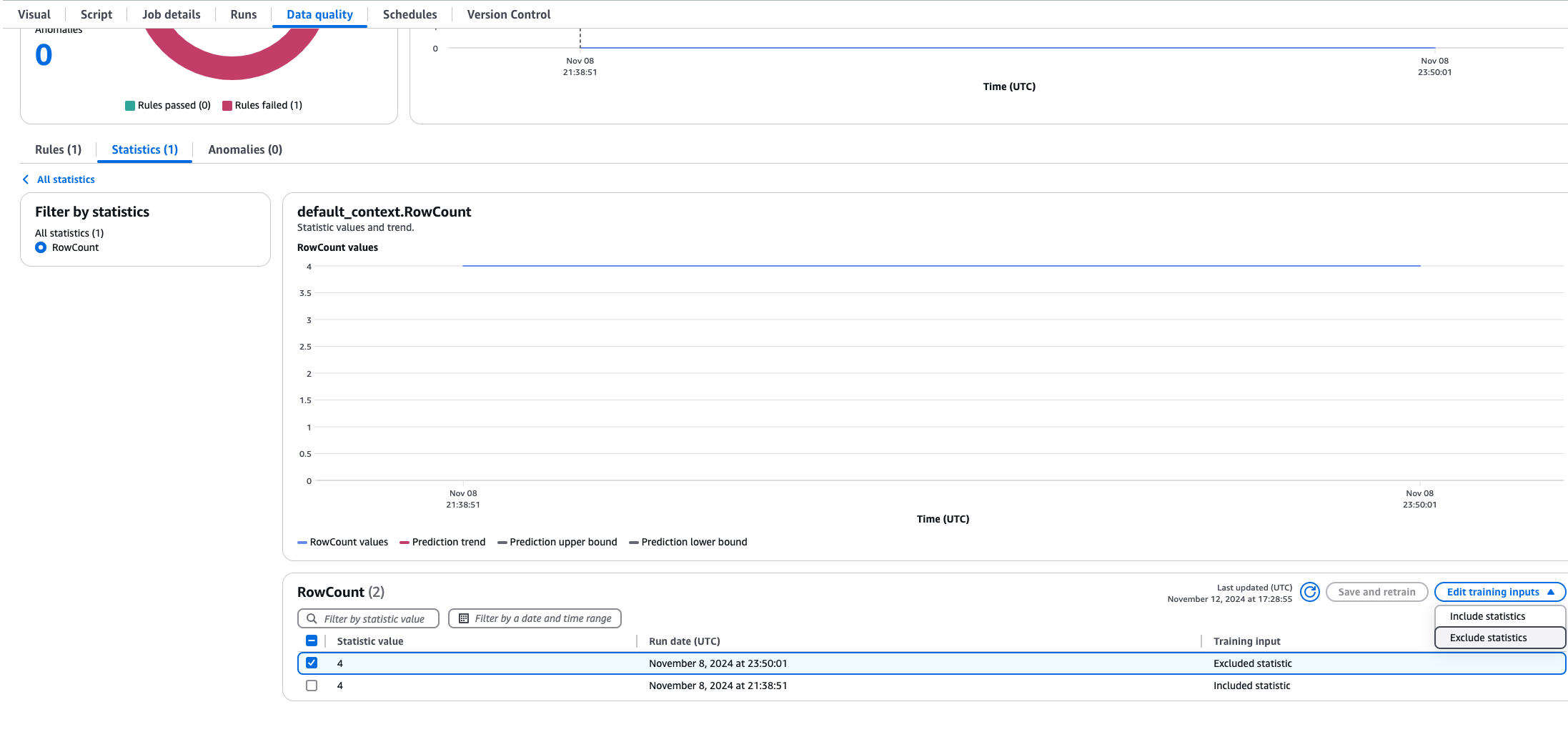
場合によっては、動的ルール計算からデータ統計を除外する必要があります。履歴データのロードを行い、それを平均値に影響を与えたくないとします。これを行うには、AWS Glue ETL でジョブを開き、[データの品質] タブを選択し、[統計] を選択し、除外する統計を選択します。統計の表とともにトレンドチャートを表示できます。除外する値を選択し、[統計を除外] を選択します。これで、除外された統計は動的ルール計算に含まれなくなります。
アナライザー
注記
アナライザーは、AWS Glue Data Catalog ではサポートされていません。
DQDL ルールは、アナライザーと呼ばれる関数を使用してデータに関する情報を収集します。この情報をルールのブール式に使用して、ルールが成功するか失敗するかを決定します。例えば、RowCount ルール RowCount > 5 は、行数アナライザーを使用してデータセット内の行数を検出し、その数を式 > 5 と比較して、現在のデータセットに 5 行以上存在するかどうかを確認します。
ルールを作成する代わりに、アナライザーを作成して、異常の検出に使用できる統計を生成させることを推奨する場合があります。このような場合は、アナライザーを作成できます。アナライザーは、次の点でルールとは異なります。
| 特徴 | アナライザー | ルール |
|---|---|---|
| ルールセットの一部 | はい | あり |
| 統計を生成 | はい | あり |
| 観察結果を生成 | はい | あり |
| 条件を評価してアサートできる | なし | あり |
| 障害発生時にジョブを停止したり、ジョブの処理を続行したりするなどのアクションを設定できます。 | なし | あり |
アナライザーはルールなしで独立して存在できるため、アナライザーをすばやく構成し、データ品質ルールを段階的に構築できます。
ルールセットの Analyzers ブロックに入力できるルールタイプもあります。これにより、アナライザーに必要なルールを実行し、条件のチェックを行わずに情報を収集できます。アナライザーの中には、ルールに関連付けられておらず、Analyzers ブロックにしか入力できないものもあります。次の表は、各項目がルールとしてサポートされているか、スタンドアロンアナライザーとしてサポートされているか、および各ルールタイプの詳細を示しています。
アナライザーを使用したルールセットの例
以下のルールセットでは以下のものが使用されます。
-
直近の 3 回のジョブ実行で、データセットが平均値を上回っているかどうかを確認する動的ルール
-
データセットの
Name列内の異なる値の数を記録するDistinctValuesCountアナライザー -
Nameの最小サイズと最大サイズを経時的に追跡するColumnLengthアナライザー
アナライザーメトリクスの結果は、ジョブ実行の [データ品質] タブで確認できます。
Rules = [ RowCount > avg(last(3)) ] Analyzers = [ DistinctValuesCount "Name", ColumnLength "Name" ]
AWS Glue Data Quality は、次のアナライザーをサポートしています。
| アナライザー名 | 機能 |
|---|---|
RowCount |
データセットの行数を計算します |
Completeness |
列の完全性の割合を計算します |
Uniqueness |
列の一意性の割合を計算します |
Mean |
数値列の平均を計算します |
Sum |
数値列の合計を計算します |
StandardDeviation |
数値列の標準偏差を計算します |
Entropy |
数値列のエントロピーを計算します |
DistinctValuesCount |
列内の個別値の数を計算します |
UniqueValueRatio |
列内の一意の値の比率を計算します |
ColumnCount |
データセット内の列数を計算します |
ColumnLength |
列の長さを計算します |
ColumnValues |
数値列の最小値と最大値を計算します。数値列以外の最小の ColumnLength と最大の ColumnLength を計算します |
ColumnCorrelation |
特定の列の列相関を計算します |
CustomSql |
カスタム SQL によって返される統計を計算します |
AllStatistics |
次の統計を計算します:
|
コメント
「#」文字を使用して DQDL ドキュメントにコメントを追加できます。「#」文字の後から行末までに含まれるすべての文字は DQDL に無視されます。
Rules = [ # More items should generally mean a higher price, so correlation should be positive ColumnCorrelation "price" "num_items" > 0 ]
