プロビジョニング済み同時実行の設定
Lambda での同時実行は、関数が現在処理している未完了のリクエストの数です。利用できる同時実行コントロールには、次の 2 種類があります。
-
予約された同時実行 — これは、関数に割り当てられた同時インスタンスの最大数です。ある関数が予約済み同時実行を使用している場合、他の関数はその同時実行を使用できません。関数に対して予約される同時実行を設定する場合には追加料金がかかりません。
-
プロビジョニングされた同時実行 — これは、関数に割り当てる、事前に初期化された実行環境の数です。これらの実行環境は、受信した関数リクエストに即座に対応できます。プロビジョニングされた同時実行を設定すると、AWS アカウント に追加料金が請求されます。
このトピックでは、プロビジョニング済み同時実行を管理および設定する方法について説明します。これら 2 種類の同時実行制御の概念的な概要については、「予約済み同時実行とプロビジョニング済み同時実行」を参照してください。予約済み同時実行の設定の詳細については、「予約済同時実行数の設定」を参照してください。
注記
Amazon MQ イベントソースマッピングにリンクされた Lambda 関数には、デフォルトの最大同時実行数があります。Apache ActiveMQ の場合、同時インスタンスの最大数は 5 です。RabbitMQ の場合、同時インスタンスの最大数は 1 です。関数に予約またはプロビジョニングされる同時実行数を設定しても、これらの制限は変わりません。Amazon MQ を使用する場合のデフォルトの最大同時実行数の増加をリクエストするには、AWS Support にお問い合わせください。
セクション
プロビジョニング済み同時実行の設定
Lambda コンソールまたは Lambda API を使用して、関数のプロビジョニング済み同時実行の設定を行うことができます。
プロビジョニング済み同時実行を関数に割り当てるには (コンソール)
Lambda コンソールの「関数
」ページを開きます。 -
プロビジョニング済み同時実行を割り当てる関数を選択します。
-
[設定]、[同時実行] の順にクリックします。
-
[プロビジョニング済み同時実行の設定] で、[設定を追加] をクリックします。
-
[同時実行の予約] をクリックします。関数用に予約する同時実行数を入力します。
-
修飾子のタイプ、エイリアスまたはバージョンを選択します。
注記
プロビジョニング済み同時実行は、どの関数の $LATEST バージョンでも使用できません。
関数にイベントソースがある場合は、そのイベントソースが正しい関数エイリアスまたはバージョンを指していることを確認してください。正しくない場合、関数はプロビジョニング済み同時実行環境を使用しません。
-
[プロビジョニング済み同時実行] に数値を入力します。Lambda は毎月の費用の見積もりを提供します。
-
[保存] を選択します。
アカウントで設定できるのは、予約なしアカウントの同時実行数から 100 を引いた数までです。残りの 100 単位の同時実行数は、予約済み同時実行を使用しない関数用です。たとえば、アカウントの同時実行数の制限が 1,000 で、他の関数に予約済みまたはプロビジョニング済み同時実行を割り当てていない場合、1 つの関数に対して最大 900 のプロビジョニング済み同時実行単位を設定できます。
ある関数にプロビジョニングされた同時実行を設定すると、他の関数で使用できる同時実行のプールに影響が生じます。例えば、function-a のプロビジョニングされた同時実行を 100 単位に設定すると、アカウント内の他の関数は残りの 900 単位の同時実行を共有する必要があります。これは、function-a が 100 ユニットすべてを使用しない場合にも当てはまります。
予約された同時実行とプロビジョニングされた同時実行の両方を同じ関数に割り当てることができます。このような場合、プロビジョニングされた同時実行は予約された同時実行を超えることはありません。
この制限は関数バージョンにも適用されます。特定の関数バージョンに割り当てることができるプロビジョニングされた同時実行の最大数は、その関数の予約された同時実行数から他の関数バージョンのプロビジョニングされた同時実行数を引いたものです。
Lambda API でプロビジョニング済み同時実行を設定するには、以下の API オペレーションを使用します。
たとえば、AWS Command Line Interface (CLI) でプロビジョニング済み同時実行を設定するには、put-provisioned-concurrency-config コマンドを使用します。以下のコマンドにより、my-function という名前の関数の BLUE エイリアスに、100 単位のプロビジョニング済み同時実行を割り当てます。
aws lambda put-provisioned-concurrency-config --function-name my-function \ --qualifier BLUE \ --provisioned-concurrent-executions 100
次のような出力が表示されます。
{ "Requested ProvisionedConcurrentExecutions": 100, "Allocated ProvisionedConcurrentExecutions": 0, "Status": "IN_PROGRESS", "LastModified": "2023-01-21T11:30:00+0000" }
必要なプロビジョニング済み同時実行を正確に見積もる
CloudWatch メトリクスを使用して、アクティブな関数の同時実行メトリクスを表示できます。具体的には、ConcurrentExecutions メトリクスはアカウント内の関数の同時呼び出し数を表示します。
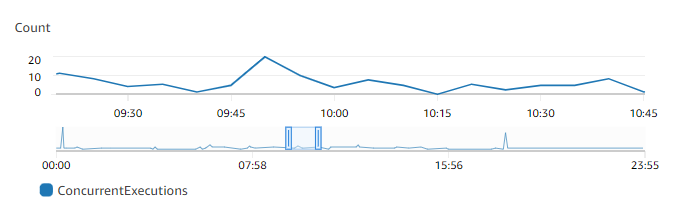
グラフによると、この関数は平均 5~10 件、最大で 20 件の同時リクエストを処理します。アカウントに、他にも多くの関数があるとします。この関数がアプリケーションにとって重要で、呼び出しのたびに低レイテンシーの応答が必要な場合は、プロビジョニングされた同時実行を 20 以上に設定します。
以下の式を使用して同時実行を計算することもできます。
Concurrency = (average requests per second) * (average request duration in seconds)
必要な同時実行数を見積もるには、秒ごとの平均リクエスト数に平均リクエスト時間 (秒単位) を掛けます。1 秒あたりの平均リクエスト数は Invocation メトリクスを、平均リクエスト時間 (秒単位) は Duration メトリクスを使用して見積もることができます。
プロビジョニングされた同時実行を設定する際、Lambda では、関数が通常必要とする同時実行数の 10% を余分に含めることを推奨します。例えば、関数の同時リクエスト数が通常 200 件まで増加する場合は、プロビジョニングされた同時実行を 220 (200 件の同時リクエスト + 10% = 220 のプロビジョニングされた同時実行) に設定してください。
プロビジョニング済み同時実行でレイテンシーを最適化する
レイテンシーを最適化するには、関数コードの構造はプロビジョニングされた同時実行環境とオンデマンド環境のどちらを選択するかによって異なります。プロビジョニングされた同時実行で実行される関数の場合、Lambda は割り当て時に初期化コード (ライブラリのロードやクライアントのインスタンス化など) を実行します。このため、実際の関数呼び出し中のレイテンシーへの影響を避けるために、メインの関数ハンドラーの外部で、できるだけ多くの初期化を行うことをお勧めします。対照的に、メインハンドラーコード内でライブラリを初期化したり、クライアントをインスタンス化したりすると、プロビジョニングされた同時実行を使用しているかどうかに関らず、関数は呼び出しのたびにこれを実行する必要があります。
オンデマンド呼び出しの場合、関数がコールドスタートするたびに、Lambda は初期化コードを再実行する必要がある場合があります。このような関数では、特定の機能の初期化処理を、関数が必要とするまで延期することができます。たとえば、次の Lambda ハンドラーの制御フローを考えてみます。
def handler(event, context): ... if ( some_condition ): // Initialize CLIENT_A to perform a task else: // Do nothing
前の例では、開発者は、メインハンドラーの外部で CLIENT_A を初期化する代わりに、if ステートメント内で初期化を行いました。これにより、Lambda は some_condition の条件を満たした場合にのみこのコードを実行します。メインハンドラーの外部で CLIENT_A を初期化した場合、Lambda はコールドスタートのたびにそのコードを実行します。これにより、全体のレイテンシーが長くなる可能性があります。
これにより、関数がプロビジョニング済み同時実行をすべて使い果たしてしまう可能性があります。Lambda はオンデマンドインスタンスを使用して過剰なトラフィックを処理します。Lambda が特定の環境で使用した初期化のタイプを特定するには、AWS_LAMBDA_INITIALIZATION_TYPE 環境変数の値を確認してください。この変数は、provisioned-concurrency または on-demand の値を取る可能性があります。AWS_LAMBDA_INITIALIZATION_TYPE の値は不変で、環境の存続期間を通じて一定に保たれます。
.NET 6 または .NET 7 ランタイムを使用する場合は、プロビジョニングされた同時実行を使用しない場合でも、AWS_LAMBDA_DOTNET_PREJIT 環境変数を設定して、関数のレイテンシーを改善できます。.NET ランタイムでは、コードが初めて呼び出すライブラリごとに遅延コンパイルと初期化を行います。この結果、Lambda 関数の呼び出しが、その後の呼び出しよりも長くかかる場合があります。これを軽減するには、AWS_LAMBDA_DOTNET_PREJIT の 3 つの値から 1 つを選択します。
-
ProvisionedConcurrency: Lambda は、プロビジョニング済み同時実行を使用して、すべての環境に対して事前 JIT コンパイルを実行します。これは、デフォルト値です。 -
Always: Lambda は、関数がプロビジョニング済み同時実行を使用しない場合でも、すべての環境に対して事前 JIT コンパイルを実行します。 -
Never: Lambda は、すべての環境に対して事前 JIT コンパイルを無効にします。
プロビジョニングされた同時実行環境では、関数の初期化コードは、割り当て時と、Lambda が環境のインスタンスをリサイクルする際に定期的に実行されます。環境インスタンスでリクエストが処理された後、ログとトレースで初期化時間を確認できます。Lambda では、環境インスタンスがリクエストを処理しない場合でも、初期化に対して課金されることに注意してください。プロビジョニングされた同時実行は継続的に実行され、初期化コストと呼び出しコストとは別に課金されます。詳細については、「AWS Lambda の料金
また、 Lambda 関数のプロビジョニングされた同時実行を設定すると、Lambda はその実行環境を事前に初期化して、関数呼び出しリクエストの前に使用できるようにします。ただし、関数が実際に呼び出された場合にのみ、関数は呼び出しログを CloudWatch に発行します。したがって、初期化が事前に行われた場合でも、Init Duration フィールドは最初の関数呼び出しの REPORT ログ行に表示されます。これは、関数でコールドスタートが発生したことを意味するものではありません。
プロビジョニング済み同時実行を使用した関数の最適化に関する追加のガイダンスについては、Serverless Land の「Lambda 実行環境
Application Auto Scaling でプロビジョニング済み同時実行を管理する
Application Auto Scaling を使用すると、スケジュールに従って、または使用率に基づいて、プロビジョニング済み同時実行を管理できます。関数が予測可能なトラフィックパターンを取得した場合は、スケジュールされたスケーリングを使用します。関数で特定の使用率を維持したい場合は、ターゲット追跡スケーリングポリシーを使用します。
スケジュールされたスケーリング
Application Auto Scaling により、予測可能な負荷の変化に従って独自のスケーリングスケジュールを設定できます。詳細と例については、「Application Auto Scaling ユーザーガイド」の「Application Auto Scaling のスケジュールされたスケーリング」、および「AWS コンピューティングブログ」の「定期的なピーク使用量に対する AWS Lambda のプロビジョニング済み同時実行のスケジューリング
ターゲット追跡
ターゲット追跡では、Application Auto Scaling がスケーリングポリシーの定義方法に基づいて、一連の CloudWatch アラームを作成および管理します。これらのアラームがアクティブになると、Application Auto Scaling はプロビジョニング済み同時実行を使用して、割り当てられる環境の量を自動的に調整します。トラフィックパターンが予測できないアプリケーションには、ターゲット追跡を使用してください。
ターゲットトラッキングを使用してプロビジョニング済み同時実行をスケールするには、RegisterScalableTarget および PutScalingPolicy の Application Auto Scaling API オペレーションを使用します。たとえば、AWS Command Line Interface (CLI) を使用している場合は、次の手順に従います。
-
関数のエイリアスをスケーリングターゲットとして登録します。次の例では、
my-functionという名前の関数の BLUE エイリアスを登録します。aws application-autoscaling register-scalable-target --service-namespace lambda \ --resource-id function:my-function:BLUE --min-capacity 1 --max-capacity 100 \ --scalable-dimension lambda:function:ProvisionedConcurrency -
スケーリングポリシーをターゲットに適用します。次の例では、アプリケーションの自動スケーリングを設定し、エイリアスのプロビジョニングされた同時実行の設定を調整することにより、使用率を 70% 近くに維持します。ただし、10% から 90% までの間の値を適用できます。
aws application-autoscaling put-scaling-policy \ --service-namespace lambda \ --scalable-dimension lambda:function:ProvisionedConcurrency \ --resource-id function:my-function:BLUE \ --policy-name my-policy \ --policy-type TargetTrackingScaling \ --target-tracking-scaling-policy-configuration '{ "TargetValue": 0.7, "PredefinedMetricSpecification": { "PredefinedMetricType": "LambdaProvisionedConcurrencyUtilization" }}'
次のような出力が表示されます。
{ "PolicyARN": "arn:aws:autoscaling:us-east-2:123456789012:scalingPolicy:12266dbb-1524-xmpl-a64e-9a0a34b996fa:resource/lambda/function:my-function:BLUE:policyName/my-policy", "Alarms": [ { "AlarmName": "TargetTracking-function:my-function:BLUE-AlarmHigh-aed0e274-xmpl-40fe-8cba-2e78f000c0a7", "AlarmARN": "arn:aws:cloudwatch:us-east-2:123456789012:alarm:TargetTracking-function:my-function:BLUE-AlarmHigh-aed0e274-xmpl-40fe-8cba-2e78f000c0a7" }, { "AlarmName": "TargetTracking-function:my-function:BLUE-AlarmLow-7e1a928e-xmpl-4d2b-8c01-782321bc6f66", "AlarmARN": "arn:aws:cloudwatch:us-east-2:123456789012:alarm:TargetTracking-function:my-function:BLUE-AlarmLow-7e1a928e-xmpl-4d2b-8c01-782321bc6f66" } ] }
Application Auto Scaling は CloudWatch に 2 つのアラームを作成します。最初のアラームは、プロビジョニング済み同時実行の使用率が一貫して 70% を超えたときにトリガーされます。これにより、Application Auto Scaling はプロビジョニング済み同時実行の割り当て数を増やして、使用率を下げます。2 番目のアラームは、使用率が一貫して 63% (70% ターゲットの 90%) を下回った場合にトリガーされます。これにより、Application Auto Scaling はエイリアスのプロビジョニング済み同時実行数を減らします。
次の例では、関数が使用率に基づいて、プロビジョニング済み同時実行の最小値と最大値の間でスケールします。
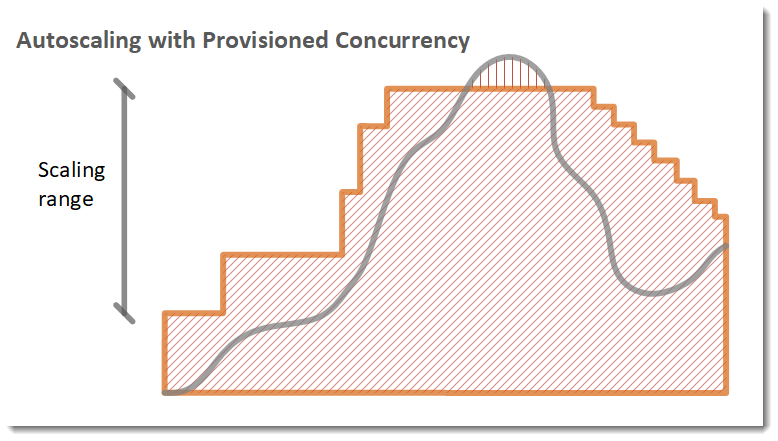
凡例
-
 関数のインスタンス数
関数のインスタンス数 -
 未処理のリクエスト数
未処理のリクエスト数 -
 プロビジョニング済み同時実行
プロビジョニング済み同時実行 -
 標準の同時実行数
標準の同時実行数
オープンリクエストの数が増加すると、Application Auto Scaling は設定された最大値に達するまで、プロビジョニング済み同時実行数を大規模なステップで増加させます。この後、アカウントの同時実行数の上限に達していなければ、関数は引き続き標準の予約されていない同時実行でスケールできます。使用率が下がり、低いまま続く場合、Application Auto Scaling はプロビジョニングされた同時実行数を減少させるために、より小規模な定期的ステップを実行します。
Application Auto Scaling アラームはどちらも、デフォルトで平均統計を使用します。トラフィックのクイックバーストが起こる関数は、これらのアラームをトリガーしない可能性があります。例えば、Lambda 関数が瞬間的に (20~100 ミリ秒) 実行され、トラフィックがクイックバーストしたとします。この場合、バースト中はリクエスト数が割り当てられた同時実行数を超えます。ただし、Application Auto Scaling では、追加の環境をプロビジョニングするために、バーストロードを少なくとも 3 分間維持する必要があります。さらに、両方の CloudWatch アラームでは、自動スケーリングポリシーを有効にするために、ターゲット平均に達している 3 つのデータポイントが必要です。関数でトラフィックが急増する場合、平均統計の代わりに最大統計を使用する方が、プロビジョニングされた同時実行をスケーリングしてコールドスタートを最小限に抑えるのに効果的です。
ターゲット追跡スケーリングポリシーの詳細については、「Application Auto Scaling のターゲット追跡スケーリングポリシー」を参照してください。
