Amazon Machine Learning サービスの更新や、その新しいユーザーの受け入れは行っていません。このドキュメントは既存のユーザー向けに提供されていますが、更新は終了しています。詳細については、「Amazon Machine Learning とは」を参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
交差検証
交差検証は、使用可能な入力データのサブセットでいくつかの ML モデルをトレーニングし、また、それらをデータの補完サブセットで評価することにより ML モデルを評価する手法です。交差検証を使用して、パターン生成の失敗などのオーバーフィットを検出します。
Amazon ML は、K 分割交差検証のメソッドを使用して交差検証を実行できます。K 分割交差検証では、入力データを K 個のデータのサブセットに分割します。 1 つ以外すべてのサブセット (k-1) で ML モデルをトレーニングし、トレーニングに使用しなかったサブセットでモデルを評価します。このプロセスが k 回、評価のために取り分けられた (トレーニングから除外された) 毎回異なるサブセットで繰り返されます。
次の図では、4 分割交差検証の時に作成されトレーニングされた 4 つのモデルそれぞれのために生成されたトレーニングサブセットと補完的な評価サブセットの例を示しています。モデル 1 は、最初の 25% のデータを評価に、残りの 75% をトレーニングに使用しています。モデル 2 は、2 番目のサブセットの 25 パーセント (25%~50%) を評価に、残りの 3 つのサブセットをトレーニングに使用していて、以降同様に続きます。
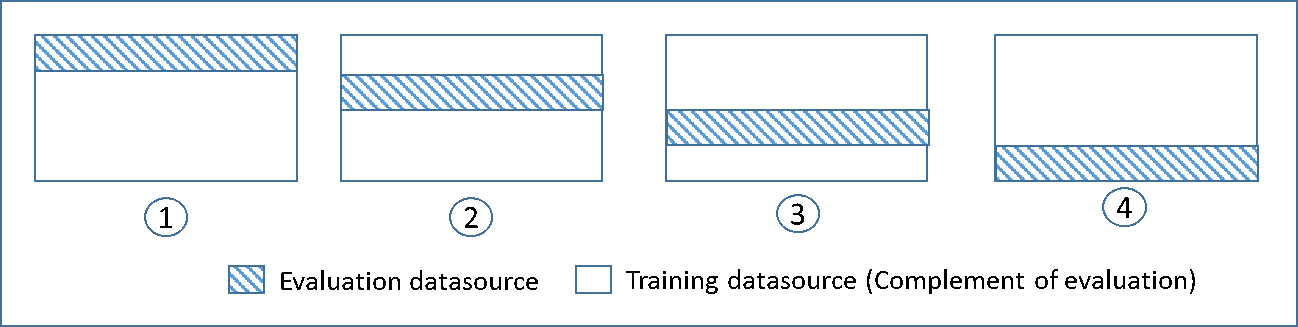
各モデルは、補完的なデータソースを使用してトレーニングされ、評価されます。評価データソースのデータには、とレーニンデータソースにないデータのみがすべて含まれています。これらの各サブセットのデータソースを作成するには、DataRearrangement、createDatasourceFromS3、および createDatasourceFromRedShift API の createDatasourceFromRDS パラメータを使用します。DataRearrangement パラメータでは、各セグメントの開始位置と終了位置を指定することで、データソースに含めるデータのサブセットを指定します。4k 分割の交差検証に必要な補完データソースを作成するには、以下の例に示すように DataRearrangement パラメータを指定します。
モデル 1:
評価のためのデータソース
{"splitting":{"percentBegin":0, "percentEnd":25}}
トレーニングのためのデータソース
{"splitting":{"percentBegin":0, "percentEnd":25, "complement":"true"}}
モデル 2:
評価のためのデータソース
{"splitting":{"percentBegin":25, "percentEnd":50}}
トレーニングのためのデータソース
{"splitting":{"percentBegin":25, "percentEnd":50, "complement":"true"}}
モデル 3:
評価のためのデータソース
{"splitting":{"percentBegin":50, "percentEnd":75}}
トレーニングのためのデータソース
{"splitting":{"percentBegin":50, "percentEnd":75, "complement":"true"}}
モデル 4:
評価のためのデータソース
{"splitting":{"percentBegin":75, "percentEnd":100}}
トレーニングのためのデータソース
{"splitting":{"percentBegin":75, "percentEnd":100, "complement":"true"}}
4 分割交差検証を実行すると、4 つのモデル、モデルをトレーニングするための 4 つのデータソース、モデルを評価するための 4 つのデータソース、および各モデルに 1 つずつの 4 つの評価が生成されます。Amazon ML では、評価ごとにモデルパフォーマンスメトリクスを生成します。たとえば、バイナリ分類問題の 4 分割交差検証では、それぞれの評価は曲線下面積 (AUC) メトリクスを報告します。全体的なパフォーマンスの測定値を取得するには、4 つの AUC のメトリクスの平均を計算します。AUC メトリクスの詳細については、「ML モデルの正確性の測定」を参照してください。
交差検証とモデルスコアの平均を作成する方法を示すサンプルコードについては、「Amazon ML サンプルコード
モデルの調整
モデルの交差検証をした後は、モデルのパフォーマンスが期待にそぐわない場合に、次のモデルの設定を調整できます。オーバーフィットの詳細については、「モデルフィット: アンダーフィットとオーバーフィット」を参照してください。正則化の詳細については、「正則化」を参照してください。正則化の設定の変更の詳細については、「カスタムオプションで ML モデルを作成する」を参照してください。
