Amazon Machine Learning サービスの更新や、その新しいユーザーの受け入れは行っていません。このドキュメントは既存のユーザー向けに提供されていますが、更新は終了しています。詳細については、「Amazon Machine Learning とは」を参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
複数モデルクラスの洞察
予測の解釈
複数クラス分類アルゴリズムの実際の出力は、一連の予測スコアです。スコアは、指定された観測がそれぞれのクラスに属しているというモデルの確実性を示します。バイナリ分類問題の場合とは異なり、予測を行うのにスコアのカットオフを選択する必要はありません。予測される回答は、予測スコアが最も高いクラス (たとえば、ラベル) です。
ML モデルの正確性の測定
複数クラスで使用される一般的なメトリクスは、すべてのクラスで平均した後のバイナリ分類のケースで使用されるメトリクスと同じです。Amazon ML では、マクロ平均 F1 スコアを使用して、複数クラスメトリクスの予測の精度を評価します。
マクロ平均 F1 スコア
F1 スコアは、バイナリメトリクスの正確性とリコールの両方を考慮するバイナリ分類メトリクスです。正確性とリコールを組み合わせた手法です。範囲は 0~1 です。値が大きいほど予測精度が良いことを示します。
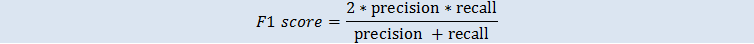
マクロ平均 F1 スコアは、複数クラスケースのすべてのクラスでの F1 スコアの非加重平均です。評価データセット内でのクラスの発生頻度は考慮されていません。値が大きいほど予測精度が良いことを示します。以下の例に示しているのは、評価データソースの K クラスです。
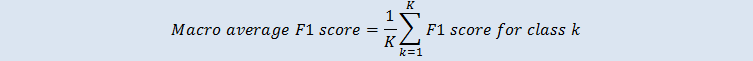
ベースラインマクロ平均 F1 スコア
Amazon ML には、複数クラスモデルのベースラインメトリクスが用意されています。これは、最も頻繁なクラスを回答として予測する仮の複数クラスモデルのマクロ平均 F1 スコアです。たとえば、映画のジャンルを予測するとき、トレーニングデータでの最も一般的なジャンルがロマンスであれば、ベースラインモデルは常にジャンルをロマンスと予測します。ML モデルをこのベースラインと比較することで、常にこの定数を回答として予測する ML モデルよりも自分の ML モデルが優れているかどうかを検証できます。
パフォーマンスの可視化の使用
Amazon ML では、複数クラス分類の予測モデルの精度を可視化する方法として、混合行列を提供しています。混同行列は、観測の予測クラスと真のクラスを比較することによって、各クラスの正しい予測と誤った予測の数または割合 (%) を表に示します。
たとえば、映画をジャンルに分類しようとしている場合、予測モデルはそのジャンル (クラス) がロマンスであると予測するかもしれません。しかし、実際のジャンルはサスペンスである場合があります。複数クラス分類 ML モデルの精度を評価するとき、Amazon ML はこれらの誤分類を識別し、次の図に示すように結果を混同行列に表示します。
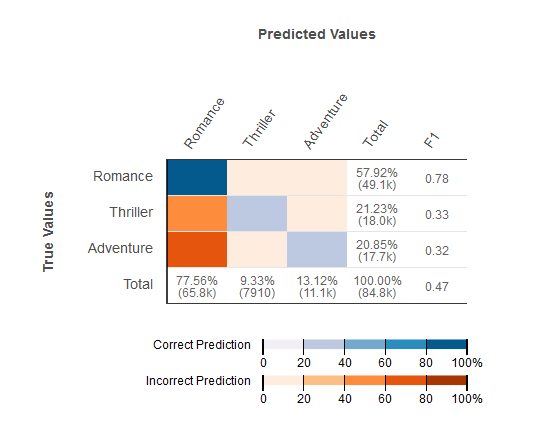
次の情報が混合行列に表示されます。
-
各クラスの正しい予測と誤った予測の数: 混同行列の各行は、真のクラスのメトリクスの 1 つに対応します。たとえば、最初の行は、実際にロマンスのジャンルにあるムービーについて、複数クラス ML モデルは、80% 以上のケースで正しい予測をしたことを示しています。20% 以下のケースでジャンルをサスペンスと誤って予測し、20% 以下のケースでアドベンチャーとしました。
-
クラス対応の F1 スコア: 最後の列は各クラスの F1 スコアを示しています。
-
評価データでの真のクラス頻度: 最後から 2 番目の列には、評価データセットで、57.92% の評価データがロマンス、21.23% がサスペンス、20.85% がアドベンチャーであることを示しています。
-
評価データの予測クラス頻度: 最後の行は、予測における各クラスの頻度を示しています。観測値の 77.56% はロマンスと予測され、9.33% はサスペンスと予測され、13.12% はアドベンチャーとして予測されています。
Amazon ML コンソールには、混合行列に最大 10 のクラスを、評価データの中で最も頻繁なクラスから最も頻度の低いクラスの順にリストできるビジュアル表示が用意されています。評価データに 10 以上のクラスがある場合は、混合行列の中で最も頻発する上位 9 つのクラスが表示され、他のすべてのクラスは「その他」というクラスにまとめられます。Amazon ML は、複数クラスの可視化ページのリンクから混合行列をすべてダウンロードする機能も提供しています。
