Amazon Managed Service for Apache Flink (Amazon MSF) は、以前は Amazon Kinesis Data Analytics for Apache Flink と呼ばれていました。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Managed Service for Apache Flink とは
Amazon Managed Service for Apache Flink では、Java、Scala、Python、または SQL を使用してストリーミングデータを処理および分析できます。このサービスを使用すると、ストリーミングソースと静的ソースに対してコードを作成して実行し、時系列分析、リアルタイムダッシュボードへのフィード、メトリクスを実行できます。
Managed Service for Apache Flink では、Apache
Apache Flink 用 Managed Serviceは、Apache Flink アプリケーションの基盤となるインフラストラクチャを提供します。コンピューティングリソースのプロビジョニング、AZ フェイルオーバーレジリエンス、並列計算、自動スケーリング、アプリケーションバックアップ (チェックポイントおよびスナップショットとして実装) などのコア機能を処理します。ハイレベルの Flink プログラミング特徴 (オペレータ、関数、ソース、シンクなど) は、Flink インフラストラクチャーを自分でホストするときと同じように使用できます。
Managed Service for Apache Flink と Managed Service for Apache Flink Studio のどちらを使用するかを決定する
Amazon Managed Service for Apache Flink で Flink ジョブを実行するには、2 つのオプションがあります。Managed Service for Apache Flink では、任意の IDE と Apache Flink Datastream または Table APIs。Managed Service for Apache Flink Studio を使用すると、データストリームをリアルタイムでインタラクティブにクエリし、標準の SQL、Python、Scala を使用してストリーム処理アプリケーションを簡単に構築して実行できます。
ユースケースに最適な方法を選択できます。不明な場合は、このセクションで役立つ大まかなガイダンスを提供します。
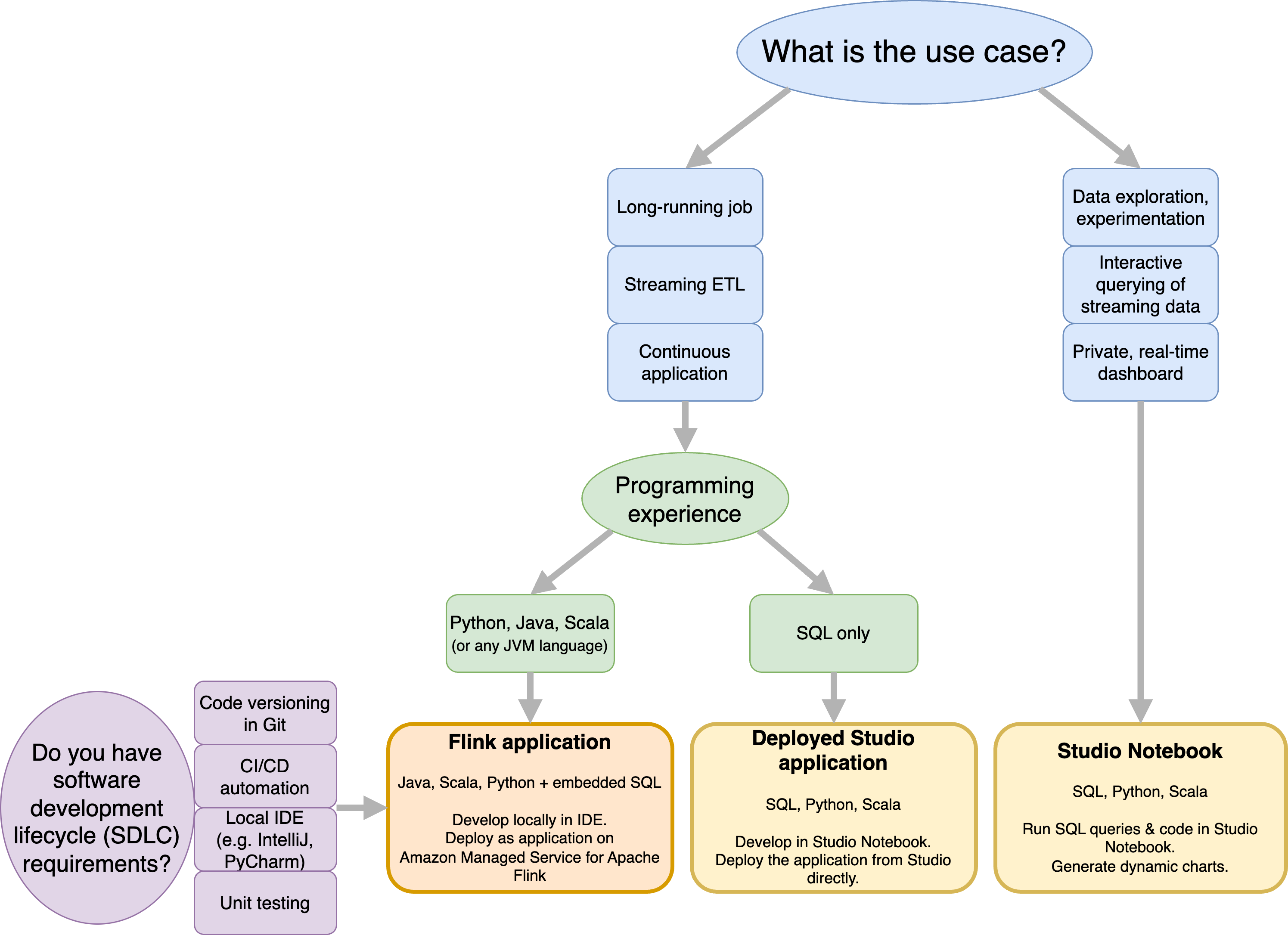
Amazon Managed Service for Apache Flink と Amazon Managed Service for Apache Flink Studio のどちらを使用するかを決定する前に、ユースケースを検討する必要があります。
Streaming ETL や Continuous Applications などのワークロードに対応する長時間稼働のアプリケーションを運用する場合は、Apache Flink 用 Managed Service の使用を検討する必要があります。これは、選択した IDE で Flink APIsを直接使用して Flink アプリケーションを作成できるためです。IDE を使用してローカルで開発することで、Git でのコードバージョニング、CI/CD オートメーション、ユニットテストなどのソフトウェア開発ライフサイクル (SDLC) の一般的なプロセスとツールを活用することもできます。
アドホックデータ探索に関心がある場合、ストリーミングデータをインタラクティブにクエリする場合、またはプライベートリアルタイムダッシュボードを作成する場合、Managed Service for Apache Flink Studio は、数回のクリックでこれらの目標を達成するのに役立ちます。SQL に精通しているユーザーは、Studio から直接長時間実行されるアプリケーションをデプロイすることを検討できます。
注記
Studio ノートブックを長時間実行されるアプリケーションに昇格させることができます。ただし、Git でのコードバージョニングや CI/CD オートメーションなどの SDLC ツールや、ユニットテストなどの手法と統合する場合は、選択した IDE を使用して Apache Flink 用 Managed Service を使用することをお勧めします。
Managed Service for Apache Flink で使用する Apache Flink APIs を選択する
Managed Service for Apache Flink で Java、Python、Scala を使用してアプリケーションを構築できます。選択した IDE で Apache Flink APIs を使用します。Flink Datastream と Table API を使用してアプリケーションを構築する方法に関するガイダンスは、 ドキュメントに記載されています。Flink アプリケーションを作成する言語と、アプリケーションとオペレーションのニーズに合わせて使用する APIs を選択できます。不明な場合は、このセクションで役立つ大まかなガイダンスを提供します。
Flink API を選択する
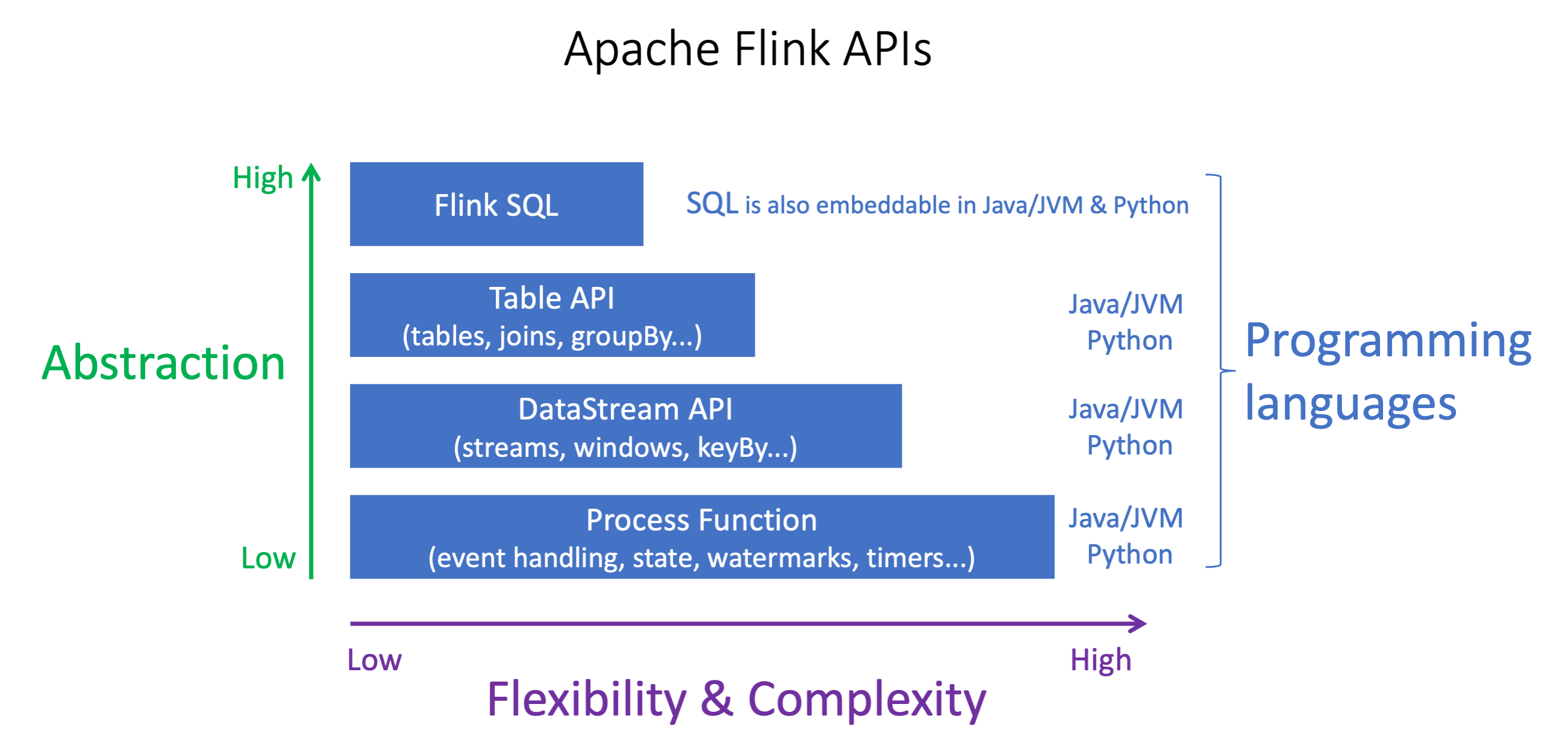
Apache Flink APIs抽象化レベルは異なり、アプリケーションの構築方法に影響する可能性があります。これらは表現力と柔軟性があり、アプリケーションをビルドするために一緒に使用できます。Flink API を 1 つだけ使用する必要はありません。Flink APIs の詳細については、Apache Flink ドキュメント
Flink には、Flink SQL、Table API、DataStream API、Process Function の 4 つのレベルの API 抽象化が用意されています。これらは DataStream API と組み合わせて使用されます。これらはすべて Amazon Managed Service for Apache Flink でサポートされています。可能であれば、より高いレベルの抽象化から始めることをお勧めしますが、一部の Flink 機能は、Java、Python、または Scala でアプリケーションを作成できる Datastream API でのみ使用できます。以下の場合は、Datastream API の使用を検討してください。
状態をきめ細かく制御する必要がある
外部データベースまたはエンドポイントを非同期的に呼び出す機能を活用する (推論など)
カスタムタイマーを使用する (カスタムウィンドウや遅延イベント処理を実装するなど)
-
状態をリセットせずにアプリケーションのフローを変更できるようにする場合
注記
DataStream API を使用した言語の選択:
SQL は、選択したプログラミング言語に関係なく、任意の Flink アプリケーションに埋め込むことができます。
DataStream API の使用を計画している場合、すべてのコネクタが Python でサポートされているわけではありません。
低レイテンシー/高スループットが必要な場合は、API に関係なく Java/Scala を検討する必要があります。
Process Functions API で非同期 IO を使用する場合は、Java を使用する必要があります。
API を選択すると、状態をリセットすることなくアプリケーションロジックを進化させる機能にも影響します。これは、Java と Python の両方の DataStream API でのみ使用できる、演算子に UID を設定する機能である特定の機能によって異なります。詳細については、UUIDs を設定する
ストリーミングデータアプリケーションの使用を開始する
まず、ストリーミングデータを継続的に読み取って処理する Apache Flink アプリケーション用 Managed Service を作成します。次に、選択した IDE を使用してコードを書き、ライブストリーミングデータでテストします。Apache Flink 用 Managed Service で結果を送信する宛先を設定することもできます。
始める前に、以下のセクションを読んでおくことをお勧めします。
または、Apache Flink Studio 用 Managed Service ノートブックを作成して、データストリームをリアルタイムでインタラクティブにクエリし、標準の SQL、Python、Scala を使用してストリーム処理アプリケーションを簡単に構築して実行することもできます。を数回クリックするだけで AWS Management Console、サーバーレスノートブックを起動してデータストリームをクエリし、数秒で結果を取得できます。始める前に、以下のセクションを読んでおくことをお勧めします。
