翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
アルゴリズムイメージの作成
Amazon SageMaker AI アルゴリズムでは、予測を行う前に購入者が独自のデータを持ち込んでトレーニングする必要があります。 AWS Marketplace 販売者は、SageMaker AI を使用して、購入者がデプロイできる機械学習 (ML) アルゴリズムとモデルを作成できます AWS。以下のセクションでは、アルゴリズムイメージを作成する方法について説明します AWS Marketplace。これには、アルゴリズムをトレーニングするための Docker トレーニングイメージと、推論ロジックを含む推論イメージの作成が含まれます。アルゴリズム製品を公開するには、トレーニングイメージと推論イメージの両方が必要です。
概要
アルゴリズムには以下のコンポーネントが含まれています。
-
Amazon ECR
に保存されたトレーニングイメージ -
Amazon Elastic Container Registry (Amazon ECR) に保存された推論イメージ
注記
アルゴリズム製品では、トレーニングコンテナによってモデルアーティファクトが生成され、モデルのデプロイ時に推論コンテナに読み込まれます。
次の図は、アルゴリズム製品を公開して使用するワークフローを示しています。
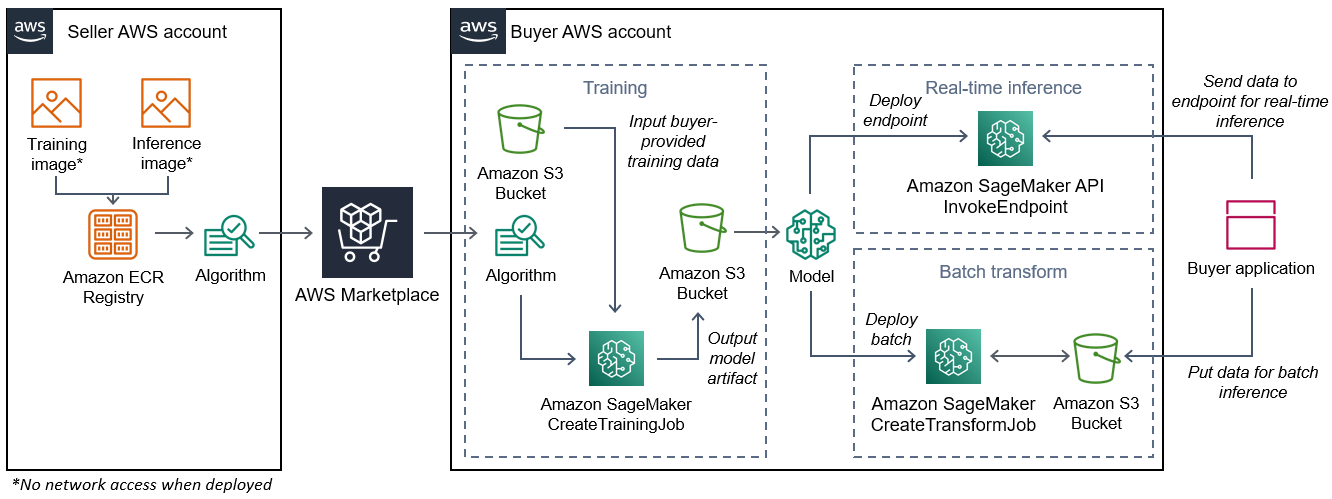
の SageMaker AI アルゴリズムを作成するためのワークフロー AWS Marketplace には、次のステップが含まれます。
-
販売者はトレーニングイメージと推論イメージ (デプロイ時のネットワークアクセス不可) を作成し、Amazon ECR レジストリにアップロードします。
-
次に、販売者は Amazon SageMaker AI でアルゴリズムリソースを作成し、ML 製品を公開します AWS Marketplace。
-
購入者は ML 製品をサブスクライブします。
-
購入者は、互換性のあるデータセットと適切なハイパーパラメータ値を使用してトレーニングジョブを作成します。SageMaker AI はトレーニングイメージを実行し、トレーニングデータとハイパーパラメータをトレーニングコンテナにロードします。トレーニングジョブが完了すると、
/opt/ml/model/にあるモデルアーティファクトが圧縮され、購入者の Amazon S3バケットにコピーされます。 -
購入者は Amazon S3 に保存されているトレーニングのモデルアーティファクトを含むモデルパッケージを作成し、モデルをデプロイします。
-
SageMaker AI は推論イメージを実行し、圧縮されたモデルアーティファクトを抽出して、ファイルを推論コンテナディレクトリパスにロードします。
/opt/ml/model/このパスでは、推論を提供するコードによってファイルが消費されます。 -
モデルがエンドポイントとしてデプロイされるかバッチ変換ジョブとしてデプロイされるかにかかわらず、SageMaker AI は購入者に代わってデータをコンテナの HTTP エンドポイント経由でコンテナに渡し、予測結果を返します。
注記
詳細については、「モデルのトレーニング」を参照してください。
アルゴリズム用のトレーニングイメージの作成
このセクションでは、トレーニングコードをトレーニングイメージにパッケージ化する手順を説明します。アルゴリズム製品を作成するには、トレーニングイメージが必要です。
トレーニングイメージは、トレーニングアルゴリズムを含む Docker イメージです。コンテナは特定のファイル構造に準拠しているため、SageMaker AI はコンテナとの間でデータをコピーできます。
アルゴリズム製品を公開する際は、トレーニングイメージと推論イメージの両方が必要です。トレーニングイメージを作成したら、推論イメージを作成する必要があります。2 つのイメージは 1 つのイメージに結合することも、個別のイメージのままにしておくこともできます。イメージを結合するか個別のイメージのままにするかは、ユーザーしだいです。通常、推論は学習よりも単純です。イメージを結合せずに個別のイメージのままにすると、推論のパフォーマンスが向上することがあります。
注記
以下は、トレーニングイメージのパッケージコードの一例です。詳細については、GitHub の「 で独自のアルゴリズムとモデル AWS Marketplaceを使用する」およびAWS Marketplace SageMaker AI の例
ステップ 1: コンテナイメージを作成する
トレーニングイメージを Amazon SageMaker AI と互換性を持たせるには、SageMaker AI がトレーニングデータと設定入力をコンテナ内の特定のパスにコピーできるように、特定のファイル構造に従う必要があります。トレーニングが完了すると、生成されたモデルアーティファクトは、SageMaker AI がコピーするコンテナ内の特定のディレクトリパスに保存されます。
以下では、Linux の Ubuntu ディストリビューションの開発環境にインストールされた Docker CLI が使用されています。
設定入力を読み取れるようプログラムを準備します。
トレーニングプログラムで購入者提供の設定入力が必要な場合は、実行時に以下がコンテナ内にコピーされます。必要に応じて、プログラムはこれらの特定のファイルパスから読み取りを行う必要があります。
-
/opt/ml/input/configは、プログラムの実行方法を制御する情報が保存されているディレクトリです。-
hyperparameters.jsonは、ハイパーパラメータ名とハイパーパラメータ値の、JSON 形式の辞書です。値は文字列のため、変換が必要になる場合があります。 -
resourceConfig.jsonは JSON 形式のファイルで、分散型トレーニングに使用されるネットワークレイアウトを記述しています。トレーニングイメージが分散型トレーニングをサポートしていない場合、このファイルは無視してかまいません。
-
注記
設定入力の詳細については、Amazon SageMakerがトレーニング情報を提供する方法」を参照してください。
データ入力を読み取れるようプログラムを準備します。
トレーニングデータは、次の 2 つのモードのいずれかでコンテナに渡すことができます。コンテナ内で実行されるトレーニングプログラムは、これら 2 つのモードのいずれかでトレーニングデータのダイジェストを作成します。
ファイルモード
-
/opt/ml/input/data/<channel_name>/にそのチャネルの入力データが含まれます。チャネルはCreateTrainingJobオペレーションの呼び出しに基づいて作成されますが、一般的にはアルゴリズムが期待するものとチャネルが一致することが重要です。各チャネルのファイルは Amazon S3からこのディレクトリにコピーされ、Amazon S3 のキー構造によって示されるツリー構造が保持されます。
パイプモード
-
/opt/ml/input/data/<channel_name>_<epoch_number>は特定のエポックのパイプです。エポックは 0 から始まり、読み込まれるたびに 1 ずつ増えていきます。実行できるエポックの数に制限はありませんが、次のエポックを読み込む前に各パイプを閉じる必要があります。
トレーニング出力を書き込めるようプログラムを準備します。
トレーニングの出力は次のコンテナディレクトリに書き込まれます。
-
/opt/ml/model/はトレーニングアルゴリズムが生成するモデルまたはモデルアーティファクトが書き込まれるディレクトリです。モデルはどのような形式でもかまいません。1 つのファイルでもディレクトリツリー全体でもかまいません。SageMaker AI は、このディレクトリ内のすべてのファイルを圧縮ファイル (.tar.gz) にパッケージ化します。このファイルは、DescribeTrainingJobAPI オペレーションによって返される、Amazon S3 の場所にあります。 -
/opt/ml/output/は、ジョブが失敗した理由が記述されたfailureファイルをアルゴリズムが書き込むことができるディレクトリです。このファイルの内容はDescribeTrainingJobの結果のFailureReasonフィールドに返されます。ジョブが成功してもこのファイルは無視されるため、このファイルを書き込む理由はありません。
コンテナ実行用のスクリプトを作成する
Docker コンテナイメージの実行時に SageMaker AI が実行するtrainシェルスクリプトを作成します。トレーニングが完了し、モデルアーティファクトがそれぞれのディレクトリに書き込まれたら、スクリプトを終了します。
./train
#!/bin/bash # Run your training program here # # # #
Dockerfile の作成
ビルドコンテキストに Dockerfile を作成します。この例ではベースイメージとして Ubuntu 18.04 を使用していますが、フレームワークに適していれば、どのベースイメージからでも開始できます。
./Dockerfile
FROM ubuntu:18.04 # Add training dependencies and programs # # # # # # Add a script that SageMaker AI will run # Set run permissions # Prepend program directory to $PATH COPY /train /opt/program/train RUN chmod 755 /opt/program/train ENV PATH=/opt/program:${PATH}
Dockerfile は以前に作成した train スクリプトをイメージに追加します。スクリプトのディレクトリが PATH に追加され、コンテナの実行時にスクリプトを実行できるようになります。
前の例には、実際のトレーニングロジックはありません。実際のトレーニングイメージでは、トレーニングの依存関係を Dockerfile に追加し、トレーニング入力を読み取るロジックを追加してトレーニングを行い、モデルアーティファクトを生成します。
トレーニングイメージはインターネットにアクセスできないため、必要な依存関係がすべて含まれている必要があります。
詳細については、GitHub の「 で独自のアルゴリズムとモデル AWS Marketplaceを使用する」およびAWS Marketplace SageMaker AI の例
ステップ 2: イメージをローカルでビルドしてテストする
ビルドコンテキストには、現在、以下のファイルが存在します。
-
./Dockerfile -
./train -
トレーニングの依存関係とロジック
次に、このコンテナイメージをビルド、実行、テストできます。
イメージを構築する
ビルドコンテキストで Docker コマンドを実行し、イメージをビルドしてタグ付けします。この例ではタグ my-training-image を使用します。
sudo docker build --tag my-training-image ./
この Docker コマンドを実行してイメージをビルドすると、Dockerfile の各行に基づいて Docker がイメージをビルドするときの出力が表示されます。終了すると、次のようなものが表示されます。
Successfully built abcdef123456
Successfully tagged my-training-image:latestをローカルで実行する
完了したら、次の例に示すようにイメージをローカルでテストします。
sudo docker run \ --rm \ --volume '<path_to_input>:/opt/ml/input:ro' \ --volume '<path_to_model>:/opt/ml/model' \ --volume '<path_to_output>:/opt/ml/output' \ --name my-training-container \ my-training-image \ train
コマンドの詳細は次のとおりです。
-
--rm- コンテナが停止したら自動的に削除します。 -
--volume '<path_to_input>:/opt/ml/input:ro'- テスト入力ディレクトリをコンテナが読み取り専用で使用できるようにします。 -
--volume '<path_to_model>:/opt/ml/model'- トレーニングテストが完了したら、モデルアーティファクトが保存されているパスをホストマシンでバインドマウントします。 -
--volume '<path_to_output>:/opt/ml/output'- 障害理由が書き込まれるfailureファイル内のパスをホストマシンでバインドマウントします。 -
--name my-training-container- 実行中のこのコンテナに名前を付けます。 -
my-training-image- ビルドされたイメージを実行します。 -
train– コンテナの実行時に SageMaker AI が実行するのと同じスクリプトを実行します。
このコマンドを実行すると、Docker は、ビルドされたトレーニングイメージからコンテナを作成して実行します。コンテナは train スクリプトを実行します。これで、トレーニングプログラムが起動します。
トレーニングプログラムが終了し、コンテナが終了したら、出力モデルのアーティファクトが正しいことを確認します。さらに、ログ出力をチェックして、トレーニングジョブに関する十分な情報が提供されていることを確認し、併せて、不要なログが生成されていないことを確認します。
これで、アルゴリズム製品用のトレーニングコードのパッケージ化が完了しました。アルゴリズム製品には推論イメージも含まれるため、次のセクション、「 アルゴリズムの推論イメージの作成」に進んでください。
アルゴリズムの推論イメージの作成
このセクションでは、推論コードをアルゴリズム製品の推論イメージにパッケージ化する手順を説明します。
推論イメージは、推論ロジックを含む Docker イメージです。実行時にコンテナは HTTP エンドポイントを公開し、SageMaker AI がコンテナとの間でデータをやり取りできるようにします。
アルゴリズム製品を公開する際は、トレーニングイメージと推論イメージの両方が必要です。これをまだ確認していない場合は、「アルゴリズム用のトレーニングイメージの作成」に関する前のセクションを参照してください。2 つのイメージは 1 つのイメージに結合することも、個別のイメージのままにしておくこともできます。イメージを結合するか個別のイメージのままにするかは、ユーザーしだいです。通常、推論は学習よりも単純です。イメージを結合せずに個別のイメージのままにすると、推論のパフォーマンスが向上することがあります。
注記
以下は、推論イメージのパッケージコードの一例です。詳細については、GitHub の「 で独自のアルゴリズムとモデル AWS Marketplaceを使用する」およびAWS Marketplace SageMaker AI の例
以下の例ではわかりやすくするために Flask
ステップ 1: 推論イメージを作成する
推論イメージを SageMaker AI と互換性を持たせるには、Docker イメージが HTTP エンドポイントを公開する必要があります。コンテナの実行中、SageMaker AI は購入者から提供された推論の入力をコンテナの HTTP エンドポイントに渡します。推論の結果は HTTP レスポンスの本文で返されます。
以下では、Linux の Ubuntu ディストリビューションの開発環境にインストールされた Docker CLI が使用されています。
ウェブサーバースクリプトを作成する
この例では Flask
注記
ここではわかりやすくするために Flask
SageMaker AI が使用する TCP ポート 8080 で 2 つの HTTP エンドポイントを提供する Flask ウェブサーバースクリプトを作成します。想定されるエンドポイントは次の 2 つです。
-
/ping– SageMaker AI はこのエンドポイントに HTTP GET リクエストを行い、コンテナの準備が整っているかどうかを確認します。コンテナの準備が完了すると、コンテナはこのエンドポイントでの HTTP GET リクエストに HTTP 200 レスポンスコードで応答します。 -
/invocations– SageMaker AI は、推論のためにこのエンドポイントに HTTP POST リクエストを行います。推論用の入力データはリクエストの本文で送信されます。ユーザー指定のコンテンツタイプは HTTP ヘッダーで渡されます。レスポンスの本文は推論出力です。
./web_app_serve.py
# Import modules import json import re from flask import Flask from flask import request app = Flask(__name__) # Create a path for health checks @app.route("/ping") def endpoint_ping(): return "" # Create a path for inference @app.route("/invocations", methods=["POST"]) def endpoint_invocations(): # Read the input input_str = request.get_data().decode("utf8") # Add your inference code here. # # # # # # Add your inference code here. # Return a response with a prediction response = {"prediction":"a","text":input_str} return json.dumps(response)
前の例には、実際の推論ロジックはありません。実際の推論イメージについては、ウェブアプリに推論ロジックを追加し、入力を処理して予測を返します。
推論イメージはインターネットにアクセスできないため、必要な依存関係がすべて含まれている必要があります。
コンテナ実行用のスクリプトを作成する
Docker コンテナイメージの実行時に SageMaker AI serveが実行する という名前のスクリプトを作成します。このスクリプトでは、HTTP ウェブサーバーを起動します。
./serve
#!/bin/bash # Run flask server on port 8080 for SageMaker AI flask run --host 0.0.0.0 --port 8080
Dockerfile の作成
ビルドコンテキストに Dockerfile を作成します。この例では Ubuntu 18.04 を使用していますが、フレームワークに適していれば、どのベースイメージからでも開始できます。
./Dockerfile
FROM ubuntu:18.04 # Specify encoding ENV LC_ALL=C.UTF-8 ENV LANG=C.UTF-8 # Install python-pip RUN apt-get update \ && apt-get install -y python3.6 python3-pip \ && ln -s /usr/bin/python3.6 /usr/bin/python \ && ln -s /usr/bin/pip3 /usr/bin/pip; # Install flask server RUN pip install -U Flask; # Add a web server script to the image # Set an environment to tell flask the script to run COPY /web_app_serve.py /web_app_serve.py ENV FLASK_APP=/web_app_serve.py # Add a script that Amazon SageMaker AI will run # Set run permissions # Prepend program directory to $PATH COPY /serve /opt/program/serve RUN chmod 755 /opt/program/serve ENV PATH=/opt/program:${PATH}
Dockerfile は以前に作成した 2 つのスクリプトをイメージに追加します。serve スクリプトのディレクトリが PATH に追加されると、コンテナの実行時にそれを実行できるようになります。
モデルアーティファクトを動的に読み込むためのプログラムを準備する
アルゴリズム製品の場合、購入者は独自のデータセットとトレーニングイメージを使用して、独自のモデルアーティファクトを生成します。トレーニングプロセスが完了すると、トレーニングコンテナはモデルアーティファクトをコンテナディレクトリ
/opt/ml/model/ に出力します。SageMaker AI は、そのディレクトリ内のコンテンツを .tar.gz ファイルに圧縮し、Amazon S3 の購入者の AWS アカウント に保存します。
モデルがデプロイされると、SageMaker AI は推論イメージを実行し、Amazon S3 の購入者のアカウントに保存されている .tar.gz ファイルからモデルアーティファクトを抽出し、 /opt/ml/model/ ディレクトリの推論コンテナにロードします。実行時、推論コンテナコードはモデルデータを使用します。
注記
モデルアーティファクトファイルに含まれる可能性のある知的財産を保護するために、ファイル出力前の暗号化を選択できます。詳細については、「Amazon SageMaker AI のセキュリティと知的財産」を参照してください。
ステップ 2: イメージをローカルでビルドしてテストする
ビルドコンテキストには、現在、以下のファイルが存在します。
-
./Dockerfile -
./web_app_serve.py -
./serve
次に、このコンテナイメージをビルド、実行、テストできます。
イメージを構築する
Docker コマンドを実行し、イメージをビルドしてタグ付けします。この例ではタグ my-inference-image を使用します。
sudo docker build --tag my-inference-image ./
この Docker コマンドを実行してイメージをビルドすると、Dockerfile の各行に基づいて Docker がイメージをビルドするときの出力が表示されます。終了すると、次のようなものが表示されます。
Successfully built abcdef123456
Successfully tagged my-inference-image:latestをローカルで実行する
ビルドが完了したら、イメージをローカルでテストできます。
sudo docker run \ --rm \ --publish 8080:8080/tcp \ --volume '<path_to_model>:/opt/ml/model:ro' \ --detach \ --name my-inference-container \ my-inference-image \ serve
コマンドの詳細は次のとおりです。
-
--rm- コンテナが停止したら自動的に削除します。 -
--publish 8080:8080/tcp– ポート 8080 を公開して、SageMaker AI が HTTP リクエストを送信するポートをシミュレートします。 -
--volume '<path_to_model>:/opt/ml/model:ro'- テストモデルアーティファクトが保存されているホストマシン上のパスを、コンテナ内の推論コードで使用できるよう読み取り専用としてバインドマウントします。 -
--detach- コンテナをバックグラウンドで実行します。 -
--name my-inference-container- 実行中のこのコンテナに名前を付けます。 -
my-inference-image- ビルドされたイメージを実行します。 -
serve– コンテナの実行時に SageMaker AI が実行するのと同じスクリプトを実行します。
このコマンドを実行すると、Docker は、推論イメージからコンテナを作成してバックグラウンドで実行します。コンテナは serve スクリプトを実行し、テスト目的でウェブサーバーを起動します。
HTTP エンドポイントへの ping をテストします。
SageMaker AI がコンテナを実行すると、定期的にエンドポイントに ping を送信します。エンドポイントがステータスコード 200 の HTTP レスポンスを返すと、コンテナが推論の準備ができていることを SageMaker AI に通知します。
次のコマンドを実行してエンドポイントをテストし、レスポンスヘッダーを含めます。
curl --include http://127.0.0.1:8080/ping
以下の例に、出力例を示します。
HTTP/1.0 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 0
Server: MyServer/0.16.0 Python/3.6.8
Date: Mon, 21 Oct 2019 06:58:54 GMT推論 HTTP エンドポイントをテストします。
コンテナが 200 ステータスコードを返すことで準備が整っていることを示すと、SageMaker AI はPOSTリクエストを介して推論データを /invocations HTTP エンドポイントに渡します。
以下のコマンドを実行して、推論エンドポイントをテストします。
curl \ --request POST \ --data "hello world" \ http://127.0.0.1:8080/invocations
以下の例に、出力例を示します。
{"prediction": "a", "text": "hello world"}これら 2 つの HTTP エンドポイントが機能するので、推論イメージは SageMaker AI と互換性があります。
注記
アルゴリズム製品のモデルは、リアルタイムとバッチの 2 つの方法でデプロイできます。どちらのデプロイでも、SageMaker AI は Docker コンテナの実行中に同じ HTTP エンドポイントを使用します。
コンテナを停止するには、次のコマンドを実行します。
sudo docker container stop my-inference-container
アルゴリズム製品のトレーニングイメージと推論イメージの両方の準備とテストが完了したら、「Amazon Elastic Container Registry へのイメージのアップロード」に進みます。
