Model training
The training stage of the full machine learning (ML) lifecycle spans from accessing your training dataset to generating a final model and selecting the best performing model for deployment. The following sections provide an overview of available SageMaker training features and resources with in-depth technical information for each.
The basic architecture of SageMaker Training
If you’re using SageMaker AI for the first time and want to find a quick ML solution to train a model on your dataset, consider using a no-code or low-code solution such as SageMaker Canvas, JumpStart within SageMaker Studio Classic, or SageMaker Autopilot.
For intermediate coding experiences, consider using a SageMaker Studio Classic notebook or SageMaker Notebook Instances. To get started, follow the instructions at Train a Model of the SageMaker AI Getting Started guide. We recommend this for use cases in which you create your own model and training script using an ML framework.
The core of SageMaker AI jobs is the containerization of ML workloads and the capability of managing compute resources. The SageMaker Training platform takes care of the heavy lifting associated with setting up and managing infrastructure for ML training workloads. With SageMaker Training, you can focus on developing, training, and fine-tuning your model.
The following architecture diagram shows how SageMaker AI manages ML training jobs and provisions Amazon EC2 instances on behalf of SageMaker AI users. You as a SageMaker AI user can bring your own training dataset, saving it to Amazon S3. You can choose an ML model training from available SageMaker AI built-in algorithms, or bring your own training script with a model built with popular machine learning frameworks.

Full view of the SageMaker Training workflow and features
The full journey of ML training involves tasks beyond data ingestion to ML models, training models on compute instances, and obtaining model artifacts and outputs. You need to evaluate every phase of before, during, and after training to make sure your model is trained well to meet the target accuracy for your objectives.
The following flow chart shows a high-level overview of your actions (in blue boxes) and available SageMaker Training features (in light blue boxes) throughout the training phase of the ML lifecycle.
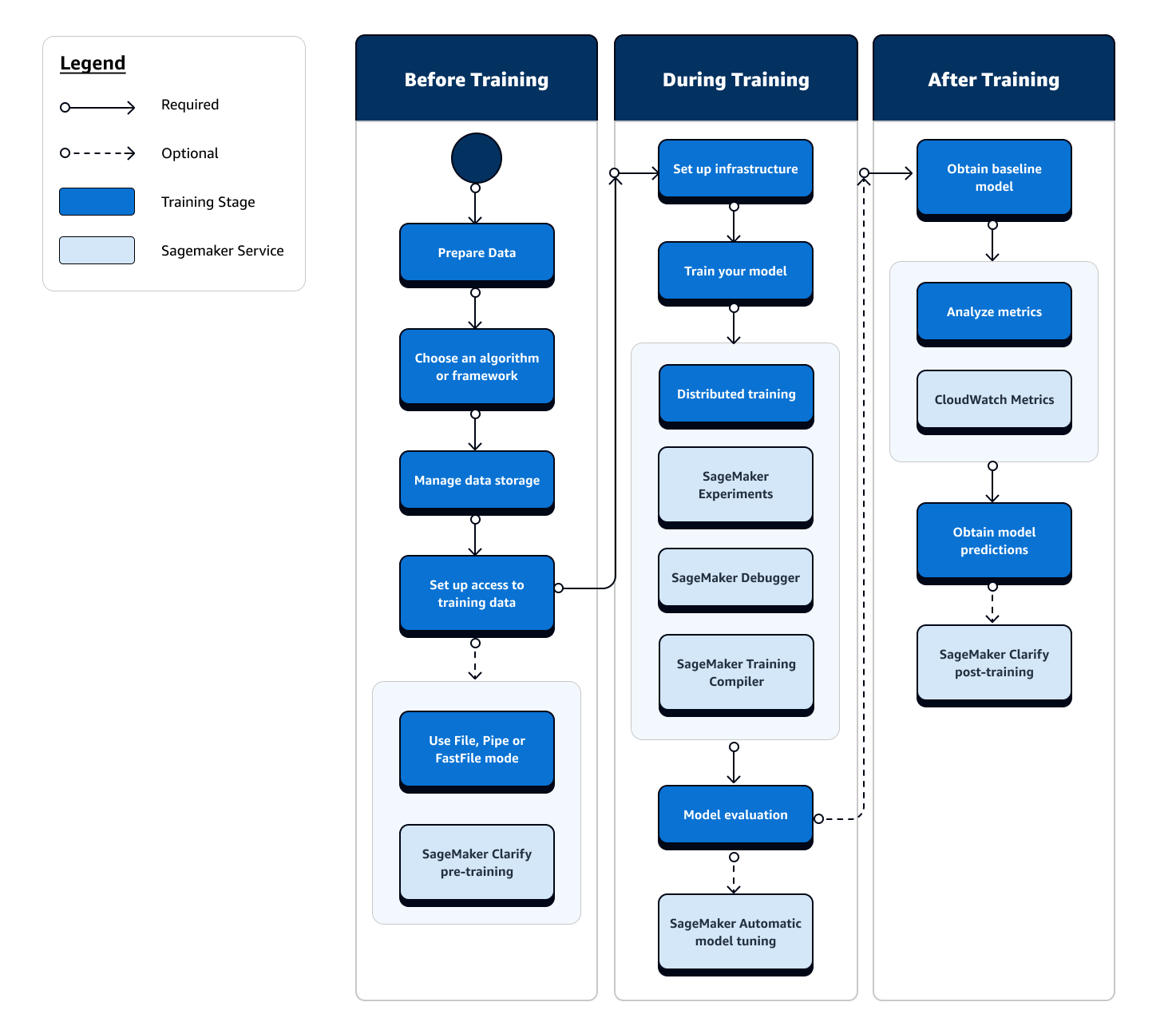
The following sections walk you through each phase of training depicted in the previous flow chart and useful features offered by SageMaker AI throughout the three sub-stages of the ML training.
Before training
There are a number of scenarios of setting up data resources and access you need to consider before training. Refer to the following diagram and details of each before-training stage to get a sense of what decisions you need to make.
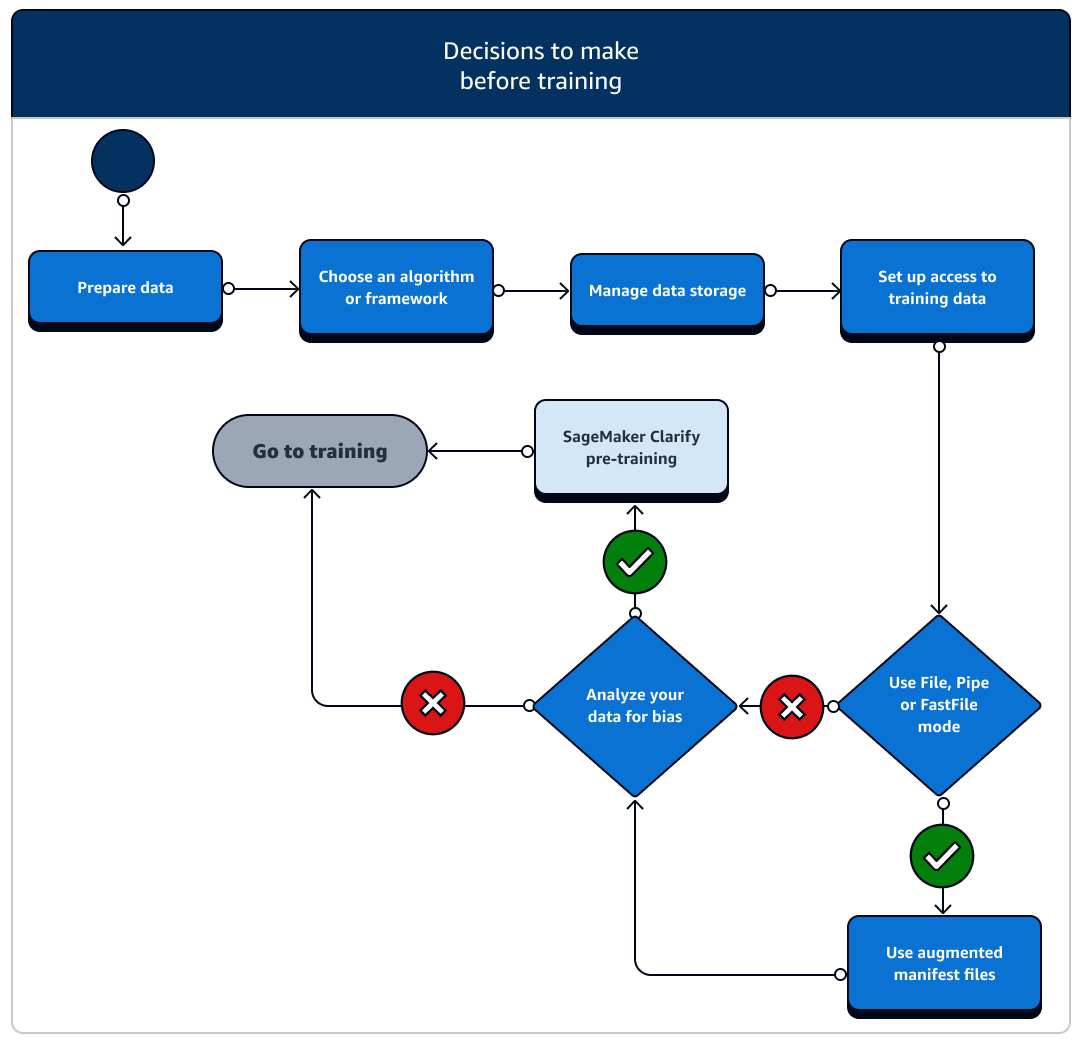
-
Prepare data: Before training, you must have finished data cleaning and feature engineering during the data preparation stage. SageMaker AI has several labeling and feature engineering tools to help you. See Label Data, Prepare and Analyze Datasets, Process Data, and Create, Store, and Share Features for more information.
-
Choose an algorithm or framework: Depending on how much customization you need, there are different options for algorithms and frameworks.
-
If you prefer a low-code implementation of a pre-built algorithm, use one of the built-in algorithms offered by SageMaker AI. For more information, see Choose an Algorithm.
-
If you need more flexibility to customize your model, run your training script using your preferred frameworks and toolkits within SageMaker AI. For more information, see ML Frameworks and Toolkits.
-
To extend pre-built SageMaker AI Docker images as the base image of your own container, see Use Pre-built SageMaker AI Docker images.
-
To bring your custom Docker container to SageMaker AI, see Adapting your own Docker container to work with SageMaker AI. You need to install the sagemaker-training-toolkit
to your container.
-
-
Manage data storage: Understand mapping between the data storage (such as Amazon S3, Amazon EFS, or Amazon FSx) and the training container that runs in the Amazon EC2 compute instance. SageMaker AI helps map the storage paths and local paths in the training container. You can also manually specify them. After mapping is done, consider using one of the data transmission modes: File, Pipe, and FastFile mode. To learn how SageMaker AI maps storage paths, see Training Storage Folders.
-
Set up access to training data: Use Amazon SageMaker AI domain, a domain user profile, IAM, Amazon VPC, and AWS KMS to meet the requirements of the most security-sensitive organizations.
-
For account administration, see Amazon SageMaker AI domain.
-
For a complete reference about IAM policies and security, see Security in Amazon SageMaker AI.
-
-
Stream your input data: SageMaker AI provides three data input modes, File, Pipe, and FastFile. The default input mode is File mode, which loads the entire dataset during initializing the training job. To learn about general best practices for streaming data from your data storage to the training container, see Access Training Data.
In case of Pipe mode, you can also consider using an augmented manifest file to stream your data directly from Amazon Simple Storage Service (Amazon S3) and train your model. Using pipe mode reduces disk space because Amazon Elastic Block Store only needs to store your final model artifacts, rather than storing your full training dataset. For more information, see Provide Dataset Metadata to Training Jobs with an Augmented Manifest File.
-
Analyze your data for bias: Before training, you can analyze your dataset and model for bias against a disfavored group so that you can check that your model learns an unbiased dataset using SageMaker Clarify.
-
Choose which SageMaker SDK to use: There are two ways to launch a training job in SageMaker AI: using the high-level SageMaker AI Python SDK, or using the low-level SageMaker APIs for the SDK for Python (Boto3) or the AWS CLI. The SageMaker Python SDK abstracts the low-level SageMaker API to provide convenient tools. As aforementioned in The basic architecture of SageMaker Training, you can also pursue no-code or minimal-code options using SageMaker Canvas, JumpStart within SageMaker Studio Classic, or SageMaker AI Autopilot.
During training
During training, you need to continuously improve training stability, training speed, training efficiency while scaling compute resources, cost optimization, and, most importantly, model performance. Read on for more information about during-training stages and relevant SageMaker Training features.
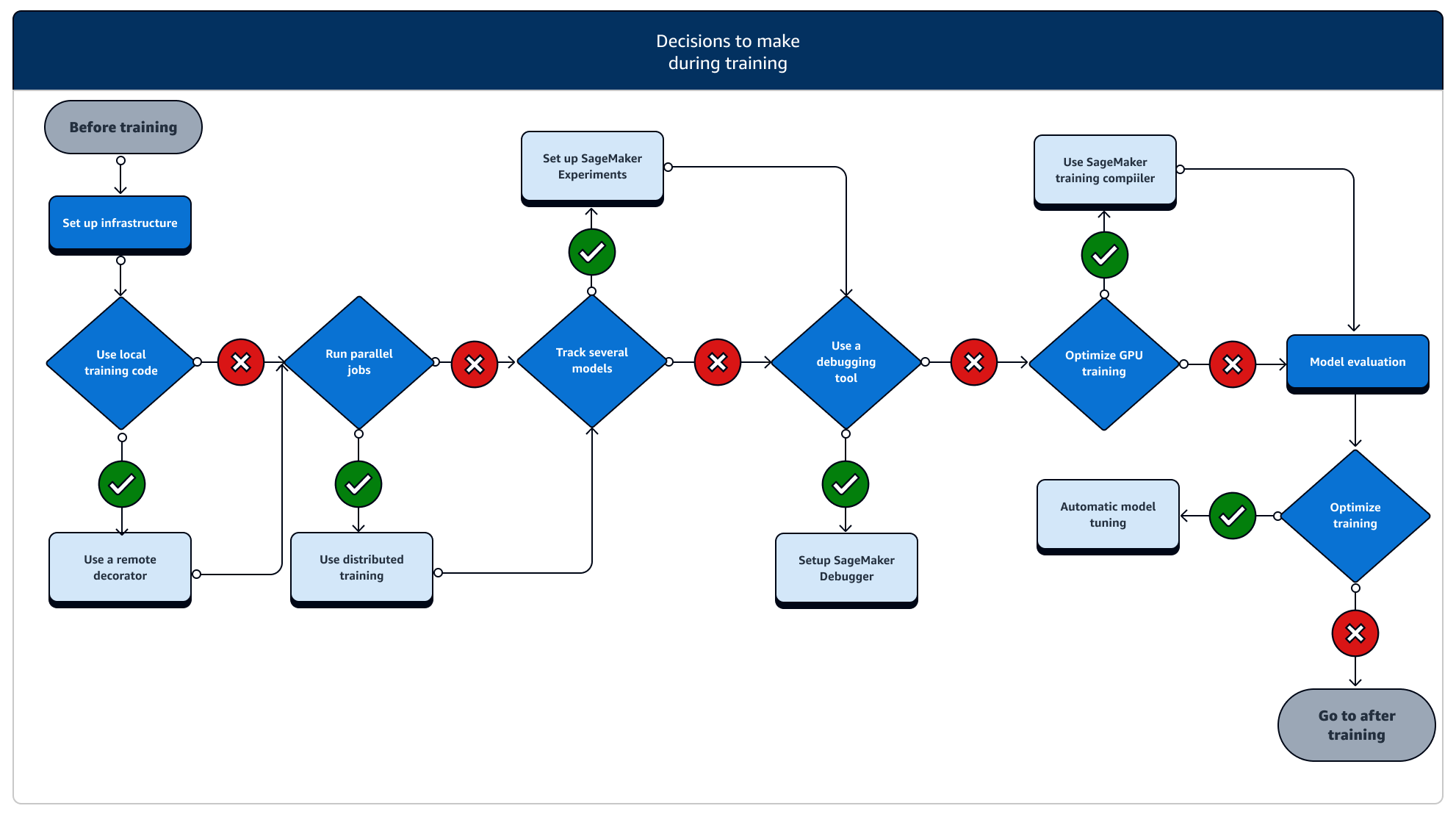
-
Set up infrastructure: Choose the right instance type and infrastructure management tools for your use case. You can start from a small instance and scale up depending on your workload. For training a model on a tabular dataset, start with the smallest CPU instance of the C4 or C5 instance families. For training a large model for computer vision or natural language processing, start with the smallest GPU instance of the P2, P3, G4dn or G5 instance families. You can also mix different instance types in a cluster, or keep instances in warm pools using the following instance management tools offered by SageMaker AI. You can also use persistent cache to reduce latency and billable time on iterative training jobs over the latency reduction from warm pools alone. To learn more, see the following topics.
You must have sufficient quota to run a training job. If you run your training job on an instance where you have insufficient quota, you will receive a
ResourceLimitExceedederror. To check the currently available quotas in your account, use your Service Quotas console. To learn how to request a quota increase, see Supported Regions and Quotas. Also, to find pricing information and available instance types depending on the AWS Regions, look up the tables in the Amazon SageMaker Pricing page. -
Run a training job from a local code: You can annotate your local code with a remote decorator to run your code as a SageMaker training job from inside Amazon SageMaker Studio Classic, an Amazon SageMaker notebook or from your local integrated development environment. For more information, see Run your local code as a SageMaker training job.
-
Track training jobs: Monitor and track your training jobs using SageMaker Experiments, SageMaker Debugger, or Amazon CloudWatch. You can watch the model performance in terms of accuracy and convergence, and run comparative analysis of metrics between multiple training jobs by using SageMaker AI Experiments. You can watch the compute resource utilization rate by using SageMaker Debugger’s profiling tools or Amazon CloudWatch. To learn more, see the following topics.
Additionally, for deep learning tasks, use the Amazon SageMaker Debugger model debugging tools and built-in rules to identify more complex issues in model convergence and weight update processes.
-
Distributed training: If your training job is going into a stable stage without breaking due to misconfiguration of the training infrastructure or out-of-memory issues, you might want to find more options to scale your job and run over an extended period of time for days and even months. When you’re ready to scale up, consider distributed training. SageMaker AI provides various options for distributed computation from light ML workloads to heavy deep learning workloads.
For deep learning tasks that involve training very large models on very large datasets, consider using one of the SageMaker AI distributed training strategies to scale up and achieve data parallelism, model parallelism, or a combination of the two. You can also use SageMaker Training Compiler for compiling and optimizing model graphs on GPU instances. These SageMaker AI features support deep learning frameworks such as PyTorch, TensorFlow, and Hugging Face Transformers.
-
Model hyperparameter tuning: Tune your model hyperparameters using Automatic Model Tuning with SageMaker AI. SageMaker AI provides hyperparameter tuning methods such as grid search and Bayesian search, launching parallel hyperparameter tuning jobs with early-stopping functionality for non-improving hyperparameter tuning jobs.
-
Checkpointing and cost saving with Spot instances: If training time is not a big concern, you might consider optimizing model training costs with managed Spot instances. Note that you must activate checkpointing for Spot training to keep restoring from intermittent job pauses due to Spot instance replacements. You can also use the checkpointing functionality to back up your models in case of unexpected training job termination. To learn more, see the following topics.
After training
After training, you obtain a final model artifact to use for model deployment and inference. There are additional actions involved in the after-training phase as shown in the following diagram.
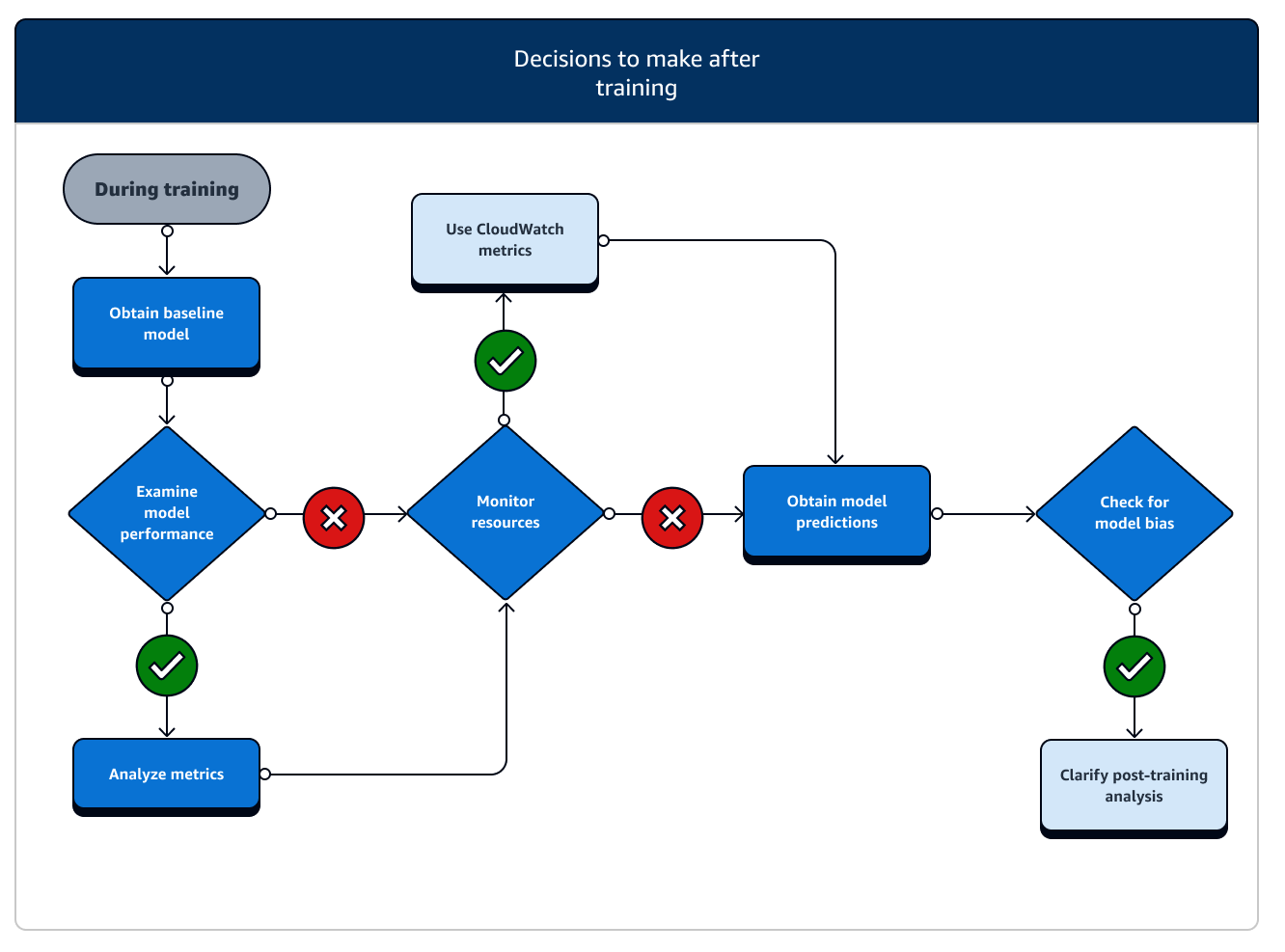
-
Obtain baseline model: After you have the model artifact, you can set it as a baseline model. Consider the following post-training actions and using SageMaker AI features before moving on to model deployment to production.
-
Examine model performance and check for bias: Use Amazon CloudWatch Metrics and SageMaker Clarify for post-training bias to detect any bias in incoming data and model over time against the baseline. You need to evaluate your new data and model predictions against the new data regularly or in real time. Using these features, you can receive alerts about any acute changes or anomalies, as well as gradual changes or drifts in data and model.
-
You can also use the Incremental Training functionality of SageMaker AI to load and update your model (or fine-tune) with an expanded dataset.
-
You can register model training as a step in your SageMaker AI Pipeline or as part of other Workflow features offered by SageMaker AI in order to orchestrate the full ML lifecycle.
