翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
処理フェーズ
Amazon Textract は PDF ファイルのコンテンツを、ダウンストリームアプリケーションで直接使用できない文字列として抽出します (たとえば、数値を集計して統計を生成)。ダウンストリームアプリケーションでより簡単に使用できるため (たとえば、コスト傾向を時系列としてプロットするため)、正しく識別および変換されたデータ値が必要です。PDF ファイル処理を実装するには、新しい PDF ファイルタイプごとに 1 つの PDF ファイルを Amazon Textract を介して 1 回処理し、JSON 形式のTemplateファイルを生成する必要があります。
AWS Lambda 関数が で開始されると取り込みフェーズ、次の図に示すステップが実行されます。
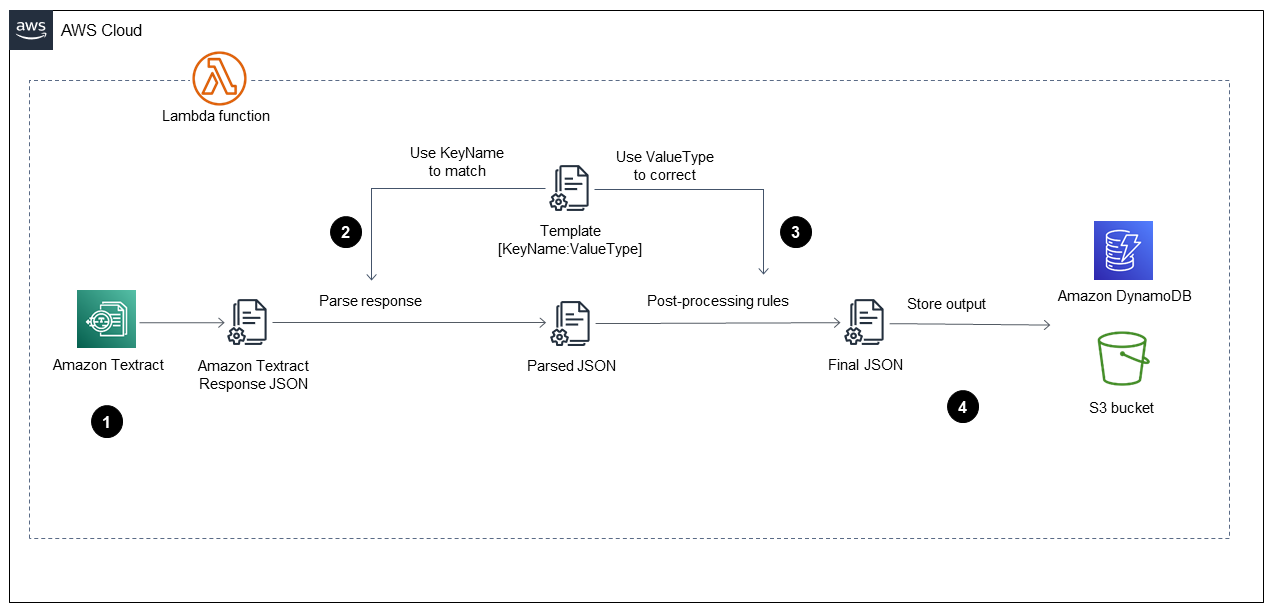
この図は、次の手順を実装する Lambda 関数を示しています。
-
Amazon Textract を呼び出して PDF ファイルを処理し、コンテンツを抽出して、JSON 形式のファイルを返します。
-
JSON ファイルを取得し、各フィールドに正しいキー名と値タイプを持つ事前定義された
TemplateJSON ファイルを使用してフォームとテーブルを解析します。このプロセスでは、解析された JSON ファイルが提供されます。 -
後処理ルールを適用し、JSON ファイルを使用して解析された
TemplateJSON ファイルの各値を修正します。これによりFinal、JSON ファイルが生成されます。事前定義された JSONTemplateファイルは S3 バケットに保存できます。 -
S3 出力バケット内の PDF ファイルごとに
Final1 つの JSON ファイルに加えて、JSON ファイルを各 PDF ファイルに 1 つのレコードとして Amazon DynamoDB に保存します。
Amazon Textract を使用して PDF ファイルからコンテンツを自動的に抽出し、クリーンな出力に加工するstep-by-stepのワークフローについては、 AWS 「規範ガイダンス」ウェブサイトの「Amazon Textract を使用して PDF ファイルからコンテンツを自動的に抽出する」のパターンを参照してください。このパターンでは、テンプレートマッチング技術を使用して必要なフィールド、キー名、テーブルを正しく識別し、各データタイプに後処理による修正を適用します。
処理フェーズのベストプラクティス
次の 4 つのベストプラクティスを使用して、処理フェーズを確実に成功させます。
-
処理する PDF ファイルタイプごとにテンプレート JSON ファイルを作成します。これらのさまざまなテンプレート JSON ファイルは、Lambda 関数によって呼び出される S3 バケットに保存できます。1 つの Lambda 関数で異なる PDF ファイルタイプを処理する場合は、PDF ファイルタイプごとに一意の識別子 (S3 バケット内の PDF ファイルタイプのフォルダ名など) を使用する必要があります。Lambda 関数が呼び出されると、適切なテンプレート JSON ファイルを取得して処理します。
-
Lambda 関数の各ステップのステータスを正確に追跡するメカニズムを設定します。例えば、Amazon Textract 呼び出しの後、最終的な JSON ファイルが Amazon DynamoDB テーブルに保存されたとき、または PDF ファイルが S3 バケットに保存されたときに、
Successのステータスを追加できます。個別の DynamoDB テーブルを作成して、さまざまなステップの各 PDF ファイルのステータスを追跡することもできます。これにより、プロセスが可視化されます。 -
多数の PDF ファイルをバッチ処理するときに、失敗したオペレーションを自動的に再試行することで、スロットリングと削除された接続を管理します。接続が切断された場合、または 1 秒あたりのトランザクション (TPS) の最大数を超えた場合、Amazon Textract でスロットリングが発生する可能性があります。失敗したオペレーションを自動的に再試行する詳細と手順については、Amazon Textract ドキュメントの「スロットリングされた呼び出しとドロップされた接続の処理」を参照してください。
-
複数のページを含む PDF ファイルがある場合は、非同期オペレーションを使用してファイル全体を処理するか、PDF ファイルを個々のページに分割し、同期オペレーションを使用して各ページを処理し、各ページの結果を組み合わせることができます。非同期オペレーションの完全なコード実装については、Amazon Textract ドキュメントの「複数ページのドキュメント内のテキストの検出と分析」を参照してください。同期オペレーションの使用の詳細については、Amazon Textract ドキュメントの「単一ページのドキュメント内のテキストの検出と分析」を参照してください。
