翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
輸送需要を予測するためのアーキテクチャ
次の図は、データの取り込み、データ準備、モデル構築、最終出力とモニタリングなど、ソリューションのワークフローを示しています。
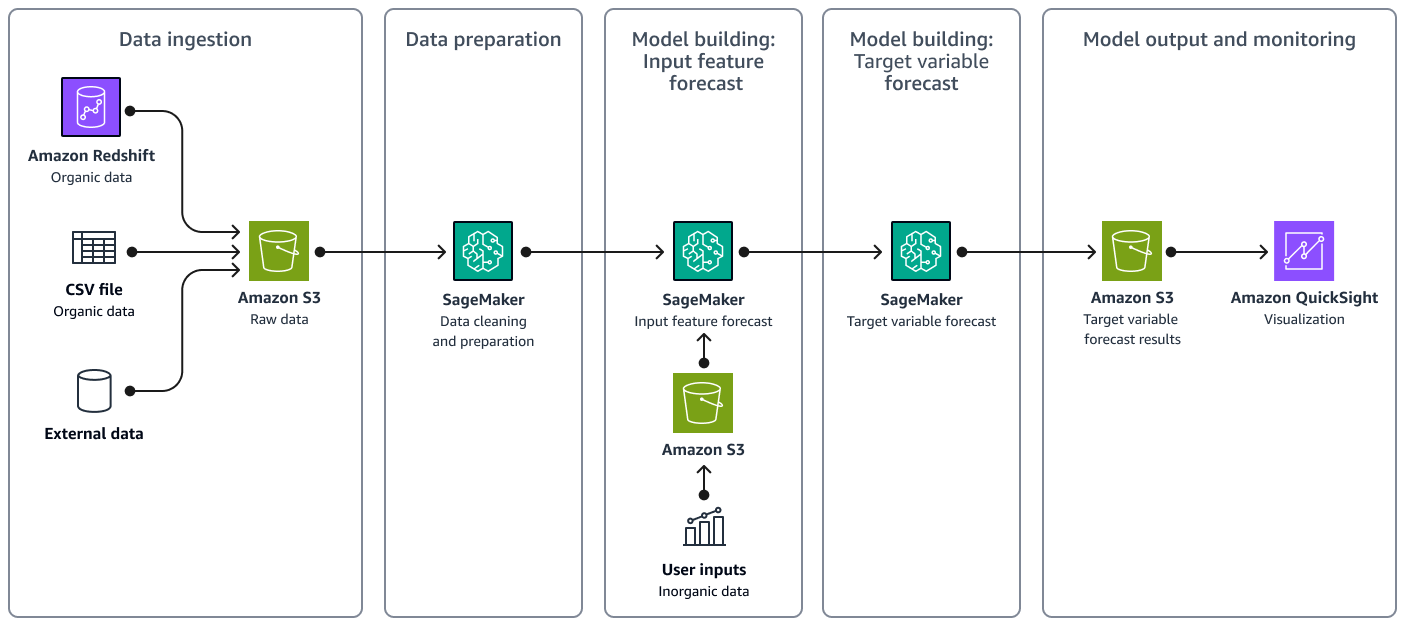
ソリューションアーキテクチャには、次の主要コンポーネントが含まれています。
-
データインジェスト – 有機データと外部データの両方を Amazon Simple Storage Service (Amazon S3) に保存します。
-
データ準備 – Amazon SageMaker AI はデータをクリーンアップし、ML モデルトレーニング用に準備します。詳細については、 SageMaker AI ドキュメントの「データの準備」を参照してください。
-
モデル構築: 入力機能予測 – SageMaker AI が を使用する Prophet
は、各入力機能の時系列予測を生成します。予測結果を調べます。必要に応じて、機能の予測を上書きするためのユーザー入力を指定します。 -
モデル構築: ターゲット変数予測 – SageMaker AI は、変更された入力機能を使用して推論用の回帰モデルを作成します。
-
モデル出力とモニタリング — 回帰モデルは予測結果を Amazon S3 に出力します。Amazon QuickSight で予測を視覚化できます。アナリストは、予測を実際の需要量と比較することで、予測結果をモニタリングし、精度を評価できます。
データインジェストから最終的なモデル出力までの処理パイプライン全体を、自動的に実行するように調整できます。例えば、毎月の需要予測に対して毎月自動的に実行するように設定できます。複数の製品の予測が必要な場合は、複数の製品に対してパイプラインを並行して実行できます。詳細については、 SageMaker AI ドキュメントの「実装MLOps」を参照してください。
