翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
での本番稼働対応 ML パイプラインの作成 AWS
Josiah Davis、Verdi March、Yin Song、Baichuan Sun、Chen Wu、および Wei Yih Yap、Amazon Web Services (AWS)
2021 年 1 月 (ドキュメント履歴)
機械学習 (ML) プロジェクトでは、ビジネス価値をもたらし、現実世界の問題を解決するために、モデリング、実装、制作を含む多段階にわたる多大な作業が必要です。各ステップには数多くの代替手段やカスタマイズオプションがあり、リソースと予算の制約の中で本番環境用の ML モデルを準備することがますます難しくなっています。Amazon Web Services (AWS) では、過去数年間、データサイエンスチームがさまざまな業界セクターと協力して ML イニシアチブに取り組んできました。組織的な問題と技術的な課題の両方から生じる、多くの AWS お客様が共有する問題点を特定し、本番環境に対応した ML ソリューションを提供するための最適なアプローチを開発しました。
このガイドは、ML パイプラインの実装に携わるデータサイエンティストと ML エンジニアを対象としています。本稼働環境に対応した ML パイプラインを提供するための当社のアプローチについて説明しています。このガイドでは、ML モデルをインタラクティブに ( 開発中に ) 実行することから、ML ユースケースのパイプラインの一部として ( 本番環境で ) デプロイする方法に移行する方法について説明します。この目的のために、カスタム ML ソリューションを本番環境に迅速に提供するためのサンプルテンプレート (「 ML Max プロジェクトプロジェクト
概要
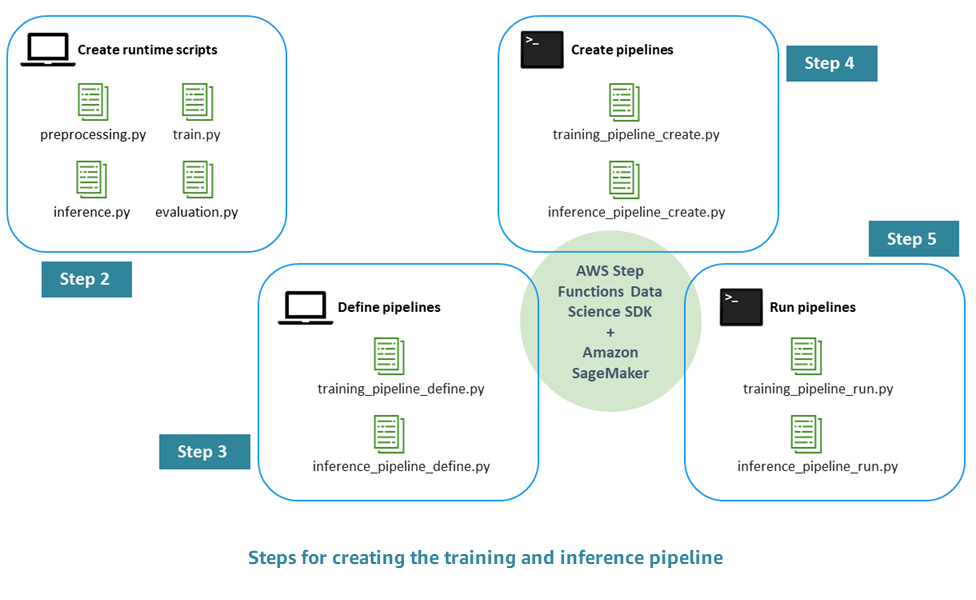
本番環境に対応した ML パイプラインを作成するプロセスは、以下のステップで構成されています。
-
ステップ 1。EDA の実行と初期モデルの開発 — データサイエンティストは、Amazon Simple Storage Service (Amazon S3) で生データを利用できるようにし、探索的データ分析 (EDA) を実行し、初期 ML モデルを開発して、その推論性能を評価します。これらのアクティビティは Jupyter Notebook を通じてインタラクティブに実行できます。
-
ステップ 2。ランタイムスクリプトの作成 – モデルをランタイム Python スクリプトと統合して、ML フレームワーク (この場合は Amazon SageMaker AI) で管理およびプロビジョニングできるようにします。これは、スタンドアロンモデルのインタラクティブな開発から本番環境に移行するための第一歩です。具体的には、前処理、評価、トレーニング、推論のロジックを個別に定義します。
-
ステップ 3。パイプラインの定義 — パイプラインの各ステップの入力と出力のプレースホルダーを定義します。これらの具体的な値は、後のランタイム (ステップ 5) に提供されます。トレーニング、推論、相互検証、バックテストのためのパイプラインに焦点を当てます。
-
ステップ 4。パイプラインの作成 – を使用して、自動 (ほぼワンクリック) 方式で AWS Step Functions ステートマシンインスタンスを含む基盤となるインフラストラクチャを作成します AWS CloudFormation。
-
ステップ 5。パイプラインの実行 — ステップ 4 で定義したパイプラインを実行します。また、ステップ 3 で定義した入出力プレースホルダーの具体的な値を入力するためのメタデータとデータまたはデータの場所を準備します。これには、ステップ 2 で定義したランタイムスクリプトとモデルのハイパーパラメータが含まれます。
-
ステップ 6。パイプラインの拡張 — 継続的インテグレーションと継続的デプロイ (CI/CD) プロセス、自動再トレーニング、スケジュールに基づく推論など、パイプラインの拡張を実装します。
次の図は、このプロセスの主な手順を示しています。