翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
サイロモデルマルチテナンシー
一部のマルチテナント SaaS 環境では、コンプライアンスと規制要件により、テナントのデータを完全に分離されたリソースにデプロイする必要がある場合があります。大規模なお客様は、ノイズの多い近隣への影響を軽減するために専用クラスターを必要とする場合があります。このような状況では、サイロモデルを適用できます。
サイロモデルでは、テナントデータのストレージは他のテナントデータから完全に分離されます。テナントのデータを表すために使用されるすべてのコンストラクトは、そのクライアントに物理的に一意であると見なされます。つまり、各テナントには通常、個別のストレージ、モニタリング、管理があります。各テナントには、暗号化用の個別の AWS Key Management Service (AWS KMS) キーもあります。Amazon Neptune では、サイロはテナントごとに 1 つのクラスターです。
テナントあたりのクラスター
クラスターごとに 1 つのテナントを持つことで、Neptune でサイロモデルを実装できます。次の図は、仮想プライベートクラウド (VPC) 内のアプリケーションマイクロサービスにアクセスする 3 つのテナントと、テナントごとに個別のクラスターを示しています。
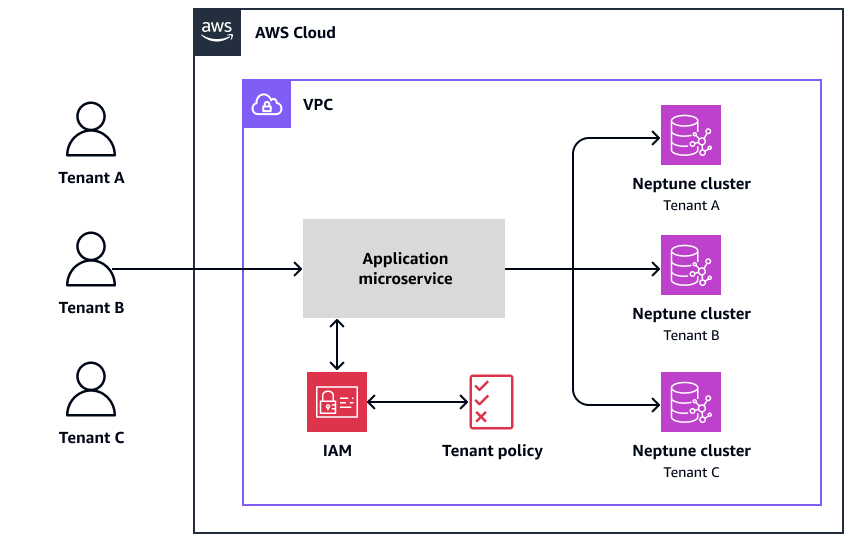
各クラスターには、効率的なデータインタラクションと管理のために個別のアクセスポイントを確保するのに役立つ個別のエンドポイントがあります。各テナントを独自のクラスターに配置することで、テナント間に明確に定義された境界を作成し、データが他のテナントのデータから正常に分離されるようにします。この分離は、厳格な規制とセキュリティの制約がある SaaS ソリューションにも魅力的です。さらに、各テナントに独自のクラスターがある場合、ノイズの多い近隣について心配する必要はありません。あるテナントが負荷を課し、他のテナントのエクスペリエンスに悪影響を及ぼす可能性があります。
テナントcluster-per-tenantサイロモデルには利点がありますが、管理と俊敏性の課題も生じます。このモデルの分散性により、テナントアクティビティとすべてのテナントの運用状態を集約して評価することが困難になります。新しいテナントをセットアップするには別のクラスターのプロビジョニングが必要になるようになったため、デプロイも難しくなります。クライアントのアップグレードとバージョンがデータベースのアップグレードと緊密に結合されている場合、クライアントレイヤーが共有されている環境ではアップグレードがより困難になります。
Neptune は、サーバーレスクラスターとプロビジョニングされたクラスターの両方をサポートしています。アプリケーションワークロードがサーバーレスインスタンスまたはプロビジョニングされたインスタンスによってより適切に処理されているかどうかを評価します。一般的に、ワークロードの需要が一定である場合、プロビジョニングされたインスタンスはコスト効率が高くなります。サーバーレスは、要求の厳しい可変性の高いワークロードに最適化されており、データベースの使用量が短時間多くなると、軽いアクティビティが長時間続くか、アクティビティがない状態になります。
テナントごとに Neptune でプロビジョニングされたクラスターを使用する場合は、テナントの需要の最大負荷に近似するインスタンスサイズを選択する必要があります。このサーバーへの依存は、SaaS 環境のスケーリング効率とコストにもカスケード的に影響します。SaaS の目標は実際のテナント負荷に基づいて動的にサイズ設定することですが、Neptune プロビジョニングクラスターでは、使用量の多さと負荷の急増を考慮して過剰プロビジョニングする必要があります。オーバープロビジョニングにより、テナントあたりのコストが増加します。さらに、テナントの使用状況が時間の経過とともに変化するにつれて、クラスターのスケールアップまたはスケールダウンをテナントごとに個別に適用する必要があります。
Neptune チームは通常、アイドル状態のリソースによって発生するコストが高くなり、運用が複雑になるため、サイロモデルに対してアドバイスします。ただし、規制の厳しいワークロードや機密性の高いワークロードでは、この追加の分離が必要になるため、お客様は追加料金を支払うことができます。
サイロモデルの実装ガイダンス
テナントcluster-per-tenantサイロ分離モデルを実装するには、 AWS Identity and Access Management (IAM) データアクセスポリシーを作成します。これらのポリシーは、テナントが独自のデータを含む Neptune クラスターにのみアクセスできるようにすることで、テナントの Neptune クラスターへのアクセスを制御します。各テナントの IAM ポリシーを IAM ロールにアタッチします。次に、アプリケーションマイクロサービスは IAM ロールを使用して、 AWS Security Token Service () の AssumeRoleメソッドを使用してきめ細かな一時的な認証情報を生成しますAWS STS。これらの認証情報は、そのテナントの Neptune クラスターにのみアクセスでき、テナントの Neptune クラスターへの接続に使用されます。
次のコードスニペットは、データベースの IAM ポリシーのサンプルを示しています。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "neptune-db:ReadDataViaQuery", "neptune-db:WriteDataViaQuery" ], "Resource": "arn:aws:neptune-db:us-east-1:123456789012:tenant-1-cluster/*", "Condition": { "ArnEquals": { "aws:PrincipalArn": "arn:aws:iam::123456789012:role/tenant-role-1" } } } ] }
このコードは、サンプルテナントである にtenant-1、それぞれの Neptune クラスターへの読み取りおよび書き込みクエリアクセスを提供します。Condition 要素により、IAM ロール () tentant-1 を引き受けた呼び出し元のエンティティ (プリンシパルtenant-role-1) のみが tenant-1の Neptune クラスターにアクセスできるようになります。
