翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Athena でのML 予測のため、Amazon DynamoDB 内のデータを集約
作成者:Sachin Doshi (AWS) と Peter Molnar (AWS)
概要
このパターンは、Amazon Athena で Amazon DynamoDB テーブル内のモノのインターネット (IoT) データの複雑な集約を構築する方法を示しています。また、Amazon SageMaker AI を使用して機械学習 (ML) 推論でデータを強化する方法と、Athena を使用して地理空間データをクエリする方法についても説明します。このパターンは、組織の要件を満たす ML 予測ソリューションを作成するための基礎として使用できます。
デモの目的で、このパターンでは、スクーターシェアリングを運営する企業が、さまざまな都市部の顧客に展開しなければならない最適なスクーターの台数を予測したいと考えているシナリオを例に挙げています。この企業では、過去 4 時間に基づき、次の 1 時間の顧客需要を予測する、事前にトレーニングされた ML モデルを使用しています。このシナリオでは、「ルイビル市市民イノベーション技術局
前提条件と制限
アクティブな AWS アカウント
以下の AWS Identity and Access Management (IAM) ロールを使用して AWS CloudFormation スタックを作成するアクセス許可。
Amazon Simple Storage Service (Amazon S3) バケット
Athena
DynamoDB
SageMaker AI
AWS Lambda
アーキテクチャ
テクノロジースタック
Amazon QuickSight
Amazon S3
Athena
DynamoDB
Lambda
SageMaker AI
ターゲット アーキテクチャ
次の図は、Athena、Lambda 関数、Amazon S3 ストレージ、SageMaker AI エンドポイント、QuickSight ダッシュボードのクエリ機能を使用して、DynamoDB でデータの複雑な集約を構築するためのアーキテクチャを示しています。
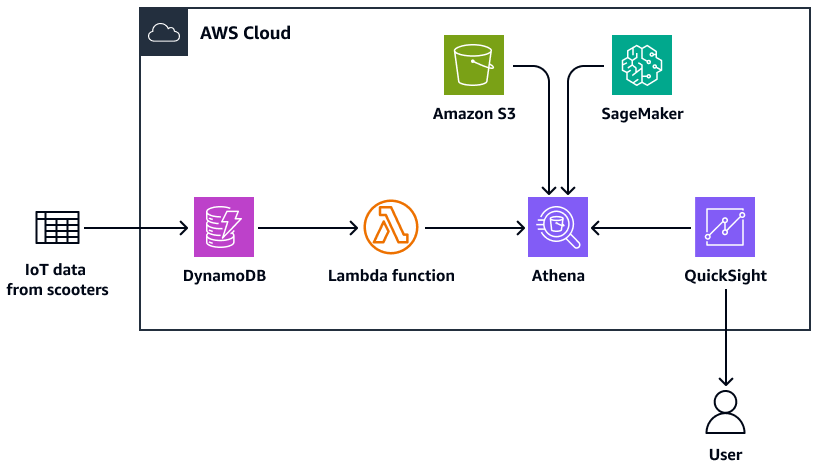
この図表は、次のワークフローを示しています:
DynamoDB テーブルは、複数のスクーターから送信される IoT データを取り込みます。
Lambda 関数は、取り込まれたデータを DynamoDB テーブルにロードします。
Athena クエリは、都市部を表す地理空間データ用の新しい DynamoDB テーブルを作成します。
クエリの位置は S3 バケットに保存されます。
Athena 関数は、事前トレーニング済みの ML モデルをホストする SageMaker AI エンドポイントから ML 推論をクエリします。
Athena は DynamoDB テーブルから直接データをクエリし、データを統合して分析します。
ユーザーは、分析されたデータの出力を QuickSight ダッシュボードに閲覧できます。
ツール
AWS のサービス
「Amazon Athena」標準 SQL を使用して Amazon S3 内のデータを直接分析するのに役立つインタラクティブなクエリサービスです。
Amazon DynamoDB は、フルマネージド NoSQL データベースサービスです。高速かつ予測可能でスケーラブルなパフォーマンスを発揮します。
Amazon SageMaker AI は、ML モデルを構築してトレーニングし、本番環境に対応したホスト環境にデプロイするのに役立つマネージド ML サービスです。
Amazon Simple Storage Service (Amazon S3) は、どのようなデータ量であっても、データを保存、保護、取得することを支援するクラウドベースのオブジェクトストレージサービスです。
「Amazon QuickSight」は、クラウドスケールのビジネスインテリジェンス (BI) サービスで、データを単一のダッシュボードで可視化、分析、レポートすることができます。
AWS Lambda は、サーバーのプロビジョニングや管理を行うことなくコードを実行できるコンピューティングサービスです。必要に応じてコードを実行し、自動的にスケーリングするため、課金は実際に使用したコンピューティング時間に対してのみ発生します。
コードリポジトリ
このパターンのコードは、 GitHub 内の「Amazon Athena ML で Amazon DynamoDB データに対する ML 予測を使用
DynamoDB テーブル。
テーブルに関連データをロードする Lambda 関数
Amazon S3 に保存されている事前トレーニング済み XGBoost モデルを使用した、推論リクエスト用の SageMaker Amazon S3エンドポイント XGBoost
V2EngineWorkGroupという Athena ワークグループ名前付きの Athena クエリで地理空間シェープファイルを検索し、スクーターの需要を予測します。
Amazon Athena DynamoDB Athena DynamoDB コネクタ DynamoDB AWS Serverless Application ModelAWS SAM
エピック
| タスク | 説明 | 必要なスキル |
|---|---|---|
データセットとリソースをダウンロードします。 |
| アプリ開発者、データサイエンティスト |
| タスク | 説明 | 必要なスキル |
|---|---|---|
CloudFormation スタックを作成します。 |
注記CloudFormation スタックがこれらのリソースを作成するまでに 15~20 分かかる場合があります。 | AWS DevOps |
CloudFormation のデプロイを確認します。 | CloudFormation テンプレートからのサンプルデータが DynamoDB にロードされたことを確認するには、次の操作を実行します。
| アプリ開発者 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
Athena テーブルを地理空間データにより作成します。 | Athena に位置情報ファイルを読み込むには、次の操作を実行します。
このクエリは、都市部を表す地理空間データ用の新しいテーブルを作成します。データテーブルは GIS シェープファイルから作成されます。 シェープファイルを処理し、このテーブルを生成する Python コードについては、 AWS 「サンプル」の「Geo-Spatial processing of GIS shapefiles with Amazon Athena | データエンジニア |
| タスク | 説明 | 必要なスキル |
|---|---|---|
Athena で関数を宣言して SageMaker AI をクエリします。 |
| データサイエンティスト、データエンジニア |
集約された DynamoDB データから地域別のスクーターの需要を予測します。 | これで、Athena により、DynamoDB から直接トランザクションデータをクエリし、データを集約して分析と予測を行うことができます。これは、DynamoDB NoSQL データベースに直接クエリを実行しても簡単には実現できません。
SQL ステートメントは次のことを行います。
SQL を使用して Athena で DynamoDB データおよび SageMaker AI 推論データを集約する方法については、GitHub の「athena_long.sql | アプリ開発者、データサイエンティスト |
出力の検証 | 出力テーブルには、近傍と近傍の重心の経度と緯度を含んでいます。また、次の 1 時間に予測される車両の数も含んでいます。 このクエリでは、選択した時点の予測が生成されます。ステートメントのあらゆる箇所で DynamoDB テーブルにリアルタイムデータフィードがある場合は、タイムスタンプを | アプリ開発者、データサイエンティスト |
| タスク | 説明 | 必要なスキル |
|---|---|---|
リソースの削除 |
| アプリ開発者、AWS DevOps |
関連リソース
「Amazon Athena クエリフェデレーション SDK
」(GitHub) 地理空間データのクエリ (AWS ドキュメント)
Amazon Athena ML で Amazon DynamoDB データに対する ML 予測 Amazon Athena
を使用する (AWS ビッグデータブログ) Amazon ElastiCache (Redis OSS)
(AWS ドキュメント) Amazon Neptune
(AWS ドキュメント)
